Deep Learning – Speech Enhancement
Leveraging Non-Causal Knowledge via Cross-Network Knowledge Distillation for Real-Time Speech Enhancement
Objective
Speech enhancement (SE) is the task of removing background noises to obtain a high quality of clean speech. To enhance real-time speech enhancement (SE) while maintaining efficiency, we propose cross-network non-causal knowledge distillation (CNNC-Distill). CNNC-Distill enables knowledge transfer from a non-causal teacher model to a real-time SE student model using feature and output distillation.
Data
We use the VoiceBank-DEMAND dataset [1] which is made by mixing the VoiceBank Corpus and DEMAND noise dataset.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
Related Work
MANNER [2] is a strong SE model can be used for teacher network.
MV-AT [3] proved the importance of feature distillation in SE.

[3] Shin, Wooseok, et al. “Multi-view attention transfer for efficient speech enhancement.” arXiv preprint arXiv:2208.10367 (2022).
Proposed Method
RT-SENet is a lightweight SE network designed for real-time speech enhancement, modified from the MANNER network with causal multi-view attention. CNNC-Distill is a knowledge distillation method that transfers knowledge from a high-performing teacher network to a real-time SE student network. By leveraging feature similarity, it enables effective knowledge transfer under cross-network conditions.
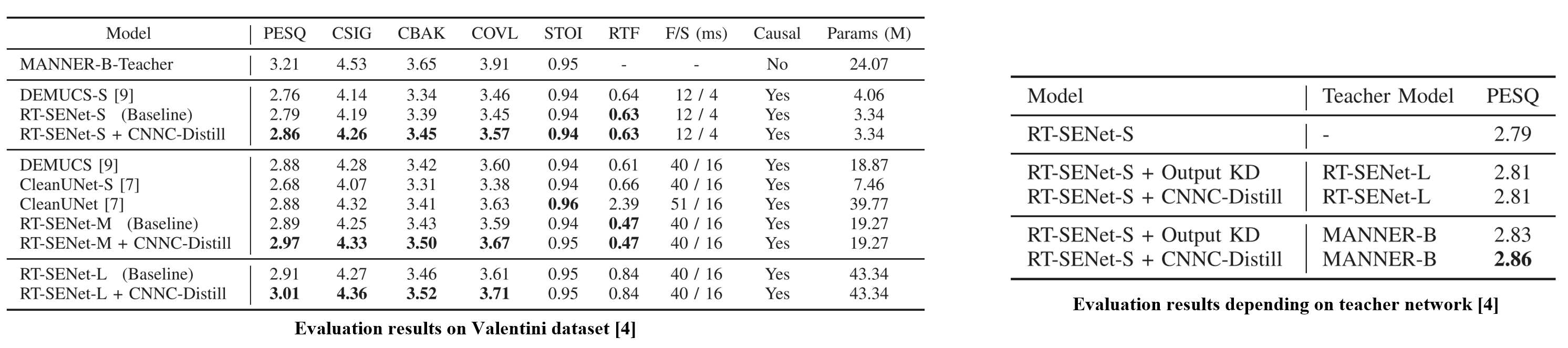
The results (left) show that RT-SENet-(S and M) outperform existing methods in both SE and real-time performance. CNNC-Distill improves SE performance in RT-SENets without affecting real-time operation, with larger models benefiting more from KD. Notably, RT-SENet-S with CNNC-Distill achieves comparable performance to DEMUCS while using significantly fewer inputs and parameters, demonstrating its efficiency.
Real-time SE models are typically simpler, limiting knowledge transfer when using the same network type for KD. Table (right) shows that using a strong non-causal teacher (MANNER-B) outperforms a real-time teacher (RT-SENet-L), maximizing the KD effect. Additionally, CNNC-Distill proves more effective than output KD in cross-network settings, demonstrating its ability to transfer knowledge efficiently.
In‑Vehicle Environment Noise Speech Enhancement Using Lightweight Wave‑U‑Net
Objective
Speech enhancement (SE) is the task of removing background noises to obtain a high quality of clean speech. A potential domain for SE applications is noise removal in in-vehicle environments. To develop the SE model suitable for such environments, we constructed a vehicle noise dataset and trained a lightweight SE network.
Data
We use the custom in-vehicle noise dataset gathered by Hyundai NVH and the custom speech dataset gathered by BRFrame with crowdsourcing.
Related Work
Wave-U-Net [1] is a U-Net based speech enhancement method.
SE-Net [2] is a module that efficiently enhances feature representations.
[2] Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Proposed Method
To construct a dataset for in-vehicle noise removal tasks, we collected in-vehicle noise data under various driving conditions. This noise data was then synthesized with speech data for SE model training.
The proposed method is designed as a lightweight model for in-vehicle usage. We introduce a depth-wise separable convolution-based block within a U-Net-based architecture to process information more efficiently.
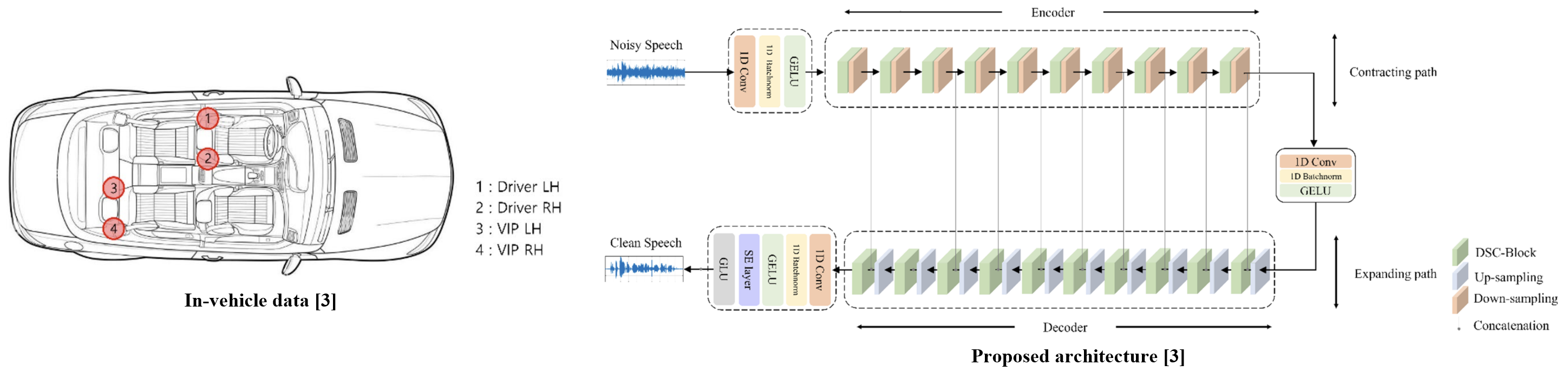
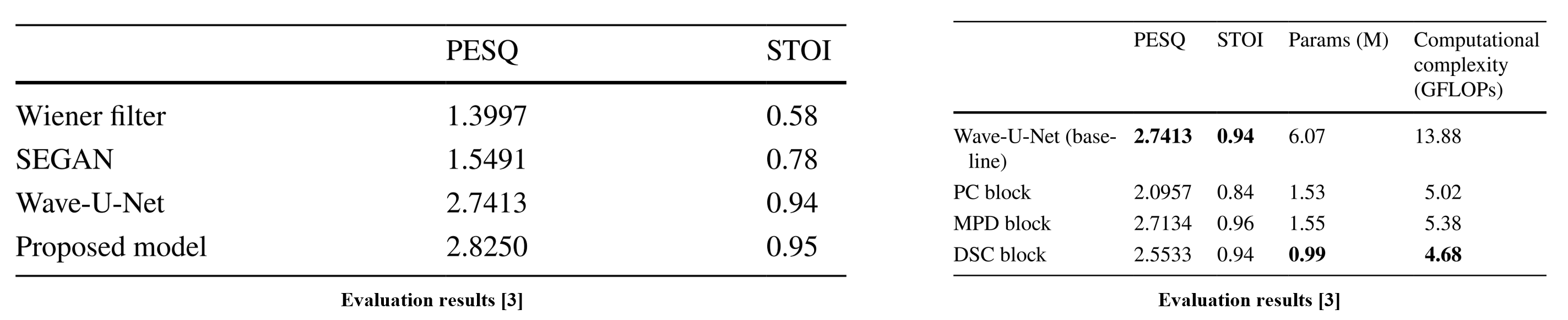
The proposed method achieves higher SE performance than existing approaches. Considering real-time in-vehicle usage, the proposed depth-wise separable convolution-based block demonstrated the most efficient performance in terms of computational efficiency.
MetricGAN-OKD: Multi-Metric Optimization of MetricGAN via Online Knowledge Distillation for Speech Enhancement
Objective
Speech enhancement (SE) involves the improvement of the intelligibility and perceptual quality of human speech in noisy environments. Although recent deep learning-based models have significantly improved SE performance, dissonance continues to exist between the evaluation metrics and the L1 or L2 losses, typically used as the objective function.
To overcome the problems, MetricGAN, which is a GAN-based architecture that utilizes non-differentiable evaluation metrics as objective functions with efficient cost, was proposed. Subsequently, optimization of multiple metrics to improve different metrics representing various aspects of human auditory perception has been attempted.
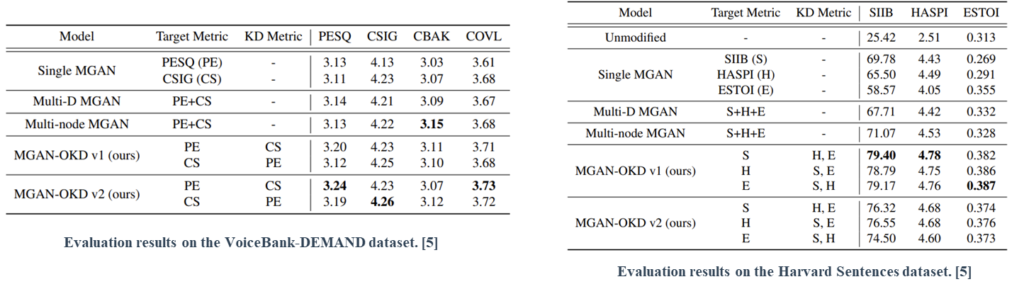
Although these studies have demonstrated the potential of multi-metric optimization, simultaneous performance improvements are still limited. Therefore, we propose an effective multi-metric optimization method for MetricGAN via online knowledge distillation (MetricGAN-OKD) to improve the performance in terms of all target metrics.
Data
We use the VoiceBank-DEMAND [1] and Harvard Sentences [2] datasets.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
[2] Rothauser, E., “Ieee recommended practice for speech quality measurements”. 1969.
Related Work
MetricGAN is a GAN-based architecture that utilizes non-differentiable evaluation metrics as objective functions with efficient cost.
MetricGAN consists of a surrogate function (discriminator) that learns the behavior of the metric function and a generator that generates enhanced speech based on the guidance of the discriminator.
Online knowledge distillation (OKD), a practical variant of KD, performs mutual learning among student models during the training phase, instead of a one-sided knowledge transfer from a pre-trained teacher network to a student network.
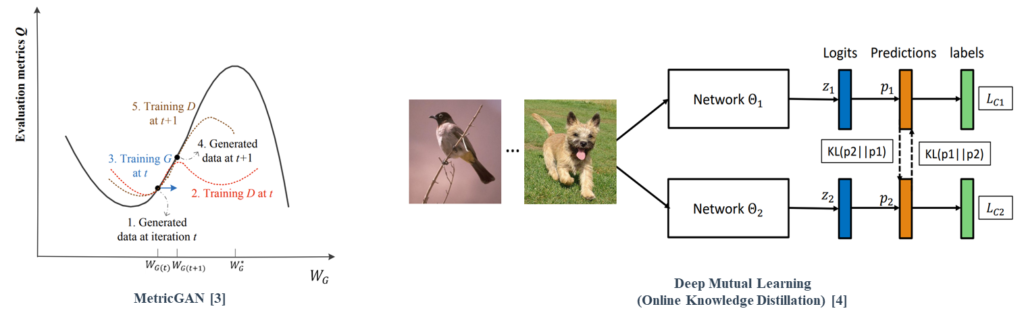
[4] Zhang, Y., et al., “Deep mutual learning”, 2018.
Proposed Method
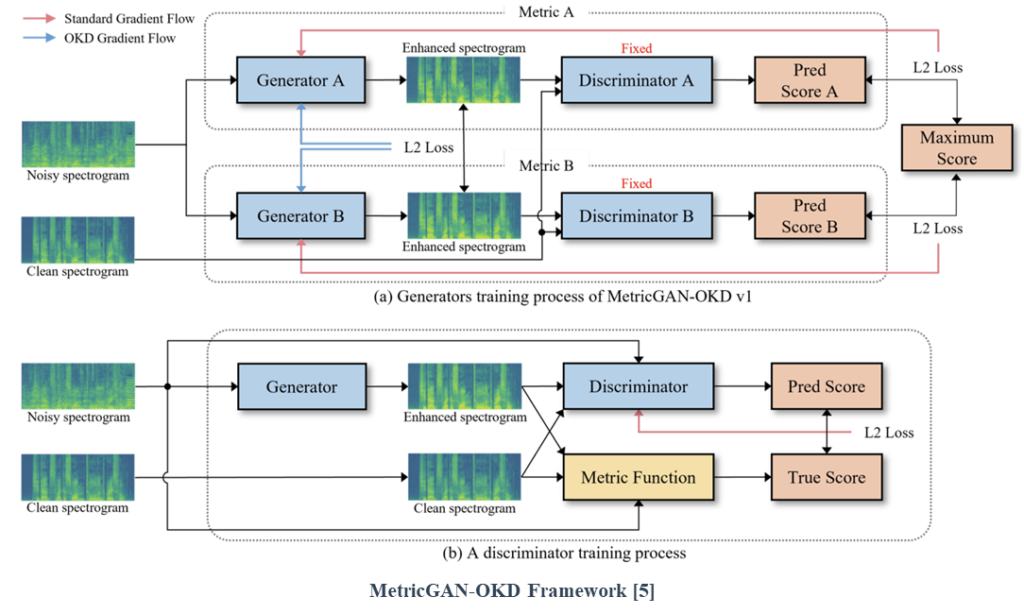
We propose an effective multi-metric optimization method for MetricGAN via online knowledge distillation (MetricGAN-OKD). To mitigate confusing gradient directions, we design a special OKD learning scheme, which consists of a one-to-one correspondence between generators and target metrics. In particular, each generator learns from the gradient of each discriminator trained using a single target metric for stability. Subsequently, other metrics are improved by transferring knowledge of other generators trained on different metrics to the target generator.
This strategy enables stable multi-metric optimization, where the generator learns the target metric from a single discriminator easily and improves multiple metrics by mimicking other generators.
Extensive experiments on SE and LE tasks reveal that the proposed MetricGAN-OKD outperforms existing single- and multi-metric optimization methods significantly.
Besides quantitative evaluation, we explain the success of MetricGAN-OKD in terms of high network generalizability and the correlation between different metrics.
Multi-View Attention Transfer for Efficient Speech Enhancement
Objective
Speech enhancement (SE) involves the removal of background noise to improve the perceptual quality of noisy speech. Although deel learning-based methods have achieved significant improvements in SE, the problem remains that they do not simultaneously satisfy the low computational complexity and model complexity required in various deployment environments while minimizing performance degradation. We propose multi-view attention transfer (MV-AT) to obtain efficient speech enhancement models.
Data
We use the VoiceBank-DEMAND [1] and Deep Noise Suppression (DNS) [2] datasets.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
[2] C. K. Reddy et al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results”, 2020.
Related Work
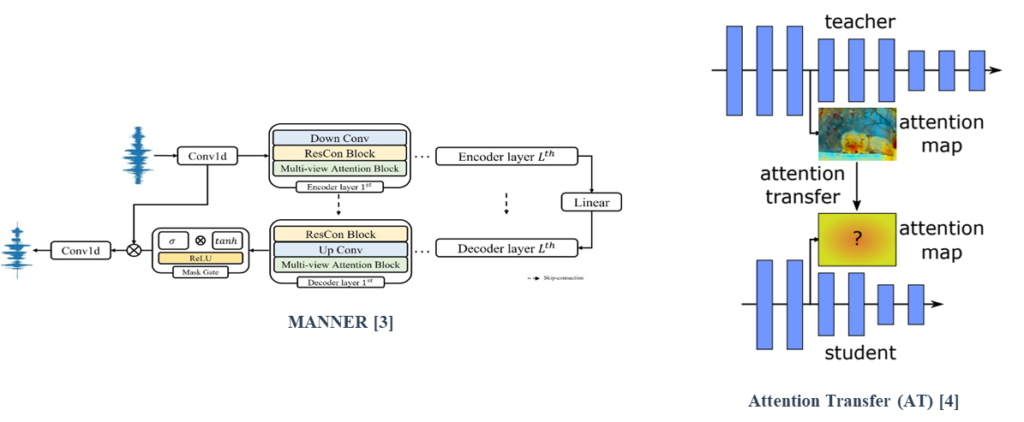
MANNER is composed of a multi-view attention (MA) block which efficiently extracts speech’s channel and long sequential features from each view.
Attention transfer (AT), a feature-based distillation, transfers knowledge using attention maps of features.
[4] Zagoruyko, S. and Komodakis, N. “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer”, 2016.
Proposed Method
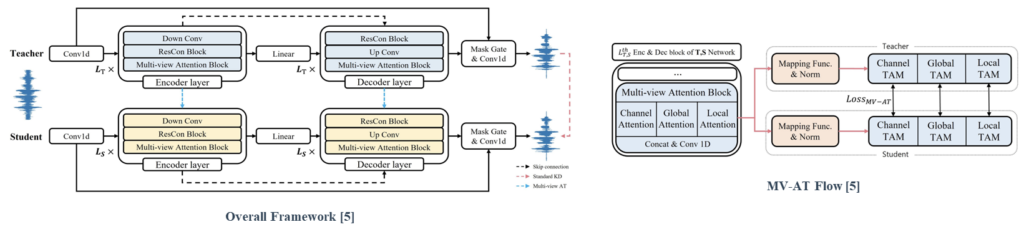
MV-AT based on the MANNER backbone transfers the feature-wise knowledge of the teacher by utilizing each feature highlighted in the multiview.
By applying MV-AT, the student network can easily learn the teacher’s signal representation and mimic the matched representation from each perspective. MV-AT can not only compensate for the limitation of standard KD in SE as feature-based distillation but also make an efficient SE model without additional parameters.
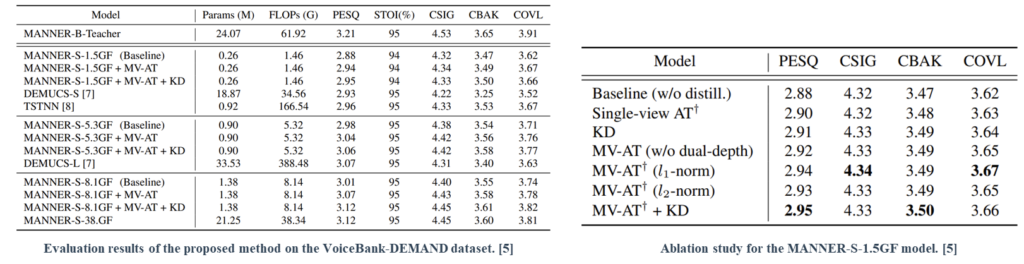
The results of experiments conducted on the Valentini and DNS datasets indicate that the proposed method achieves significant efficiency. While exhibiting comparable performance to the baseline model, the model generated by the proposed method required 15.4× and 4.71× fewer parameters and flops, respectively.
To investigate the effects of different components on the performance of the proposed method, we performed an ablation study over MV-AT and standard KD.
MANNER: Multi-view Attention Network for Noise ERasure
Objective
Speech enhancement (SE) is the task of removing background noises to obtain a high quality of clean speech. Previous studies on speech enhancement tasks have difficulties in achieving both high performance and efficiency, which is caused by the lack of efficiency in extracting the speech’s long sequential features. We propose a U-net-based MANNER composed of a multi-view attention (MA) block which efficiently extracts speech’s channel and long sequential features from each view.
Data
We use the VoiceBank-DEMAND dataset [1] which is made by mixing the VoiceBank Corpus and DEMAND noise dataset.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
Related Work
Denoiser adopted the U-net architecture and exploited LSTM layers in the bottleneck.
TSTNN suggested a dual-path method to extract long signal information.
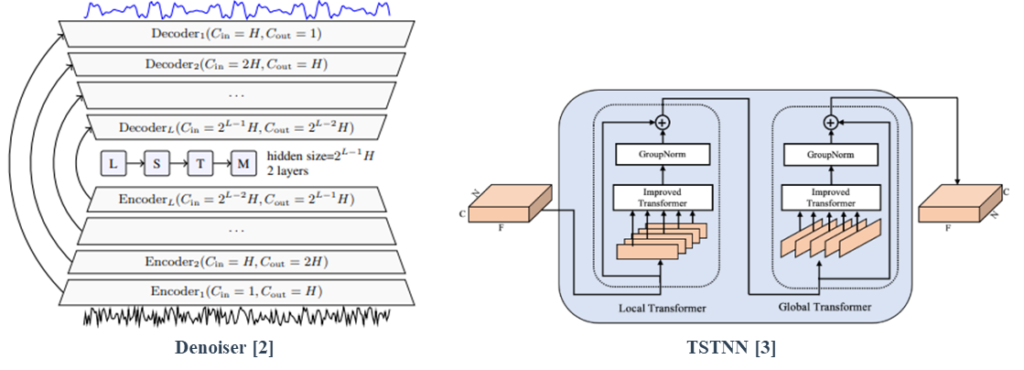
[3] K.Wang, B.He, and W.-P.Zhu, “Tstnn: Two-stage transformer based neural network for speech enhancement in the time domain,” in ICASSP. IEEE, 2021, pp. 7098– 7102
Proposed Method
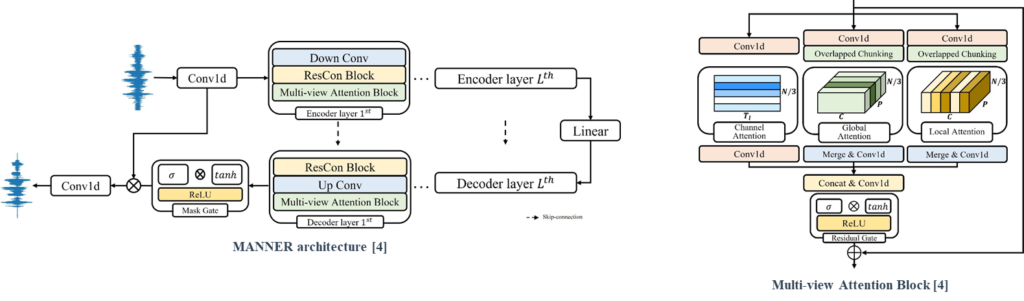
MANNER is based on U-net and each encoder and decoder consists of Lth encoder and decoder layers, respectively. Each layer is composed Down or Up convolution layer, a Residual Conformer block, and a Multi-view Attention block. Furthermore, we adopt a residual connection between encoder and decoder layers.
To represent all the speech information, the Multi-view Attention block processes the data into three attention paths, channel, global, and local attention. Channel attention emphasizes channel representations and Global and Local attention based on dual-path processing efficiently extracts long sequential features.
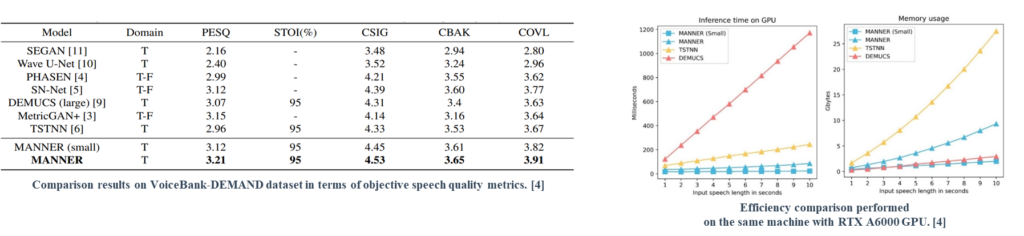
MANNER achieved state-of-the-art performance with a significant improvement compared to the previous methods in terms of five objective speech quality metrics. Although MANNER (small)’s performance decreases, it outperformed the previous methods in terms of performance and efficiency.
Unlike many existing models, which tend to suffer from some combination of poor performance, slow speed, or high memory usage, MANNER provides competitive results in all of these regards, allowing for more efficient speech enhancement without compromising quality.