Deep Learning – Multi modal
HiLINK: Hierarchical Linking of Context-Aware Knowledge Prediction and Prompt Tuning for Bilingual Knowledge-Based Visual Question Answering
Objective
Knowledge-based visual question answering (KBVQA) is a representative visual reasoning task that leverages external knowledge for question answering in situations where predicting the correct answer using only image and query data is difficult. In addition to KBVQA, various visual reasoning tasks have been actively studied for their potential to improve visual understanding by combining text and image modalities effectively. However, these tasks have primarily focused on high-resource languages, such as English. In contrast, studies on low-resource languages remain comparatively rare. To mitigate this research gap, we propose HiLINK, which utilizes multilingual data to enhance KBVQA performance in various languages.
Data
We use the BOK-VQA dataset [1] which is an English multi-speaker corpus.
[1] Kim, MinJun, et al. “Bok-vqa: Bilingual outside knowledge-based visual question answering via graph representation pretraining.“, AAAI 2024.
Related Work
The 2-stage structure of GEL-VQA incurs high retraining costs when adding new triplet knowledge and has a high risk of information loss and noise during the fusion of KGE and image-text modality spaces. As a result, it is impractical for real-time dynamic environments.
Proposed Method
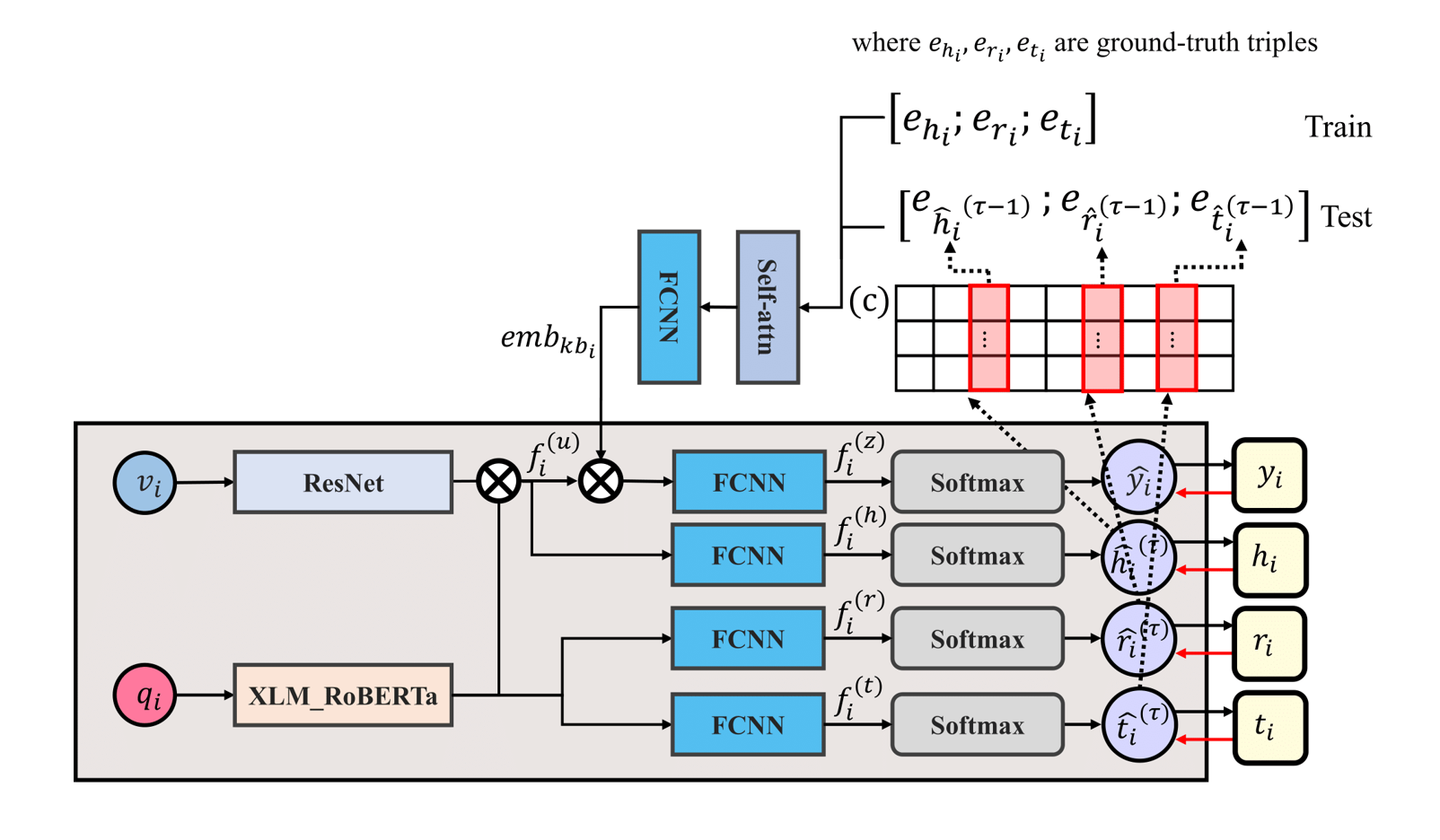
Link-Tuning efficiently learns triplet relationships within a text encoder’s shared representation space. Unlike traditional KGE, it integrates new knowledge without retraining or alignment with the backbone model. By leveraging structured prompts, it enables autonomous relationship learning. Previous studies predicted relationships independently from encoder-extracted vectors but lacked triplet interactions. To address this, HK-TriNet and HK-TriNet+ extend FiLM as a hierarchical knowledge transfer module, enabling effective triplet relationship learning through contextual information propagation.
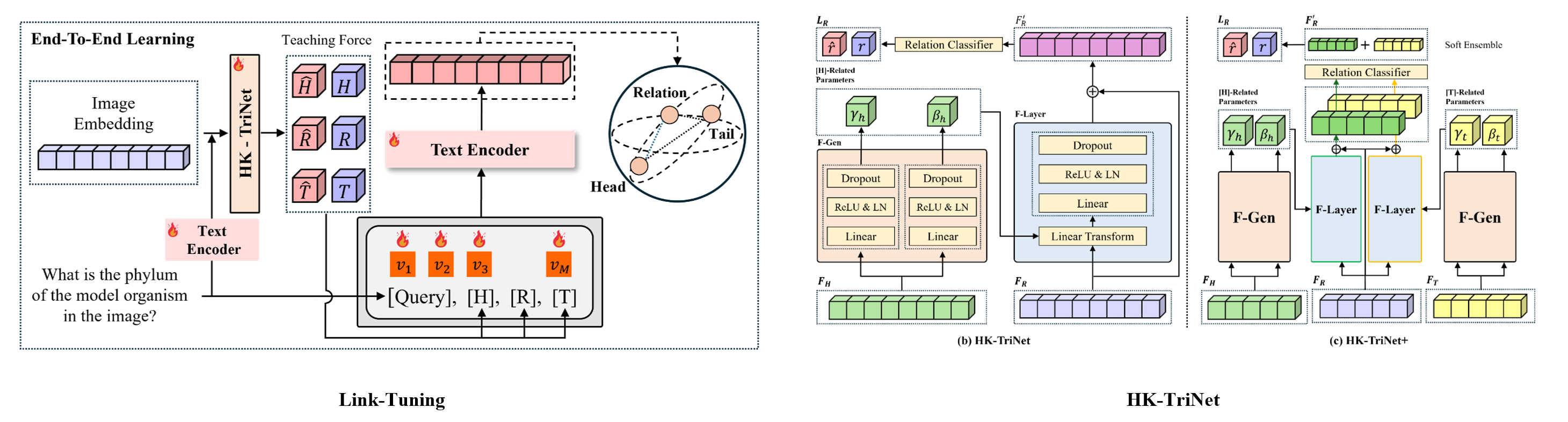
The HiLINK model outperformed the SOTA model, GEL-VQA, achieving 19.40% higher accuracy in a bilingual setting, 12.01% in English, and 11.30% in Korean. Additionally, some VLM-based baseline models proposed in this study also surpassed GEL-VQA. Moreover, HiLINK reduced error margins, demonstrating stable generalization performance.
Performance improvements were validated, and embedding learning effectiveness was analyzed. The Freeze-Freeze method splits the representation space, whereas the Frozen-Training method ensures a more uniform distribution within a single space.

Deep Learning-based Medical Tabular Learning for Automatic ICD Code Prediction
Objective
The International Classification of Diseases (ICD) prediction is the task for automatic ICD coding, which involves classifying medical diagnoses based on text and tabular data. The previous methods have the problem of the underutilization of tabular data in ICD coding. We propose a novel Medical Tabular Network (MedTabNet) that integrates both tabular and text data using a deep learning-based approach, with a key focus on embedding tabular data and incorporating a gate mechanism to filter out uninformative features.
Data
We use the MIMIC-III dataset [1] containing ICU patient records with text and structured tabular data.
[1] A. E. Johnson, T. J. Pollard, L. Shen, L.-w. H. Lehman, M. Feng, M. Ghassemi, B. Moody, P. Szolovits, L. Anthony Celi, R. G. Mark, Mimic-iii, a freely accessible critical care database, Scientific data 3 (1) (2016) 1–9.
Related Work
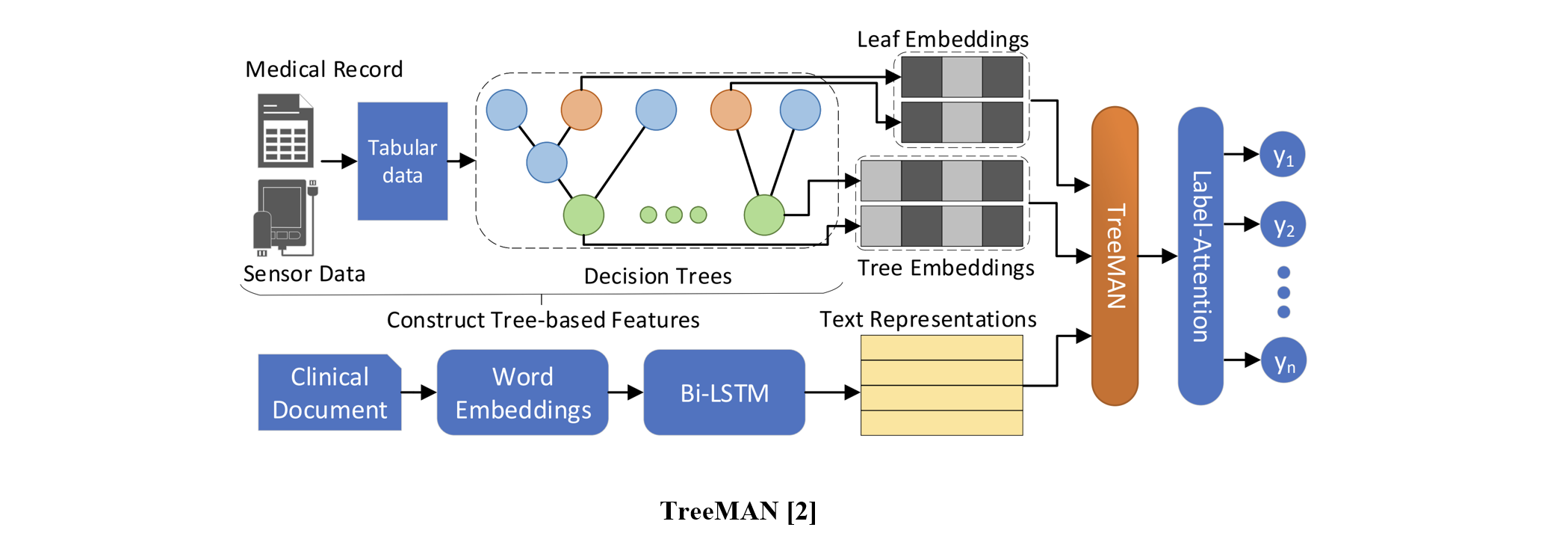
TreeMAN [2] designed the network using a decision tree and LSTM to handle both tabular and text data.
Proposed Method
Medical Tabular Network (MedTabNet) is a deep learning-based model that integrates tabular and text data for automatic ICD coding. MedTabNet includes two key components: an embedding layer to preserve the unique meaning of tabular features and a gate mechanism to filter out uninformative items. The overall structure extracts tabular and text information, combines them using cross-attention, and performs prediction through label attention.
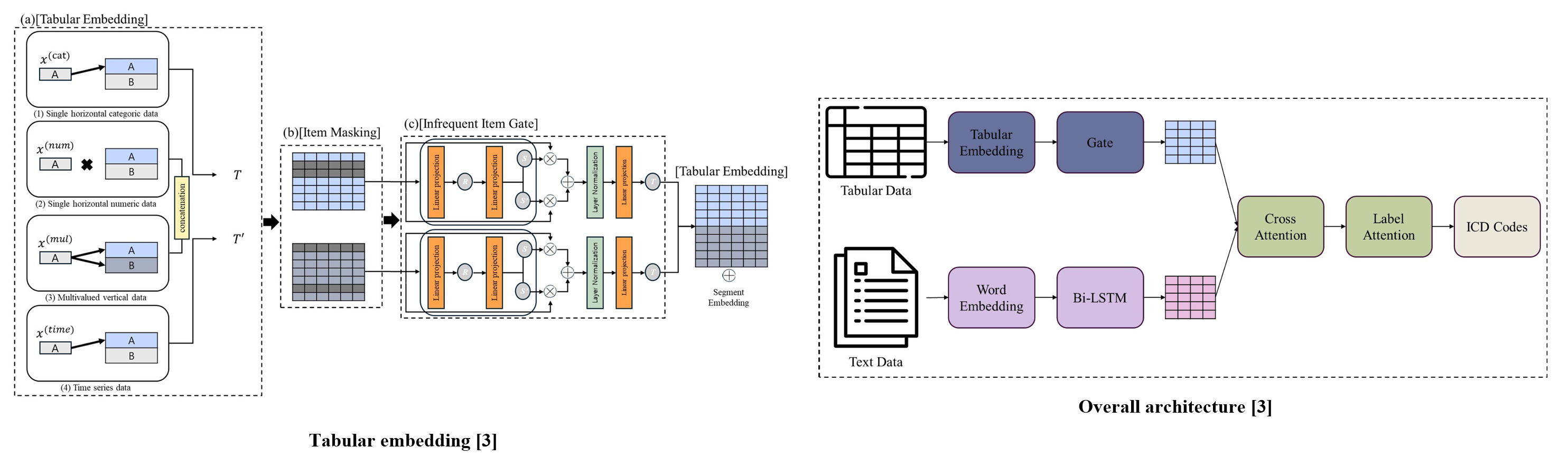
MedTabNet outperforms text-only models for ICD code prediction, improving F1 macro by 1% and F1 micro by 0.9%. It also surpasses TreeMAN, a tabular data-based model, with increases of 0.8 in F1 macro and 0.5 in F1 micro. These results demonstrate the effectiveness of deep learning for tabular medical data.
The infrequent item gate improved F1 macro by 0.5 and F1 micro by 0.2 by prioritizing frequent items and reducing overfitting. However, using a transformer for tabular representations led to performance degradation across all metrics, suggesting that standard transformers may not be well-suited for tabular data. Additionally, the medication feature had the most significant impact on performance, while excluding charts and personal information had minimal effect.

OHiFormer: Object-Wise Hierarchical Dependency-Based Transformer for Screen Summarization
Objective
Screen summarization aims to generate concise textual descriptions that communicate the crucial contents and functionalities of a mobile user interface (UI) screen. Previous works have focused on encoding the absolute position of objects at the view hierarchy to extract the semantic representation of the UI screen. However, the importance of the hierarchical dependency between objects in the UI structure was overlooked. In this study, we propose an object-wise hierarchical dependency-based Transformer, which involves a modified self-attention mechanism using structural relative position encoding to represent the hierarchically connected UI.
Data
We used the Screen Summarization dataset [1] to evaluate the performance of our proposed model. The dataset contains 22,417 screens from 6K mobile apps with five human-annotated summary labels for each screen.
[1] B. Wang et al., ‘‘Screen2Words: Automatic mobile UI summarization with multimodal learning’’, 2021
Related Work
User Interface (UI) is a hierarchical collection of a set of objects with various properties, such as text, class, and bounding box. Several approaches have been proposed to extract the latent representations of UIs.
Screen2Vec [2] present a self-supervised method for UI embedding adopting preorder traversal to represent the object position in a hierarchical structure and encodes it using a recurrent neural network.
Screen2Words [1] first formulated a screen summarization task of generating concise language-based on a holistic understanding of screens.
Versatile UI Transformer (VUT) [3] projects the structural absolute position used in Screen2Words onto the Fourier vector embedding space.
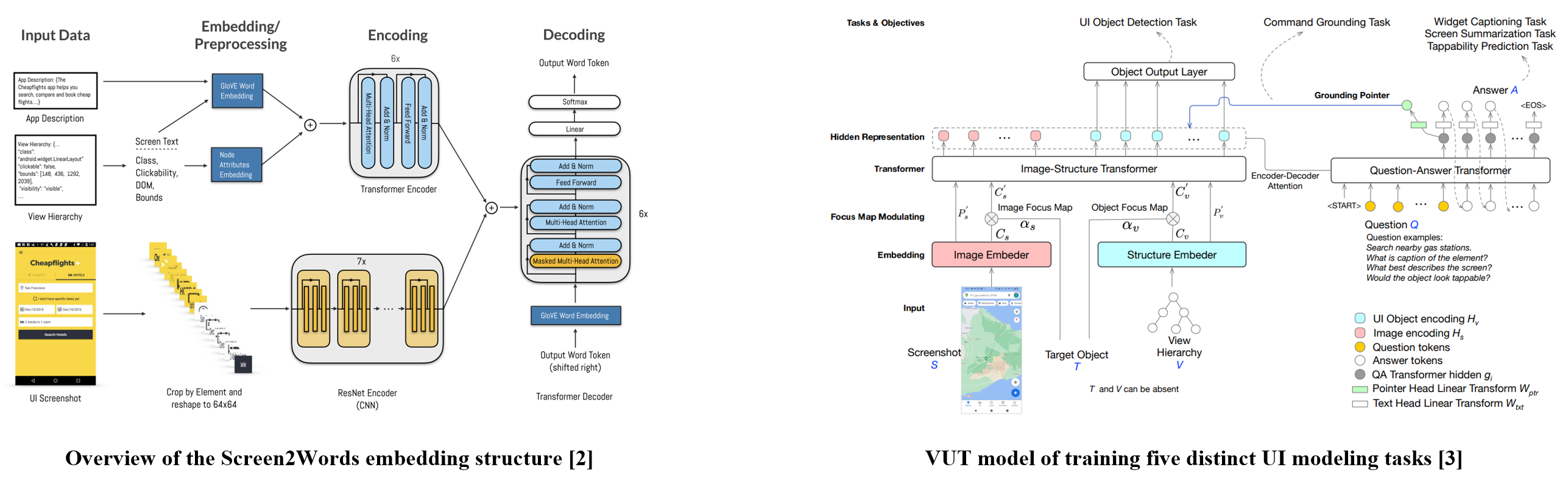
[3] Y. Li et al., “VUT: Versatile UI transformer for multi-modal multi-task user interface modeling,” 2021
Proposed Method
Given a UI screen with its view hierarchy, we obtain four types of properties from UI objects: images, texts, resource-ids, and bounding boxes. As shown in the figure, we embed each UI property for its modality, followed by linear projections, and we fuse them into object-wise single vectors.
Next, we pass the UI-embedded sequence through the Transformer network where we propose object-wise hierarchical dependency-based attention (OHi-attention) replacing the conventional self-attention layers from the encoder. Inspired by DocFormer [4], OHi-attention is designed to inject an inductive bias into conventional query–key scoring thus the attention weighs more on hierarchically nearby UI objects.
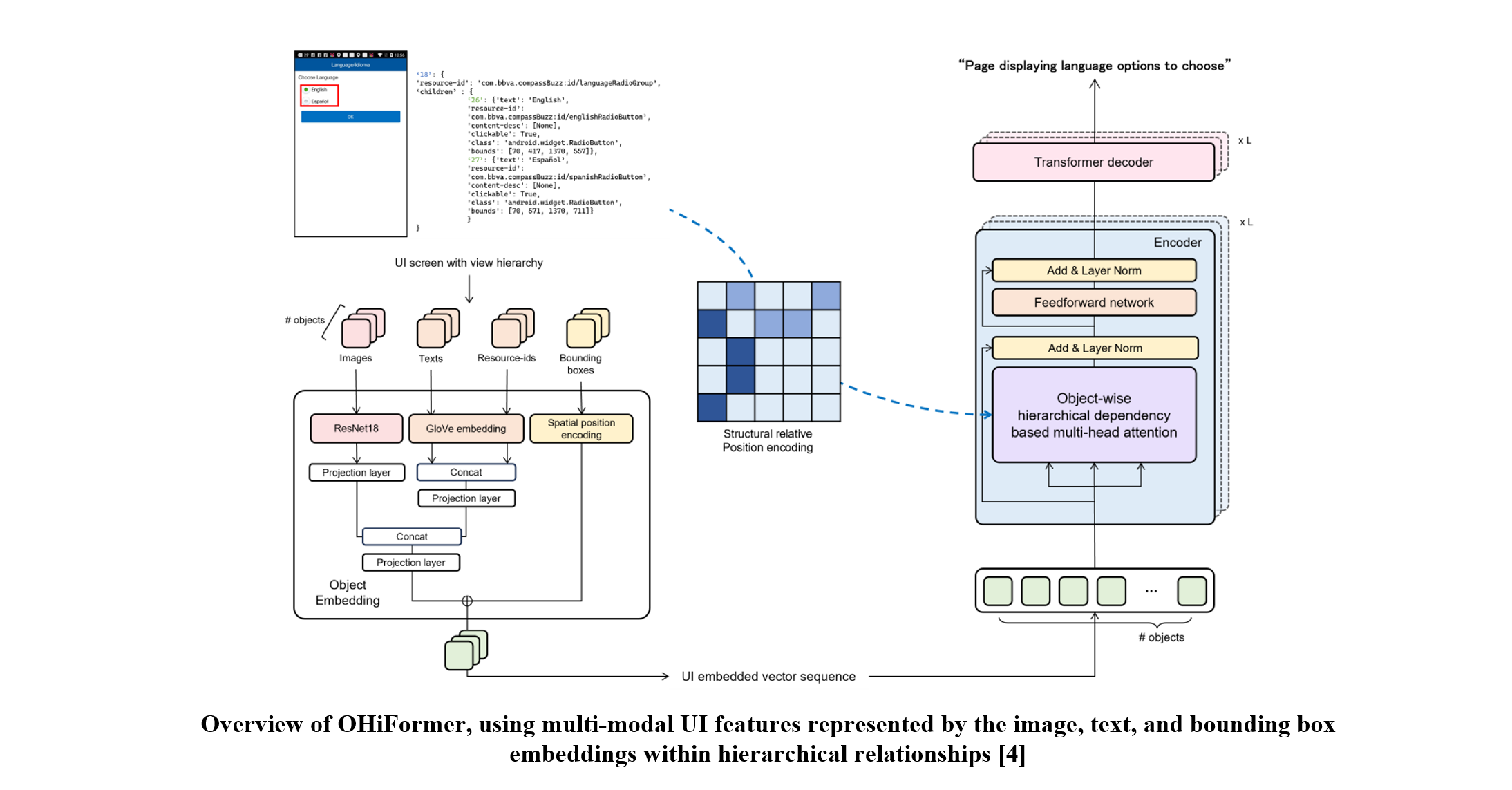
[5] Y. J. Han et al., “Object-Wise Hierarchical Dependency-Based Transformer for Screen Summarization”, 2024.
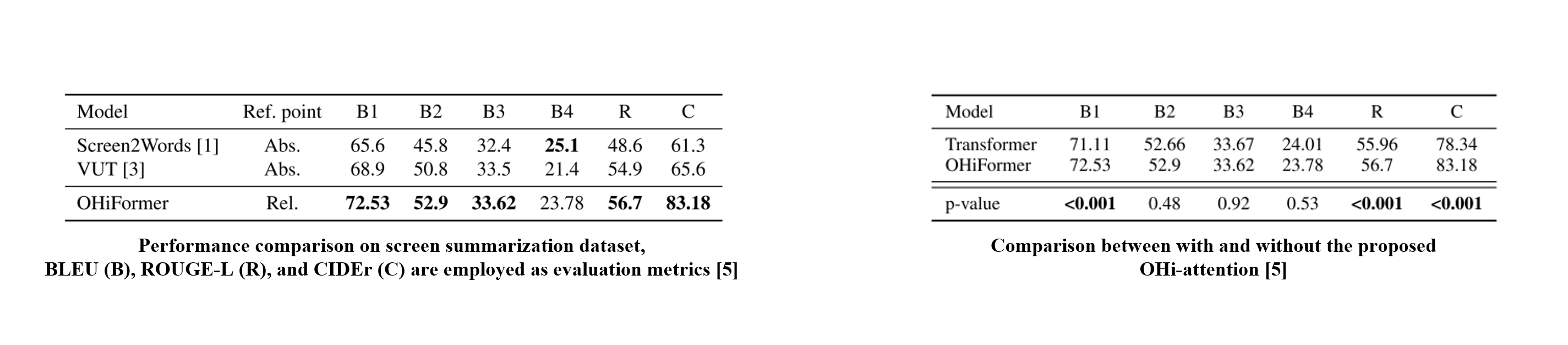
Within evaluation from the Screen Summarization dataset, OHiFormer outperformed state-of-the-art methods adopting other structural position encoding methods.
Given that OHi-attention surpasses naive query–key scoring in all metrics, injecting UI structural position information contributes to the model to understand the complex relationships and meanings of the UI.
Notably, the extra-high scoring of CIDEr, which considers the word frequency, demonstrates that the proposed method can generate the diverse content of summaries reflecting intricate UI structures.