Deep Learning – Image Segmentation
PrevMatch: Revisiting and Maximizing Temporal Knowledge in Semi-supervised Semantic Segmentation
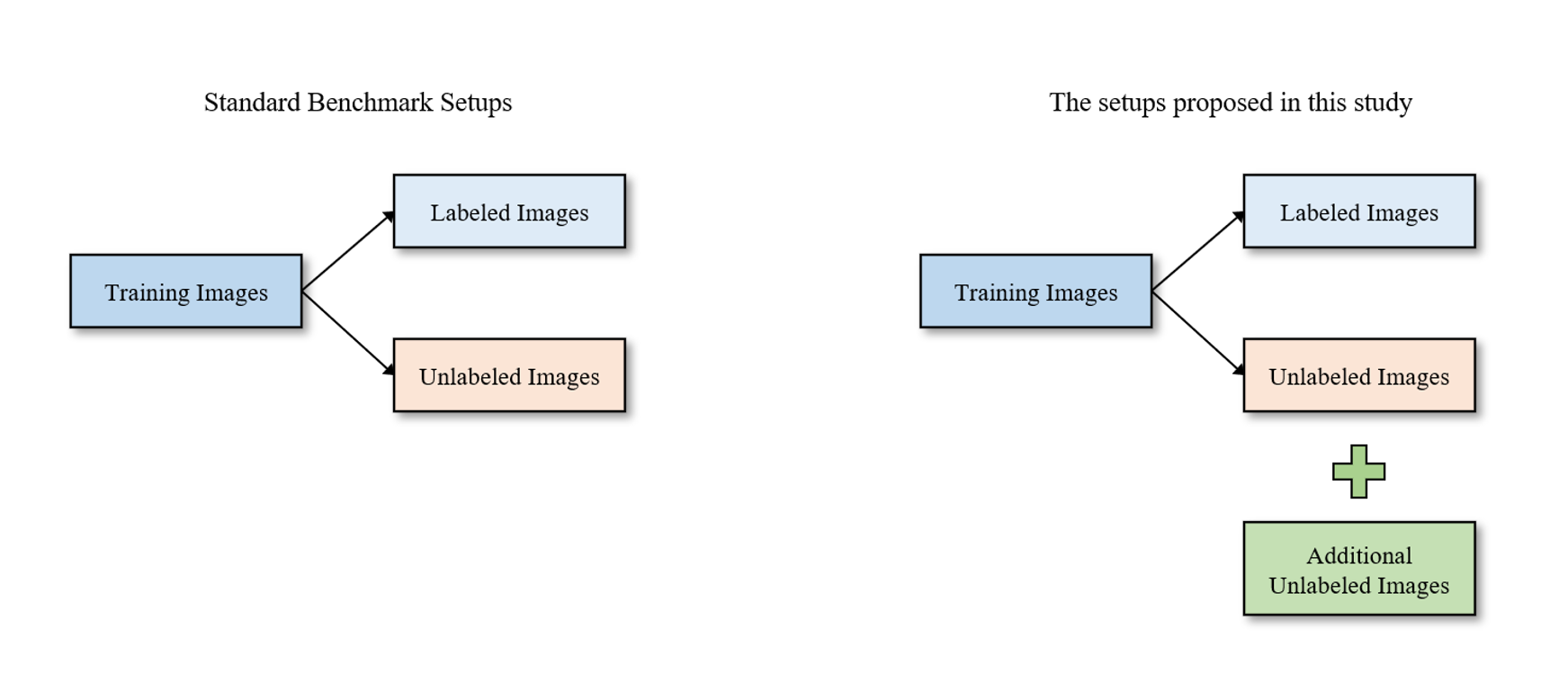
Objective
In semi-supervised semantic segmentation, the Mean Teacher- and co-training-based approaches are employed to mitigate confirmation bias and coupling problems. However, despite their high performance, these approaches frequently involve complex training pipelines and a substantial computational burden, limiting the scalability and compatibility of these methods. In this paper, we propose a PrevMatch framework that effectively mitigates the aforementioned limitations by maximizing the utilization of the temporal knowledge obtained during the training process.
Data
We use the Pascal-VOC [1], Cityscapes [2] , COCO [3], and ADE20K [4] datasets.
[1] M. Everingham et al., “The pascal visual object classes (voc) challenge”, 2010.
[2] M. Cordts et al., “The cityscapes dataset for semantic urban scene understanding”, 2016.
[3] T.-Y. Lin et al., “Microsoft coco: Common objects in context”, 2014.
[4] B. Zhou et al., “Scene parsing through ade20k dataset,”, 2017
Related Work
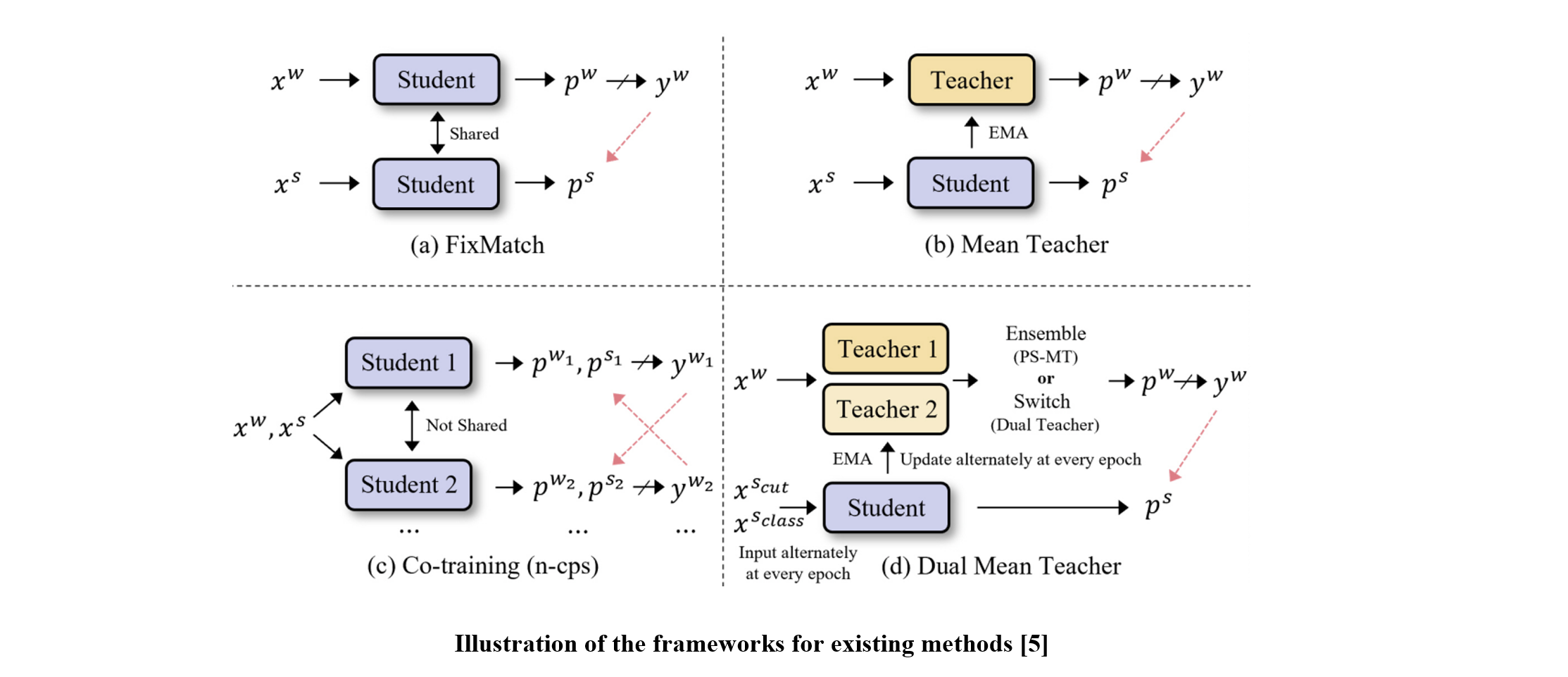
PS-MT and Dual Teacher methods implement a dual EMA teacher-based framework to mitigate the coupling problem between the teacher and student models, with two teachers alternately updating each epoch based on the EMA of the student’s weights.
Co-training approaches provide diverse pseudo-label guidance with stability and without concerns regarding the coupling problem.
Proposed Method
We propose the PrevMatch framework, which efficiently expands pseudo-label views by maximizing the utilization of previous models obtained during training. The PrevMatch framework is based on two main ideas. First, to efficiently address the coupling problem, we revisit the utilization of temporal knowledge. Specifically, we save several models at specific epochs during training and utilize their predictions as additional guidance, referred to as previous guidance, which acts as a regularizer in conjunction with standard guidance. Second, we design a highly randomized ensemble strategy to maximize the effectiveness of utilizing the previous guidance. This approach involves selecting a random number of models from those previously saved and ensembling their predictions using randomized weights. These strategies can efficiently provide diverse and reliable pseudo-labels while avoiding the complexities inherent in dual EMA and co-training-based approaches.
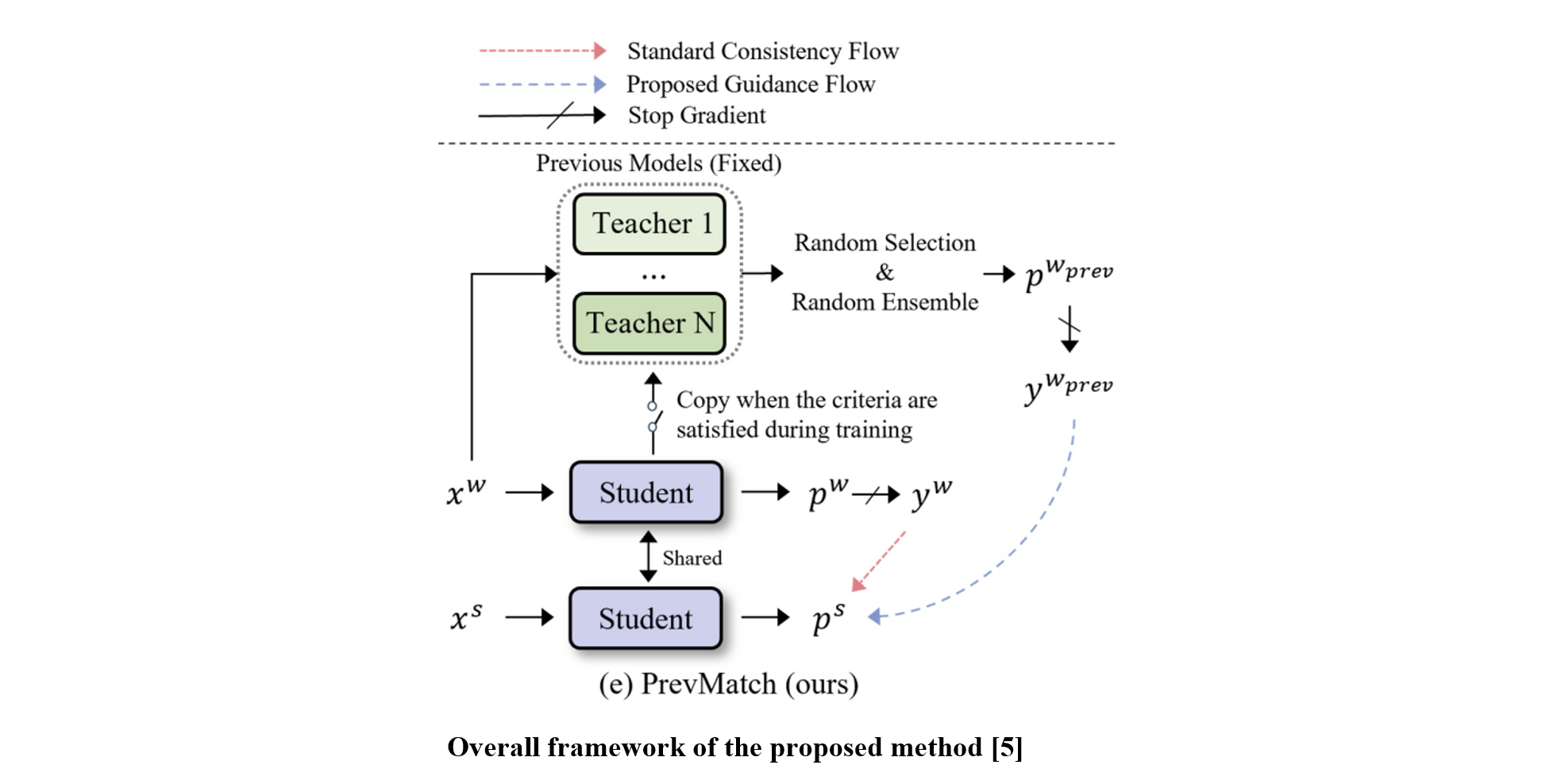
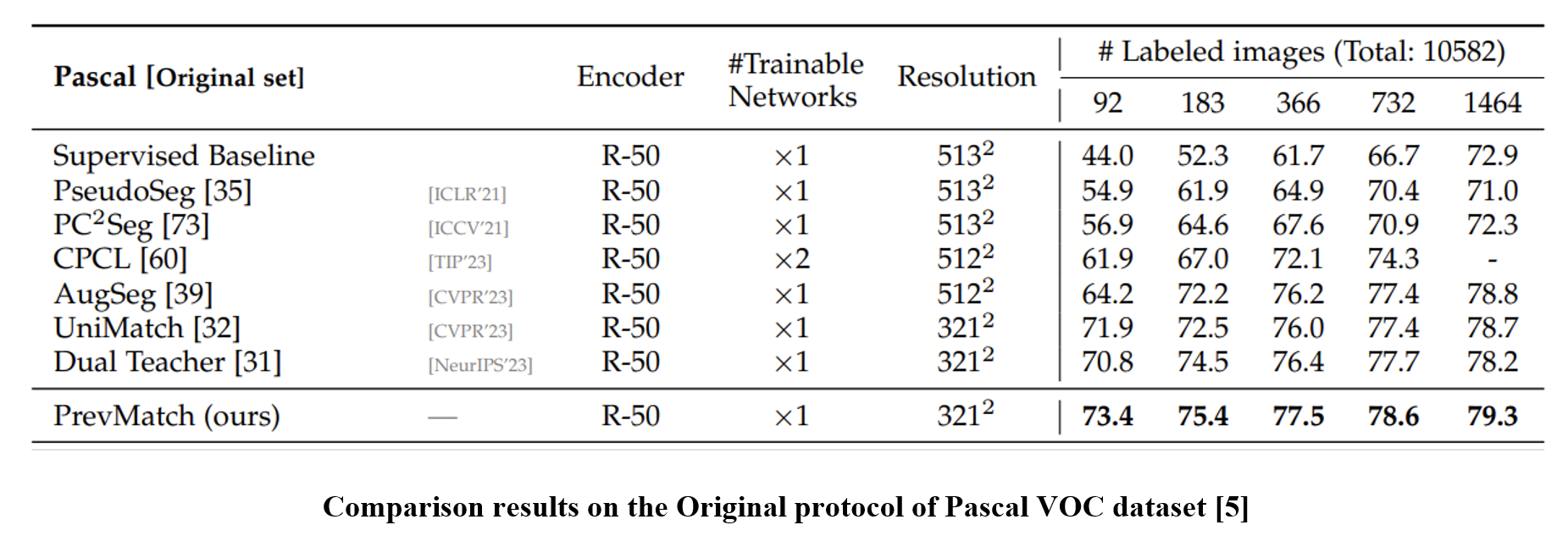
Extensive experiments conducted across various evaluation protocols on the PASCAL, Cityscapes, COCO, and ADE20K datasets reveal that the proposed PrevMatch significantly outperforms existing methods.
Leveraging Out-of-Distribution Unlabeled Images: Semi-Supervised Semantic Segmentation with an Open-Vocabulary Model
Objective
In semi-supervised semantic segmentation, existing studies have shown promising results in academic settings with controlled splits of benchmark datasets. However, the potential benefits of leveraging significantly larger sets of unlabeled images remain unexplored. In real-world scenarios, abundant unlabeled images are often available from online sources (web-scraped images) or large-scale datasets. However, these images may have different distributions from those of the target dataset, a situation known as out-of-distribution (OOD). Using these images as unlabeled data in semi-supervised learning can lead to inaccurate pseudo-labels, potentially misguiding network training.
Data
We use the Pascal VOC [1], Pascal Context [2], and COCO [3] datasets.
[1] M. Everingham et al., “The pascal visual object classes (voc) challenge”, 2010.
[2] R. Mottaghi et al., “The role of context for object detection and semantic segmentation in the wild”, 2014.
[3] T.-Y. Lin et al., “Microsoft coco: Common objects in context”, 2014.
Related Work
Existing semi-supervised semantic segmentation studies have shown promising results in academic settings where benchmark datasets are split into various setups based on different proportions or numbers of labeled and unlabeled images. However, there has been little exploration of the potential benefits of leveraging more unlabeled images.
Proposed Method
We propose a new semi-supervised segmentation framework with an open-vocabulary segmentation model (SemiOVS) to effectively utilize unlabeled OOD images. we integrate an open-vocabulary segmentation model into the existing semi-supervised learning process. In particular, the OVS model generates pseudo-labels for OOD images. Then, the standard segmentation model uses these pseudo-labels to learn OOD objects. This strategy provides the standard segmentation model with reliable guidance for OOD images, expanding its understanding to objects and scenes beyond the in-distribution data.
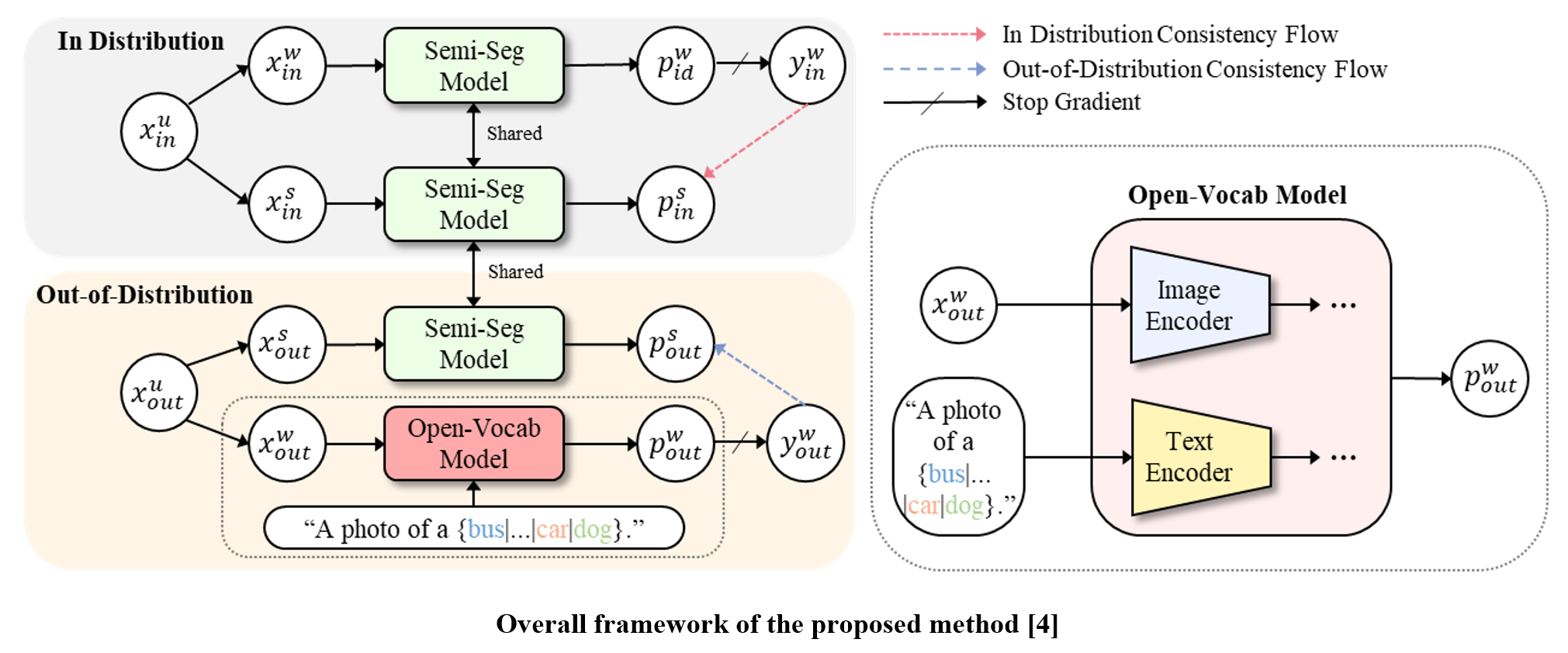
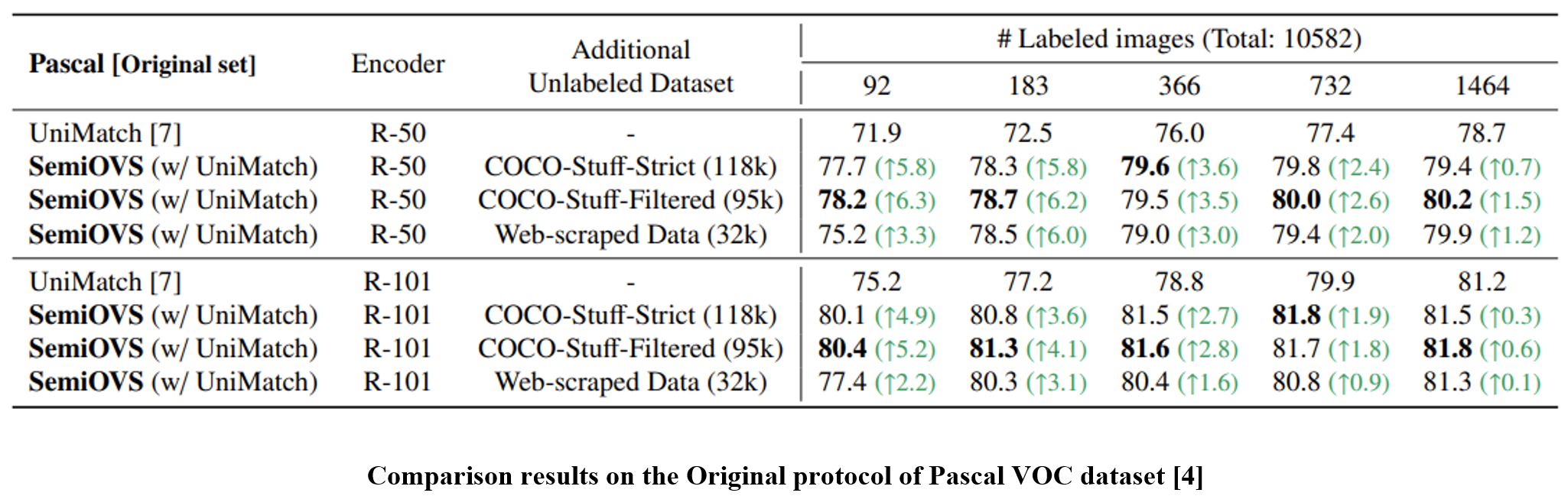
Extensive experiments on the Pascal VOC and Pascal Context datasets reveal that (1) leveraging additional unlabeled images from the COCO dataset or online sources significantly improves the performance of the semi-supervised learner, and (2) using the OVS model to pseudo-label OOD images substantially improves performance.
Propagating Complementary Multi-Level Aggregation Network for Polyp Segmentation
Objective
Colorectal cancer (CRC) usually begins as a polyp in the intestinal mucosa, and approximately one quarter of untreated polyps can develop into colon cancer.
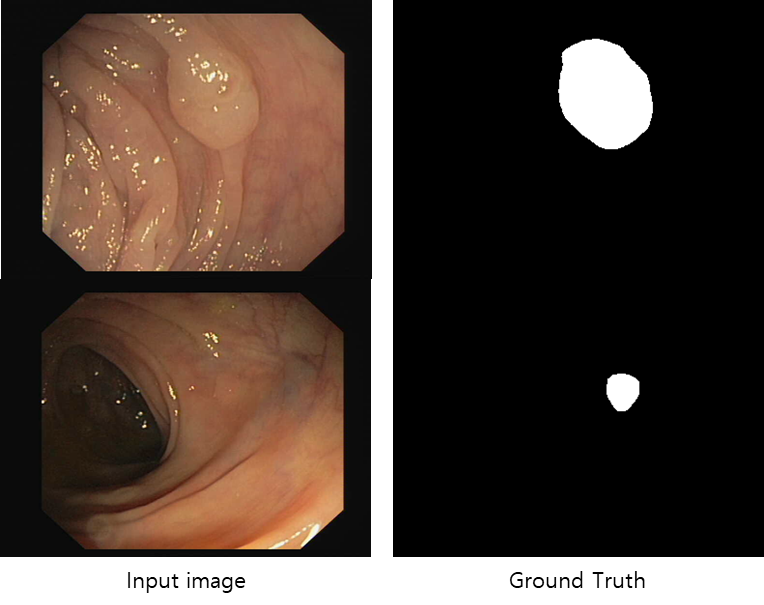
As the polyps are usually small and the boundaries are low in contrast to their surroundings, polyps can easily be mistaken for wrinkles or other intestinal structures.
Polyp detection using colonoscopy images is a challenging task owing to the ambiguous image context.
Data
Train & Validation: Kvasir (900 images), CVC-ClinicDB (550)
Test: Kvasir (100), CVC-ClinicDB(62), CVC-ColonDB (380), ETIS (196), EndoScene.CVC-300 (60)
CVC-Clinic – https://polyp.grand-challenge.org/site/Polyp/CVCClinicDB/
CVC-Colon – http://www.cvc.uab.es/CVC-Colon/index.php/databases/
ETIS, EndoScene – http://www.cvc.uab.es/CVC-Colon/index.php/databases/cvc-endoscenestill/
Related Work
U-Net and U-Net++ exhibits a distribution discrepancy between the low-level and high-level representations when aggregating multi-level features.
Psi-Net and SFA addressed a joint training strategy using the polyp region and boundary detection tasks.
PraNet employed a parallel reverse attention method with partial decoders to incorporate the polyp area and boundary features.
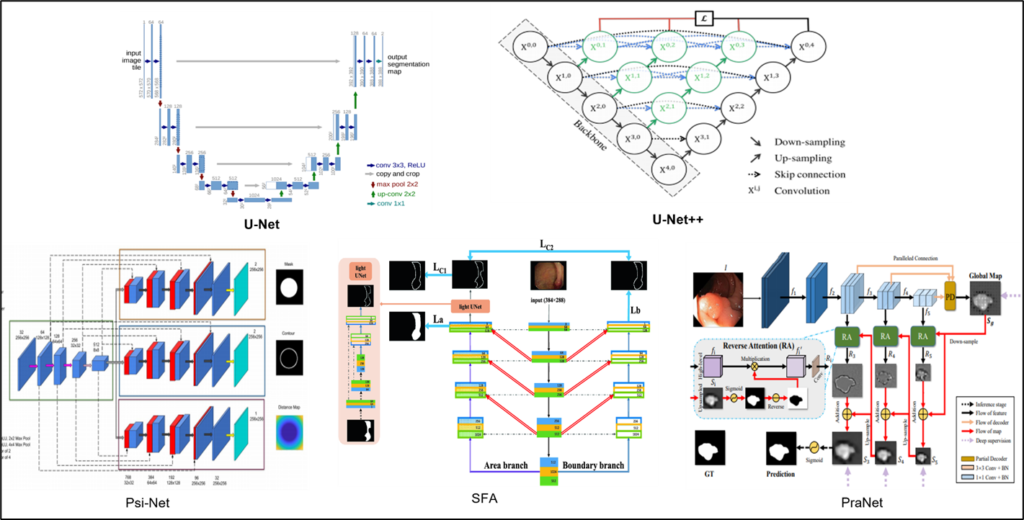
UNet++: A Nested U-Net Architecture for Medical Image Segmentation
Psi-Net: Shape and boundary aware joint multi-task deep network for medical image segmentation
SFA: Selective Feature Aggregation Network with Area-Boundary Constraints for Polyp Segmentation
PraNet: Parallel Reverse Attention Network for Polyp Segmentation
Proposed Method
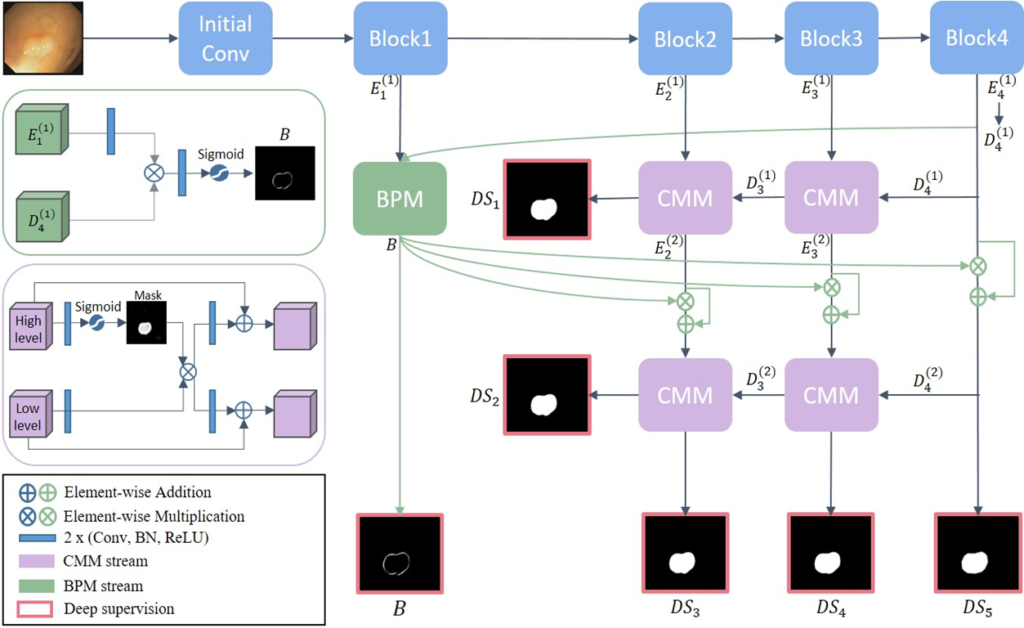
The proposed network, COMMA, is designed to reduce the multi-level distribution discrepancy by propagating both refined levels and explicit boundary information. To proliferate distinct information, we employ multi-decoder structures consisting of CMMs and BPM.
CMM : CMM clarifies the boundary noise in the low-level through the abstracted high-level representation and propagates the refined information to another decoder.
BPM : BPM is designed to propagate the explicit boundary information to the complementary multi-level features by incorporating the lowest- and highest-level representations. The boundary information is propagated to the CMMs in the next decoder to enhance the segmentation performance.