Deep Learning – Sequence Data
Temporal-Contextual Attention Network for Solid-State Drive Failure Prediction in Data Centers
Objective
SSD failure prediction in data centers is the task of accurately identifying potential drive malfunctions while capturing complex temporal patterns and inter-attribute dependencies. Existing methods do not simultaneously address these aspects, and their performance suffers from a trade-off between rigid feature selection and the need to consider distinct attribute characteristics over time. In this study, we propose the Temporal-Contextual Attention Network (TCAN), a novel deep learning model that integrates both LSTM and transformer architectures with a feature grouping methodology, thereby enhancing the reliability of storage systems and mitigating SSD failure risks in critical data center environments.
Data
We use private datasets from the Tencent data center, which capture real-world usage patterns.
Related Work
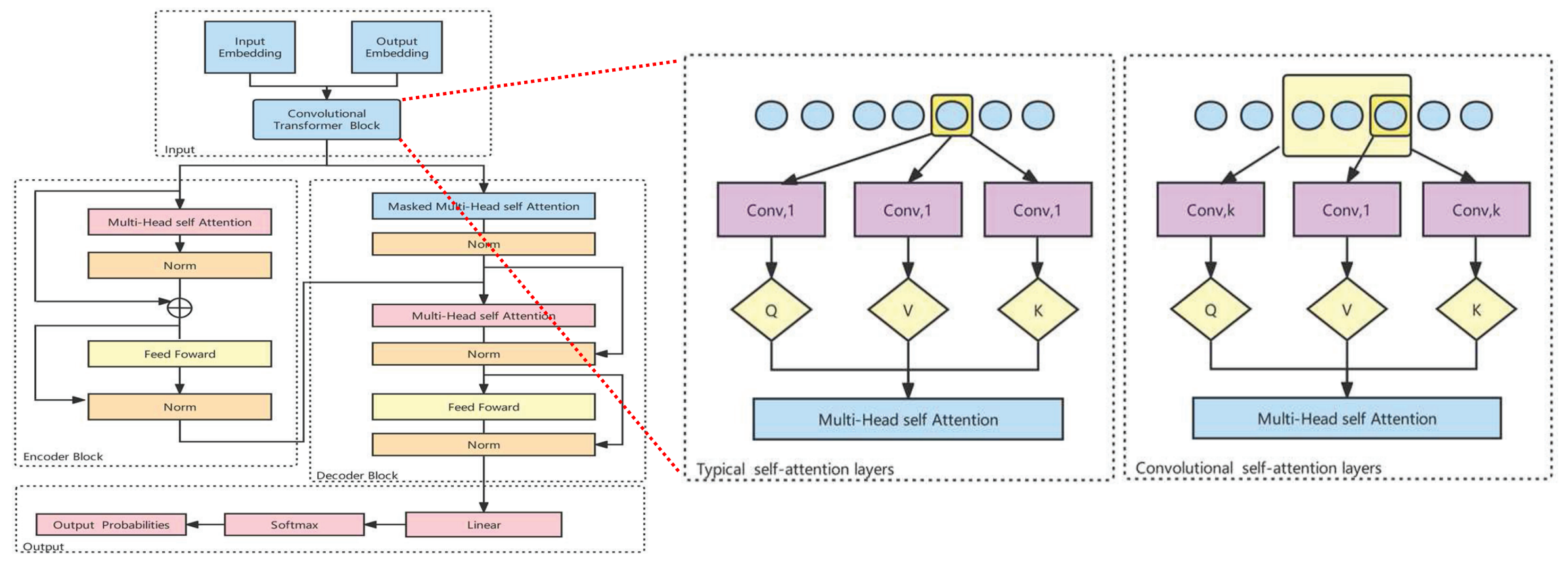
Convtrans-tps[1] is the first to combine Transformers with 1D Convolution, achieving a significant performance boost compared to using either CNNs or Transformers alone. The proposed model, ConvTrans, replaces the Transformer’s original position-based linear projection with a convolutional projection to capture local context instead of point-wise values. By aggregating the temporal features of adjacent data, ConvTrans-tps strengthens time-based feature representation for improved fault prediction.
Proposed Method
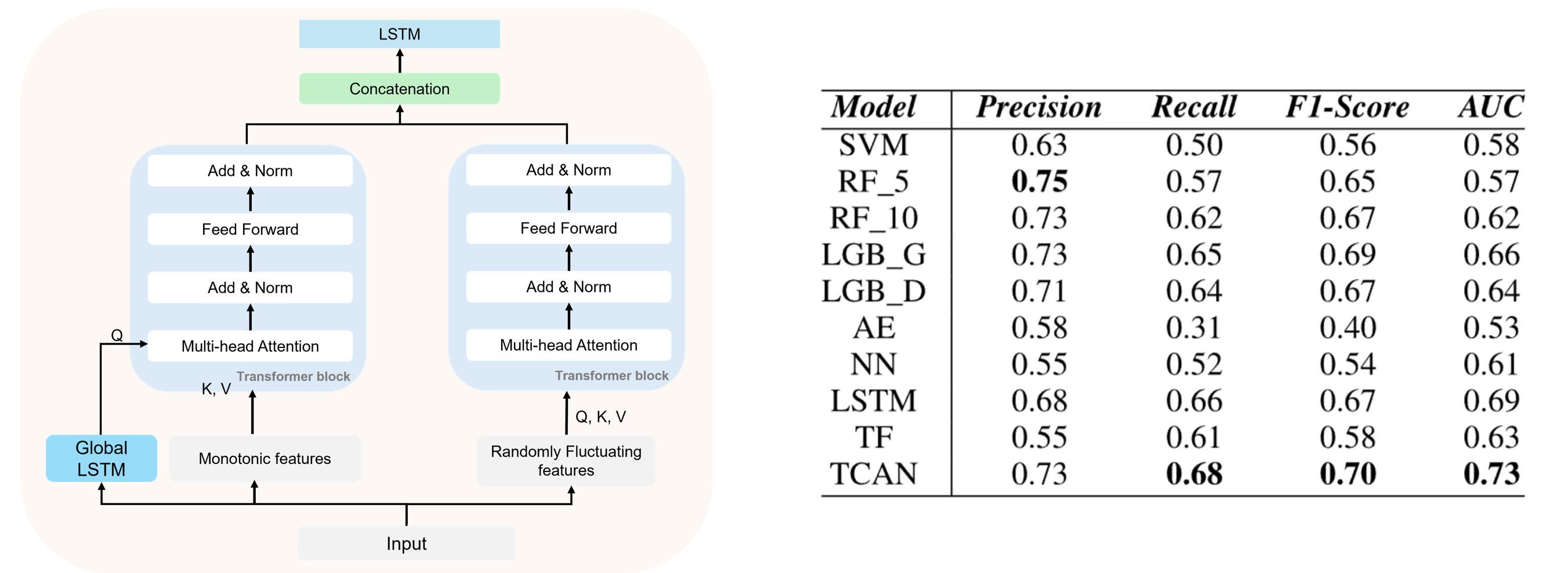
Temporal-Contextual Attention Network (TCAN)[2], is designed to enhance solid-state drive (SSD) failure prediction by integrating the strengths of long short-term memory (LSTM) and transformer architectures. TCAN employs a feature grouping approach to effectively analyze the SMART attributes of SSDs, categorizing them into monotonic attributes, which exhibit consistent patterns over time, and random fluctuating attributes, which are characterized by variability. The model consists of two main modules: the Temporal-Contextual Attention (TCA) module and the Feature Correlation (FC) module. The TCA module leverages cross-attention mechanisms to focus on relevant monotonic features while simultaneously applying self-attention to capture relationships among fluctuating attributes. Meanwhile, the FC module introduces a trainable CLS token to learn inter-attribute correlations comprehensively. By combining the temporal progression of monotonic attributes with the contextual information from random fluctuations, TCAN aims to improve the accuracy of SSD failure predictions, thereby enhancing the reliability and service stability in data center environments.
SimSon: Simple Contrastive Learning of SMILES for Molecular Property Prediction
Objective
Molecular property prediction with deep learning has accelerated drug discovery and retrosynthesis. However, the shortage of labeled molecular data and the challenge of generalizing across the vast chemical spaces pose significant hurdles for leveraging deep learning in molecular property prediction. This study proposes a self-supervised framework designed to acquire a Simplified Molecular Input Line Entry System (SMILES) representation utilizing contrastive learning with randomized SMILES augmentation.
Data
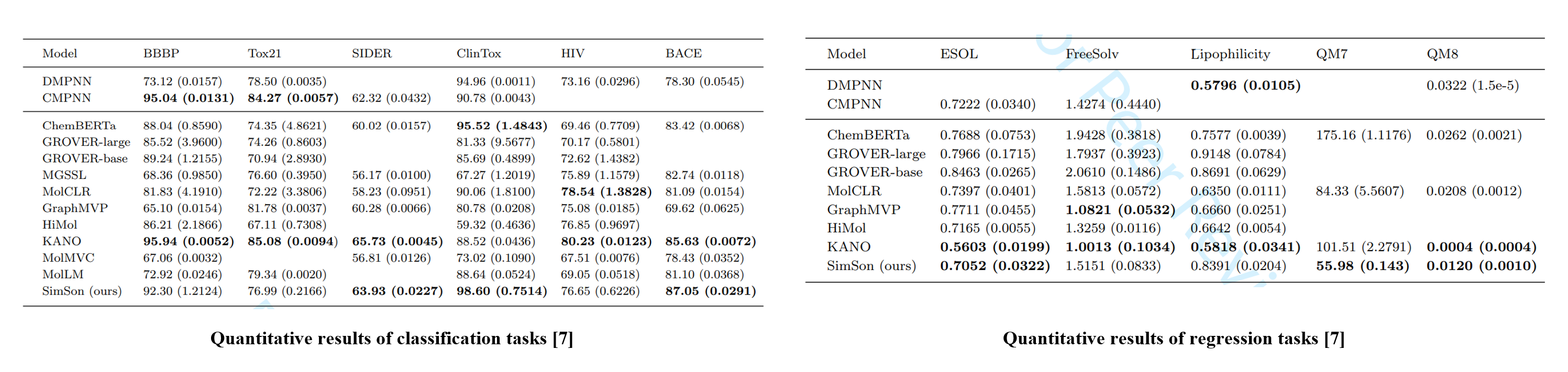
To validate the generalization ability attained from the proposed self-supervised learning strategy, we employ several downstream task datasets [1] as: BBBP, Tox21, SIDER, ClinTox, HIV, and BACE are datasets for classification tasks, and ESOL, FreeSolv, Lipophilicity, QM7, and QM8 are for regression tasks.
[1] B. Ramsundar et al., “Deep Learning for the Life Sciences”, 2019.
Related Work
Self-supervised learning is a technique used to train models for learning data representations without relying on labeled data.
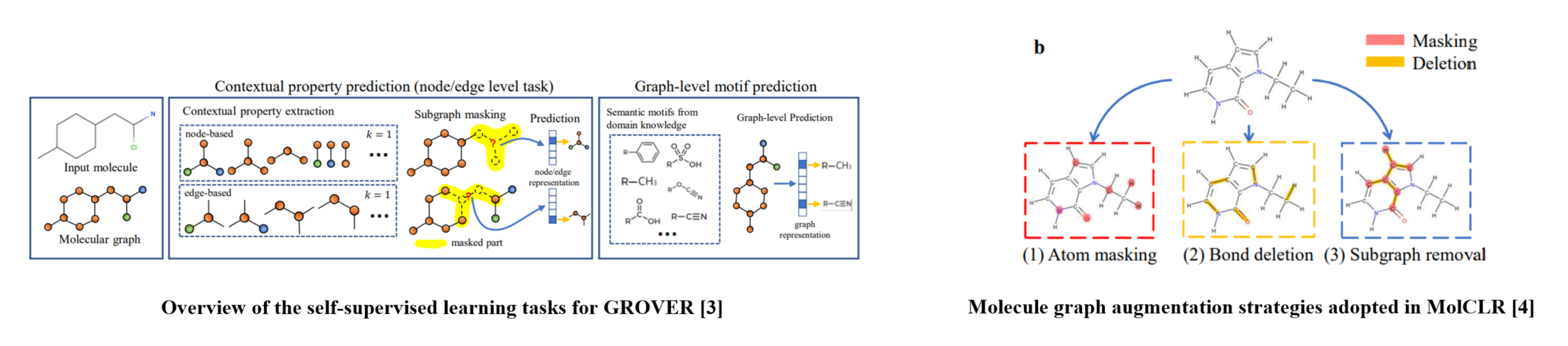
One common method within self-supervised learning is the predictive approach, where models learn data representations by making predictions on masked tokens, atoms, or bonds.
ChemBERTa [2] predicts masked tokens to acquire SMILES representations, GROVER [3] focuses on predicting masked atom or bond attributes to learn molecular graphs.
MolCLR [4] introduced contrastive learning with graph-based augmentations, enhancing molecular graphs by randomly masking atoms or deleting bonds before computing contrastive loss.
[3] Y. Rong et al., “Self-supervised graph transformer on large-scale molecular data”, 2020.
[4] Y. Wang et al., “Molecular contrastive learning of representations via graph neural networks”, 2022.
Proposed Method
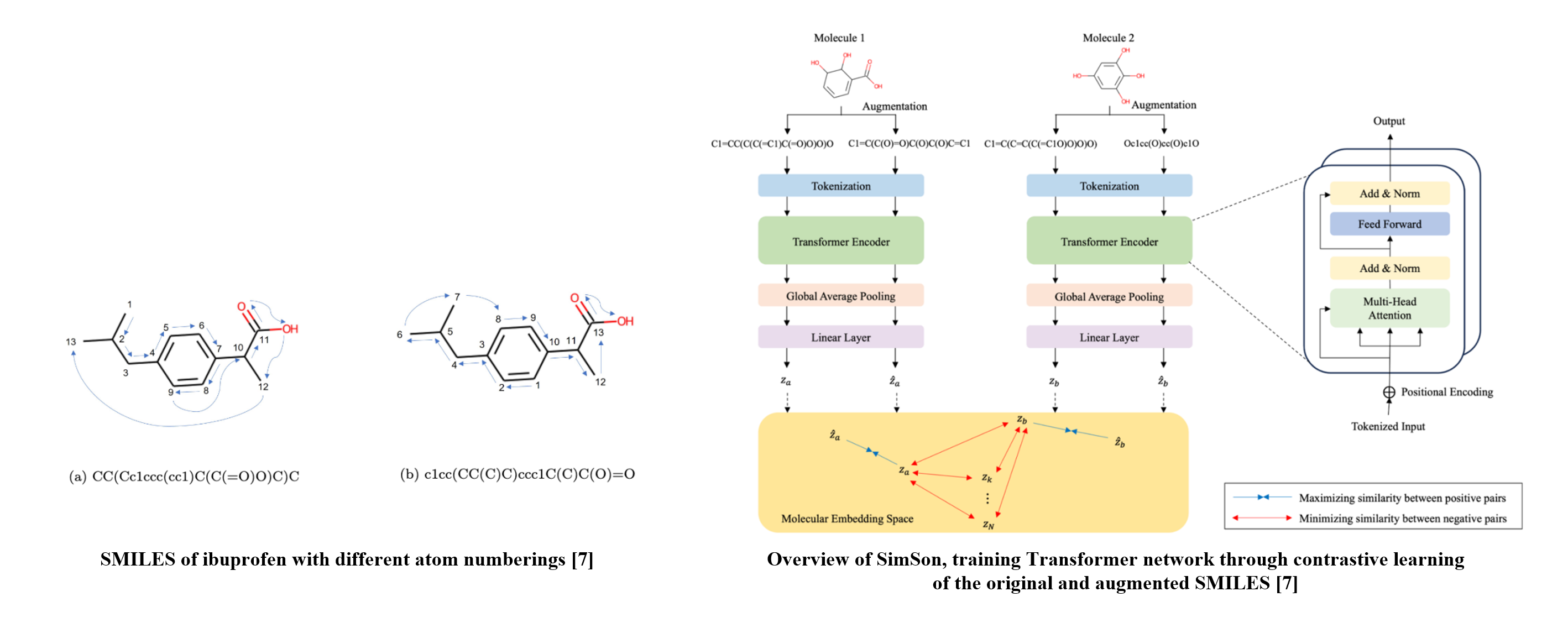
SimSon takes SMILES as its input and employs the SMILES enumeration [5] as SMILES augmentation technique. We employ a Transformer architecture with SMILES embedded sequences are passed through.
SimSon adopts the contrastive training objective of the normalized temperature-scaled entropy (NT-Xent) loss [6], minimizing the embedded distance between the enumeration of the same molecule and vice versa.
[6] T. Chen et al., “A simple framework for contrastive learning of visual representations”, 2020.
[7] C. E. Lee et al., “Simple Contrastive Learning of SMILES for Molecular Property Prediction”, 2024.
SimSon achieves the best or second-best performance on six out of eleven tasks, even though it employs a simple classification layer, whereas other models incorporate more complex classification architectures. This demonstrates that SimSon effectively learns SMILES representations for downstream tasks while maintaining strong generalization across the chemical space. This generalization ability is largely attributed to its training with randomized SMILES, which reduces overfitting by introducing controlled perturbations.
WAY: Estimation of Vessel Destination in Worldwide AIS Trajectory
Objective
To address the problem of destination estimation ahead of vessel arrival, the objective of learning from a data-driven approach is to maximize the conditional probability of the destination port, given the departure and the ordered sequence of AIS messages to the current time.
Data
Satellite AIS data collected from ORBCOMM and port identification data provided by SeaVantage were used during this study. Experiments were conducted on 5-year (Jan. 2016 – Nov. 2020) accumulated real-world AIS data of 5,103 individual ships, where the vessels belong to one of three types: tanker, container, and bulk. A total of ≃ 130K trajectories comprising ≃ 17M AIS messages were mapped between 3,243 worldwide port destinations. A destination-wise stratified split was used to generate the training/validation/test trajectory dataset as 70%, 15%, and 15% of the total.
Related Work
[1] To tackle the data bias issue arising from the irregular interval, the sequence of coordinates is tokenized in units of the spatial grid (1×1miles/grid). [2] Exploits LSTM-based sequence-to-sequence structure, with attention mechanism to predict a future trajectory sequence. [3] Using 4-hot vector representation, where each embedding corresponds to the range of longitude, latitude, sog, and cog, the transformer-decoder architecture predicts the future 4-hot vectors autoregressively.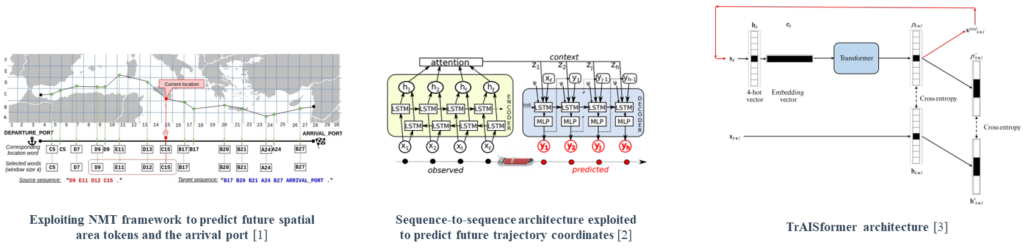
[2] S. Capobianco, L. M. Millefiori, N. Forti, P. Braca, and P. Willett, “Deep learning methods for vessel trajectory prediction based on recurrent neural networks,” IEEE Transactions on Aerospace and Electronic Systems, vol. 57, no. 6, pp. 4329–4346, 2021.
[3] D. Nguyen and R. Fablet, “TrAISformer-A generative transformer for AIS trajectory prediction,” arXiv preprint arXiv:2109.03958, 2021.
Proposed Method
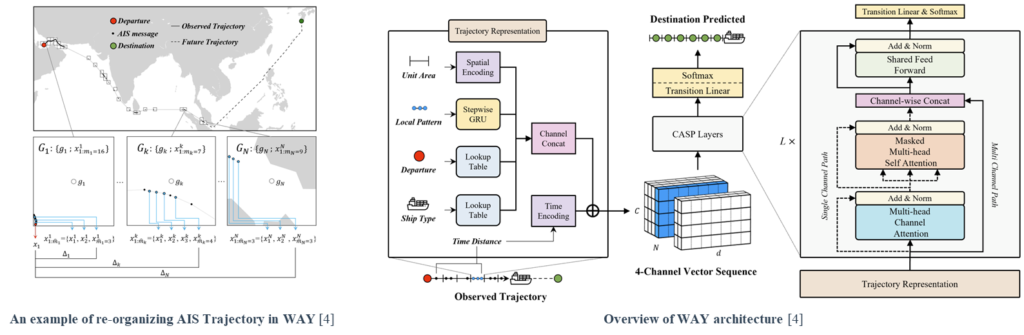
We first propose to recast the objective formulation defined on the message-wise trajectory processing to the format of a nested sequence. Since it adopts uniform grid-wise processing, such a format mitigates the spatiotemporal data bias, arising along the trajectory progression by irregular AIS collection intervals. Also, the nested structure preserves detailed information on trajectory progression within the unit area.
This work next introduces a novel deep-learning architecture (WAY) and a task-specialized learning technique to fit the redefined objective. Based on a multi-channel representation, the proposed architecture, WAY, processes AIS trajectories in spatial grid steps without losing the detailed AIS properties such as global-spatial identities, local patterns, semantics, and time-irregular progression of trajectory. As a result, the highlight of WAY are the enriching of the details and effective aggregation of representations while processing the AIS trajectory data.
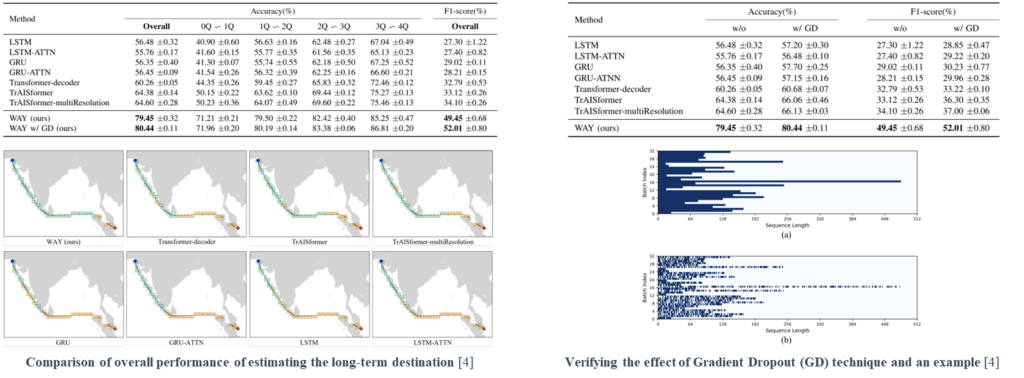
WAY achieves a remarkable improvement compared to the other benchmark models, and WAY with Gradient Dropout (GD) learning technique further demonstrates a performance gain. As well as the overall scores, WAY improves the performance of destination estimation for all steps along the trajectory, especially of which steps were included before the 1st quartile progression. This suggests the importance of enriching the detailed representations of the AIS trajectory and aggregating information effectively.
To generalize the advantage of the task-specialized learning technique in the trajectories with large length deviations, GDs were applied to all benchmark models. Applying GD always achieves a performance gain regardless of the backbone model. The average gains are +1.01% for the overall accuracy and +1.92% for the F1-score.
CRFormer: Complementary Reliability perspective Transformer for automotive components reliability prediction based on claim data
Objective
Reliability prediction in the automotive industry aims to predict the failure of automotive components. Previous studies showed unsatisfactory prediction results when short-term inputs are given. We propose Complementary Reliability perspective Transformer (CRFormer) based on Transformer encoder to achieve enriched representations from a short-term input sequence.
Data
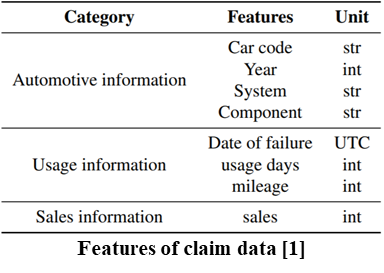
We use the claim data provided by an automobile company. The claim data were collected for 16 years, comprising 951,170 claims, from 2006 to 2021. The information for claim data is as below.
Related Work
InFormer [2] and AutoFormer [3] are Transformer-based time-series prediction methods.
InFormer proposed ProbSparse Self-attention and AutoFormer proposed Auto-correlation attention.
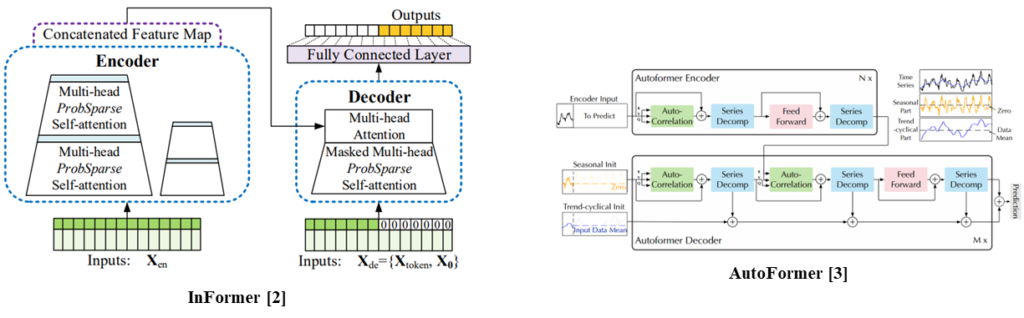
[3] Wu, Haixu, et al. “Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting.” Advances in Neural Information Processing Systems 34 (2021): 22419-22430.
Proposed Method
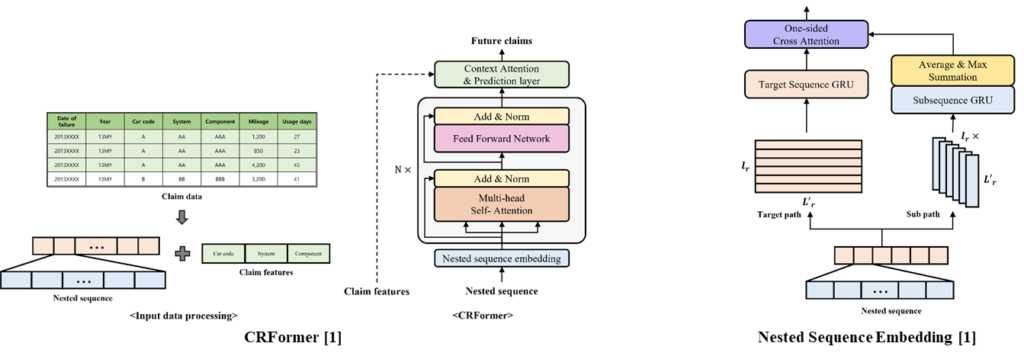
CRFormer is based on Transformer to represent sequential information of claim data. From the claim data, a nested sequence that contains both time and mileage-based information is generated and claim features are extracted. The nested sequence embedding module extracts sequential representations of the target reliability, time or mileage, from the nested sequence. Transformer encoder emphasizes the target sequential information. Finally, CA and a prediction layer merge claim features and each sequence step to predict future claims within the remaining warranty periods.
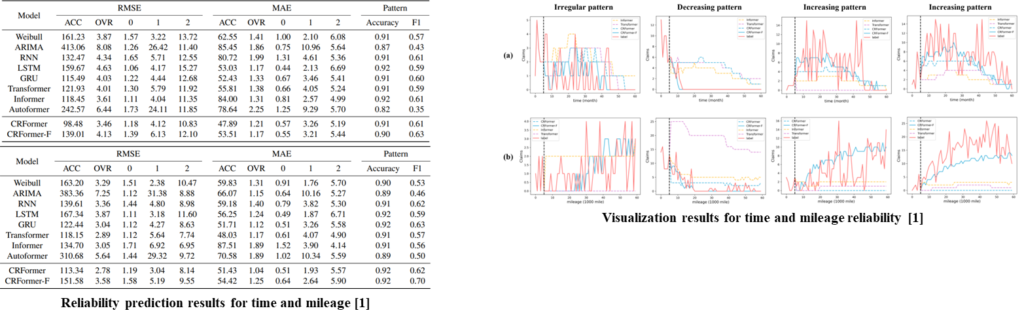
CRFormer achieved competitive performance on reliability prediction for both time and mileage perspectives. The prediction results of the proposed models capture the real claim patterns better, especially in the decreasing and increasing patterns, compared to other Transformer-based models. Regarding increasing patterns in the mileage reliability prediction, CRFormer-F can even capture the increasing patterns, whereas the others can not react at all. The poor performance of the other models in increasing patterns was also revealed through the low f1 scores.
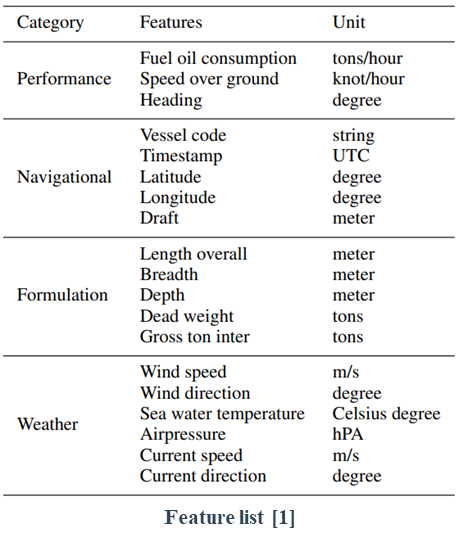
Time aware and Feature similarity Self Attention for vessel fuel consumption prediction
Objective
The goal of the research is to predict Fuel Oil Consumption (FOC) of ships. We investigate the ship data and extract three essential ship data properties. We propose the attention mechanisms to represent ship data properties, achieving outstanding prediction performance.
Data
We used 2.5 million amounts of ship and weather data from 19 types of containers. The data were collected by the container sensors from 2016 to 2019. We used ship spec data from Lloyd List Intelligence. The nominal twenty-foot equivalent unit TEU of containers is from 4000 to 13000. A dependent variable, fuel oil consumption (FOC), was acquired from the main diesel engine of the containers.
Related Work
The previous methods for FOC prediction adopted a typical Multi-Layer Perceptron or Long Short-Term Memory, which lacks representing ship data properties.
[3] Panapakidis, Ioannis, Vasiliki-Marianna Sourtzi, and Athanasios Dagoumas. “Forecasting the fuel consumption of passenger ships with a combination of shallow and deep learning.” Electronics 9.5 (2020): 776.
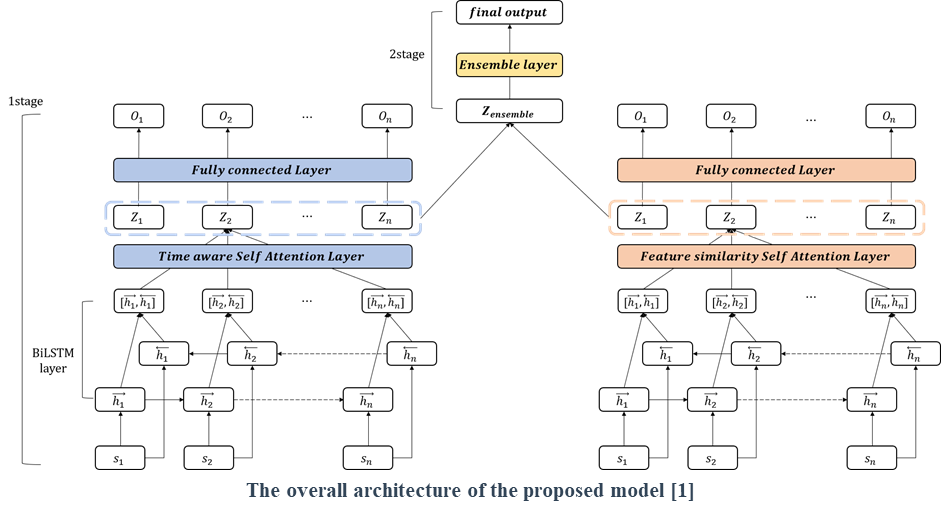
Proposed Method
The proposed model is based on sequence models to represent the sequential property of ship data.
Time aware attention considers irregular time steps in the sequence and emphasizes data depending on the time information.
Feature similarity attention extracts important feature and their weights based on feature similarity in the sequence.
By fusing the models considering time and feature, respectively, the proposed model can represent all the ship properties and achieve outstanding performance.
Automobile parts reliability prediction based on claim data: The comparison of predictive effects with Deep Learning
Objective
Reliability prediction, Automobile claim data to investigate various reliability prediction models using parametric method, time-series analysis, machine learning, and deep learning-based methods with a dataset of the reliability time series
Data
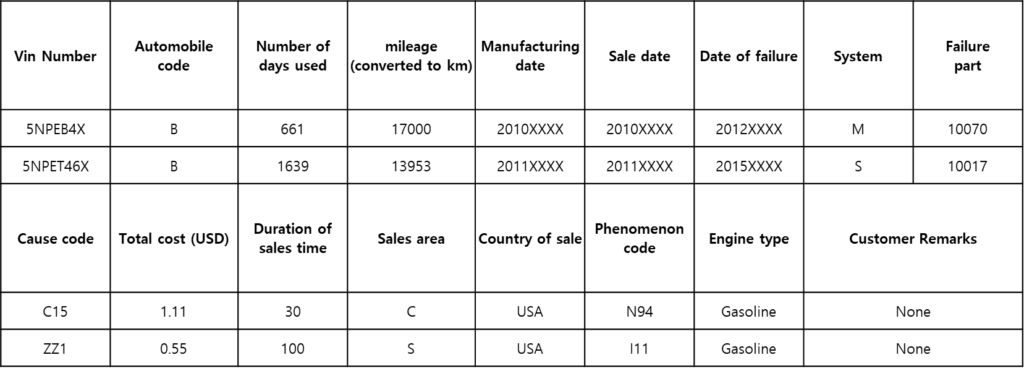
In this study, a warranty data called field claim was used to record the purchased car and its related causes of failure, parts, days of use, mileage, etc. for a quality repair. These data are key data that provide feedback on the life expectancy of the product and contain all failures within the warranty period. Among these field claim data, data from X-model automobile 06MY–14MY claims were extracted in the US market, which these data were made into virtual data by adding a little noise due to security issues and all were masked. Claim data is recorded and stored in the database when A/S is received, and 305,965 claims are extracted for study and recorded.
Related Work
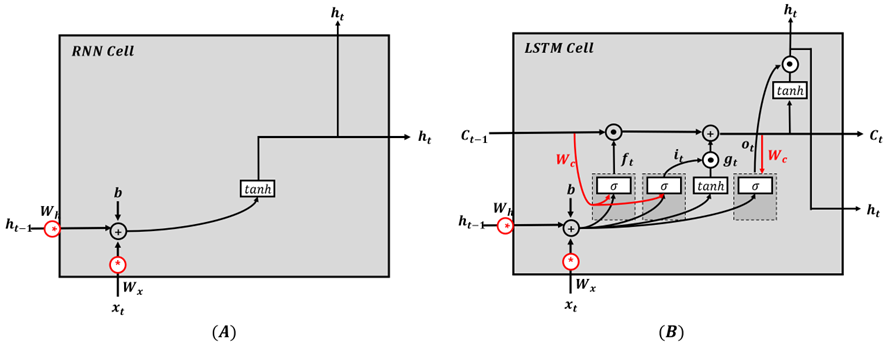
The RNN can learn how to forget or store information at each point in time, so it shows good performance especially in time-series data processing. However, when the time point to be predicted increases, a gradient vanishing problem could occur and the efficiency of the learning process decreases. RNN can learn how to forget or store information at each point in time, so it shows good performance especially in timeseries data processing. However, when the time point to be predicted increases, a gradient vanishing problem occurs, resulting in poor learning efficiency. To solve this problem, Hochreiter et al (1997) proposed long short term memory (LSTM). Unlike RNNs, LSTMs are designed to handle data with long periods of time and are used in various fields such as classification and time-series prediction.
Proposed Method
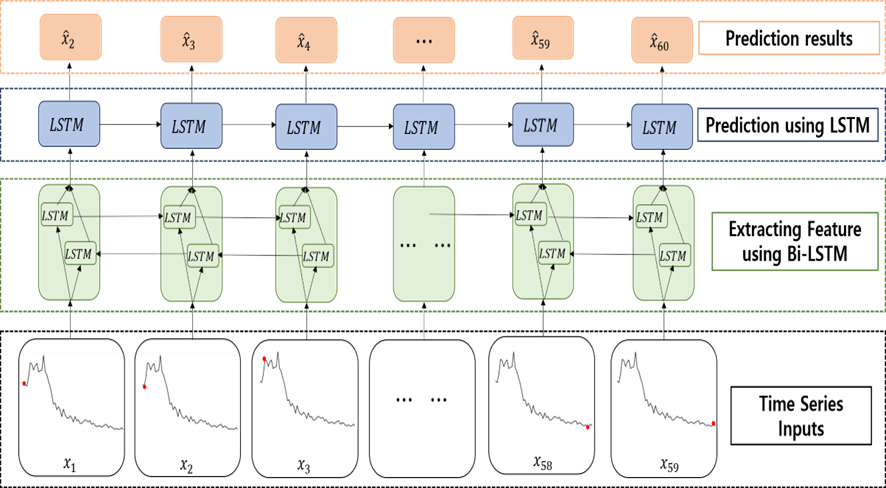
In the case of the training data, 59 values from the beginning to the end of the total 60 values were used as input data and 59 values from the second to the last were used as the output data. In the input layer, unlike many to one model, 59 values of data were entered as input for each time step to make it easy to grasp the time series of the entire pattern. Similarly, in the Bi LSTM layer, the inherent features of the entire time series were extracted. As these features were put into the LSTM for each time step, each predicted the next time point producing multiple outputs.