Contents of Projects
Development of Climate-Based Environmental Test Standards Using Customer Usage Data to Enhance Durability of New Technologies
[2025.06.01 ~ 2026.11.30, Hyundai NGV Corporation]Objective
Prediction of the Durability Status of Vehicle Components Under Extreme Driving Conditions.
The Need for an AI-Driven Method to Predict the Durability Status of Vehicle Components
- The traditional approach (physics-based models) for predicting the durability of vehicle components is vulnerable to changes in external environmental factors.
- Furthermore, the physics models are often highly dependent on the domain knowledge (e.g. connection structures and design) of vehicle components, making it difficult to extend across different vehicle models.
- Addressing these issues, data-analytic and deep-learning techniques are highlighted for their potential, which can automatically identify/select target-relevant variables during vehicle operation and determine their complex relationships.
Methodology
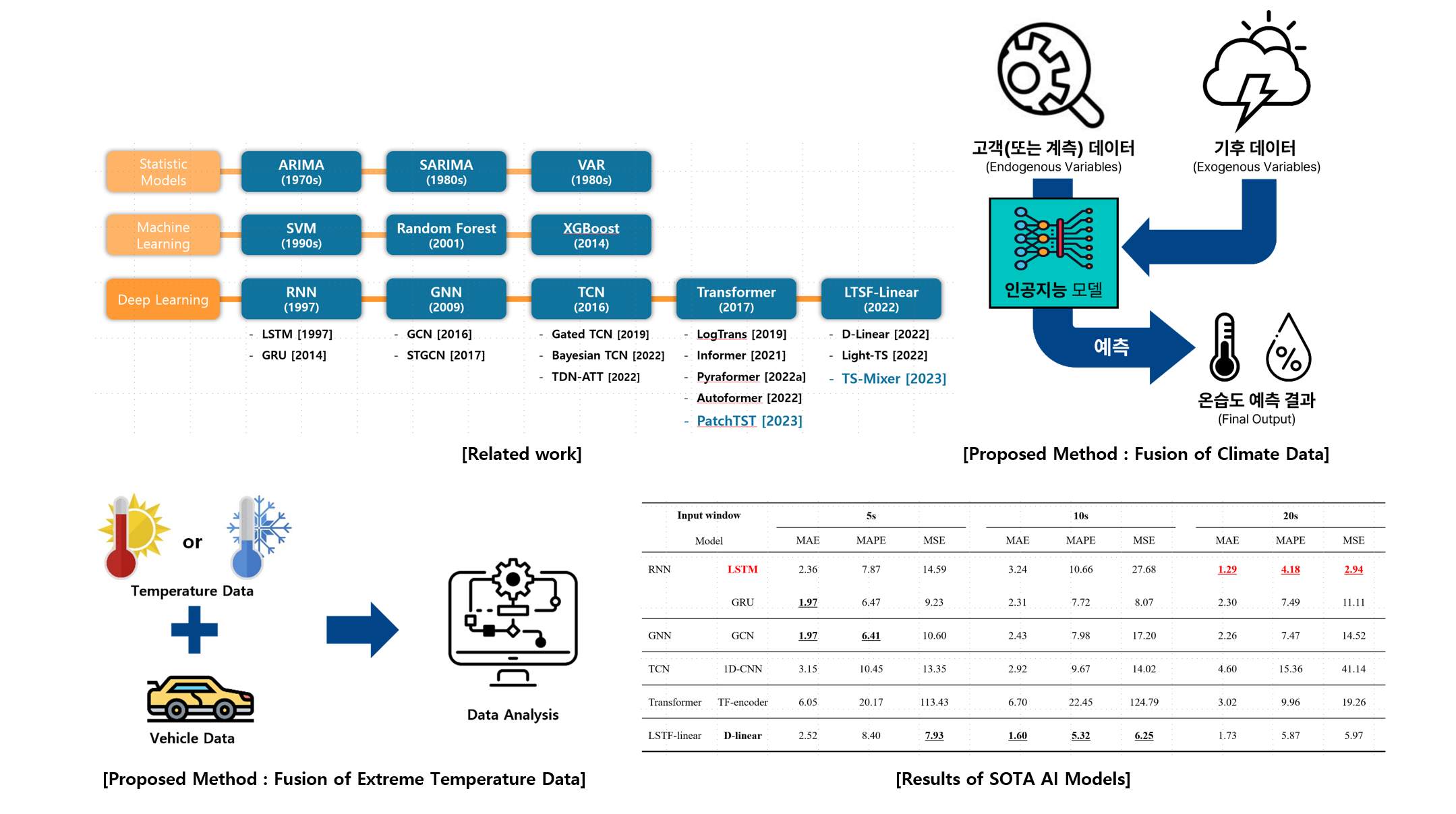
- We compare several state-of-the-art approaches in predictive models to estimate the vehicle component temperature given a sequence of multi-variable inputs representing driving conditions.
- We performed exploratory data analysis of automotive parts data for precise prediction.
- We plan to collect vehicle temperature and humidity data in extreme (extremely low temperature) and extreme (extremely high temperature) environments to verify that the model can operate normally under various climate conditions.
- Instead of using measurement data or customer data alone, climate datasets can be utilized as exogenous information to improve model performance.
Development of Trust AI Agents Core Model
[2025.04.21 ~ 2025.08.20, Trust Builders & Daishin Asset Trust]Objective
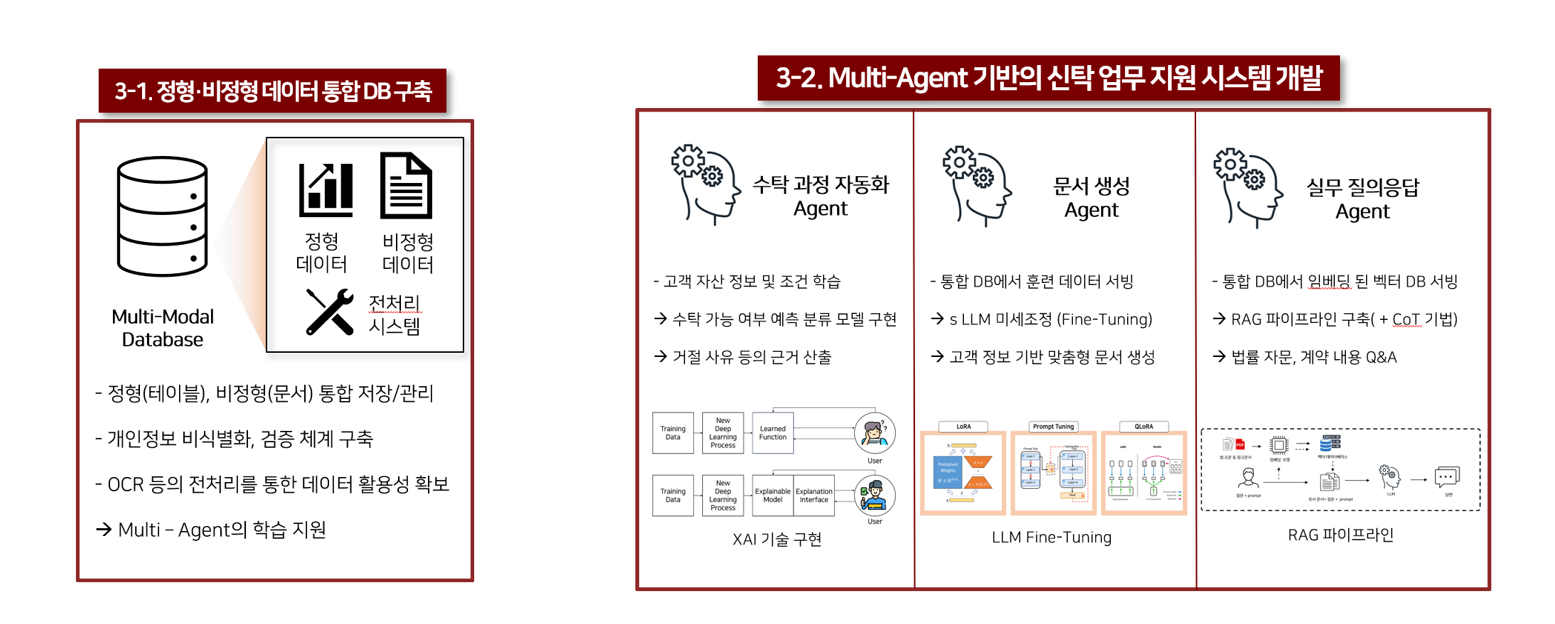
Development of AI agents with advanced capabilities that effectively assist and optimize tasks specific to trust-related operations in the financial industry.
Development of AI Agents Considering Practical Challenges in the Financial Industry, especially in Trust works.
- Reducing operational burden and improving efficiency by automating repetitive daily tasks. (RPA)
- Applying SOTA generative AI models and techniques, including LLMs, to handle unstructured tasks such as writing and reviewing legal and financial documents, thereby maximizing productivity.
- Studying effective strategies to collect training data for model development and explore methods to ensure secure and compliant data handling, particularly for sensitive financial documents.
Methodology
We utilize recent advances in large language models (LLMs), including Multimodal LLMs (MLLMs) and Retrieval-Augmented Generation (RAG) techniques, to build intelligent agents that enhance the efficiency of works in Trust.
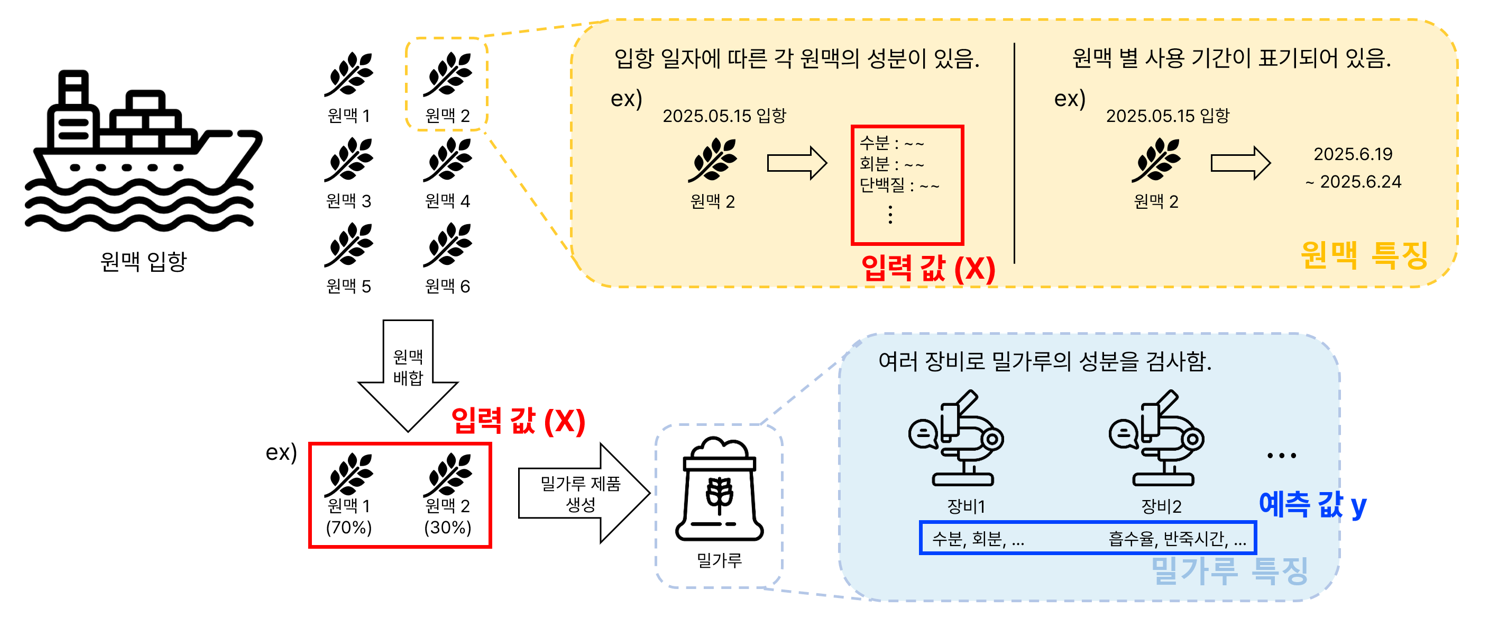
Development of a model for predicting the composition of wheat flour using NIR analysis
[2025.03.03 ~ 2026.02.28, Samyang Company]Objective
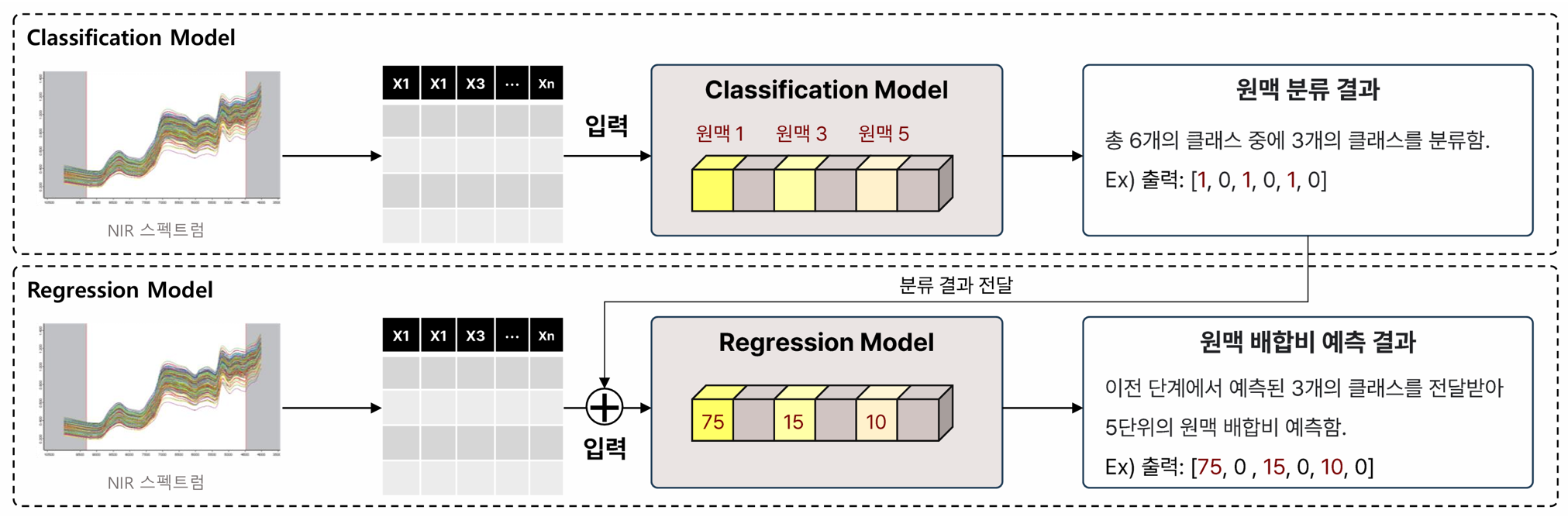
Predict the blending ratios of imported wheat used in flour production by leveraging near-infrared (NIR) spectral data and wheat physical characteristics.
Motivation
- Flour quality is significantly influenced by the specific combination and ratio of imported wheat varieties used during production.
- Traditionally, the blending process has relied on expert knowledge and manual adjustment based on experience.
- Such empirical approaches often lack consistency, scalability, and adaptability to varying wheat quality and supply conditions.
- By applying machine learning techniques to NIR and property data, we aim to enable accurate, data-driven prediction and optimization of wheat blends.
Methodology
Develop and evaluate classification and regression models that learn to predict wheat blend ratios from NIR spectral data and physical property measurements.
Development of a model for predicting the physical properties of flour
[2025.03.01 ~ 2026.02.28, Samyang Company]Objective
Develop a model that predicts the key physical properties of flour based on the blending ratios and physical characteristics of imported wheat used during production.
Motivation
- The quality and usability of flour are directly affected by its physical properties, which vary depending on the wheat blend.
- Traditional quality assessment relies on post-production physical testing, which is time-consuming and cost-inefficient.
- There is a growing need for a predictive system that can estimate flour properties prior to production to enhance process efficiency.
- Machine learning models trained on wheat composition and historical physical data can offer a scalable solution for this prediction task.
Methodology
Utilize regression-based machine learning techniques to learn the mapping between wheat blend input variables and target flour properties, using a tabular dataset consisting of historical measurements and blend compositions.
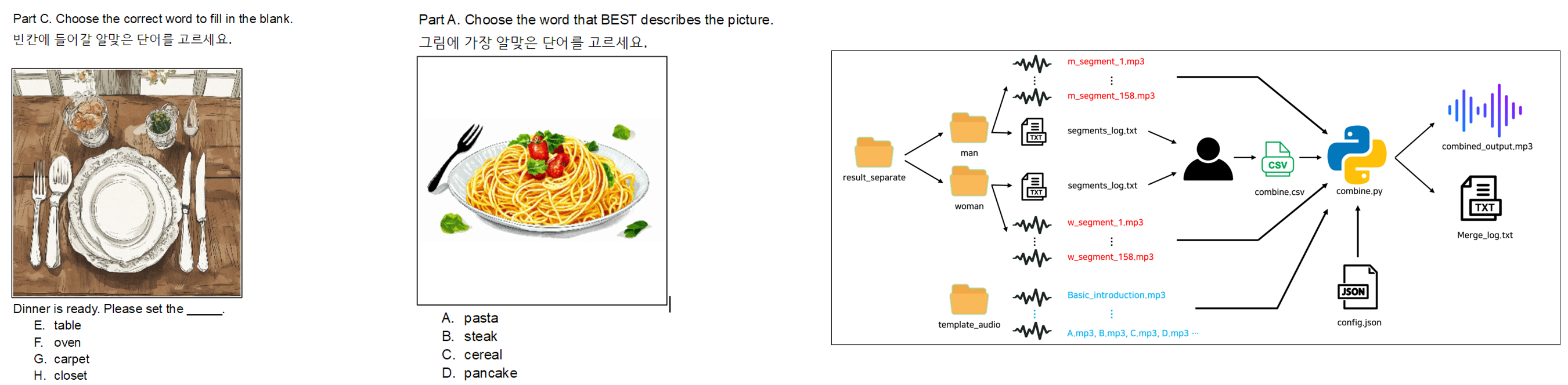
English problem generation algorithm based on large language models (LLMs)
[2025.03.01 ~ 2026.02.28, EDU TOSEL]Objective
The goal is to leverage LLM to generate different types of English problems and advance problem quality.
- The Need for Auto-Generation of Multiple-Choice Questions (MCQs)
Generating multiple questions for exams by instructors or teachers consumes a significant amount of time. It is very challenging to generate questions that reflect individual differences in skill levels.
- Existing Issues with Auto-Generation of Multiple-Choice Questions
When generating questions using language models, the types are fixed during training and generation, leading to a lack of flexibility in question formats. Questions are generated without reflecting the difficulty level based on the examinee’s proficiency.
- Method
We study problem quality advancement without constraints from all methodologies, including Prompt Engineering, RAG, and Fine-Tuning.

Question Generation Model Research Based on Artificial Intelligence
[2024.09.01 ~ 2025.08.31, EDU TOSEL]Objective
The goal is to develop an English problem generation platform that can handle text, image, and speech data using generative ai, and conduct research to advance problem quality.
- (Text) English Vocabulary Question Generation Framework
Using the Llama 3.1-8B model and GPT-API, this framework creates high-quality TOSEL-aligned questions through optimized prompts and staged processes. Post-processing ensures consistency.
- (Image) Personalized Image and Question Generation Framework
Combines fixed-frame images from AuraFlow-v0.3 with Llama 3.1-8B-generated questions. The LLaVA model integrates text and visuals for personalized, multimodal content.
- (Speech) Automated Framework for English Listening Tests
Segments and logs voice data using deep learning, then automatically merges it to meet listening test standards.
Battlefield Situation and Data Simulation Technology
[2021-02-16 ~ 2022-11-30, National Defense Research Institute]Objective
Develop a deep learning model that can generate unstructured simulation reports using structured simulation battlefield data.
- Recently, many studies have been conducted to develop an intelligent battlefield recognition system in the military.
- However, it is difficult to collect data for training.
- In particular, there is a limitation in directly annotating reports generated through war games in the military. Therefore, it is intended to develop a deep learning model that generates a report from log data generated through war game simulation.
Data
Develop a deep learning model that can generate unstructured simulation reports using structured simulation battlefield data.
- Recently, many studies have been conducted to develop an intelligent battlefield recognition system in the military.

Related Work
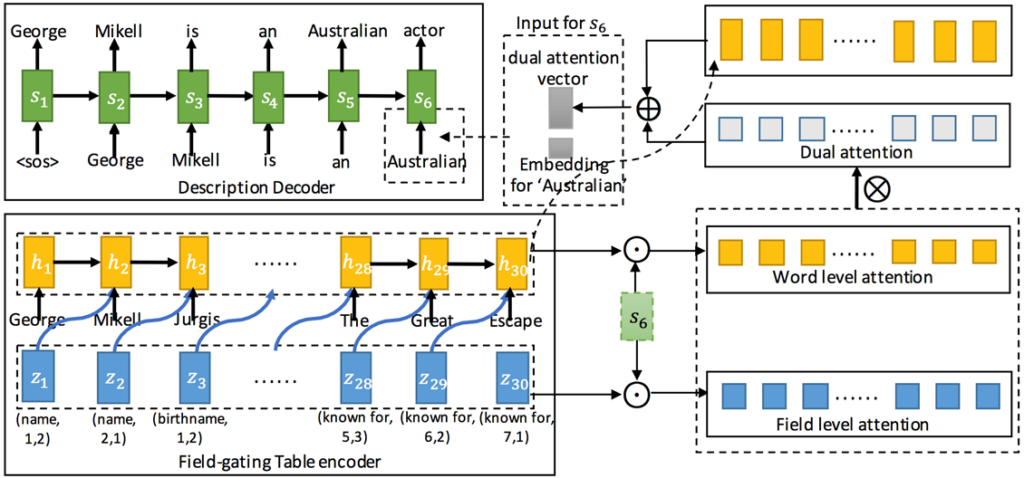
1.Table-to-text Generation by Structure-aware Seq2seq Learning
- In the encoding phase, they utilized the value-field as well as the postion, and proposed a modified encoder, the field-gate encoder.
- In the decoding phase, Dual attention multiplied by word-level attention and field-level attention significantly improved performance.
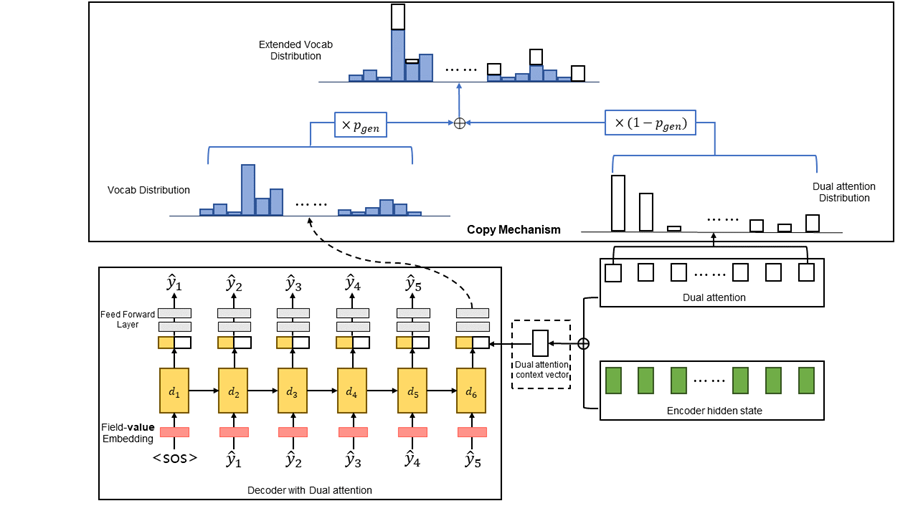
Proposed Method
Dual attention Seq2Seq with Copy mechanism
- Previous studies have proposed replacing “unk” token with attention distribution as a solution to the OOV(out-of-vocabulary) problem.
- However, this is a method that only applies if print out “unk” token.
- Therefore, we propose a model applying Copy mechanism so that even words that are not in the vocabulary can be output.
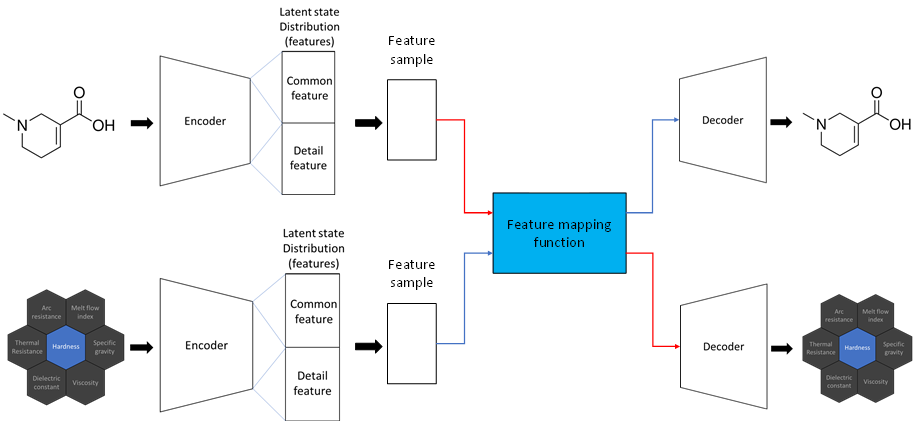
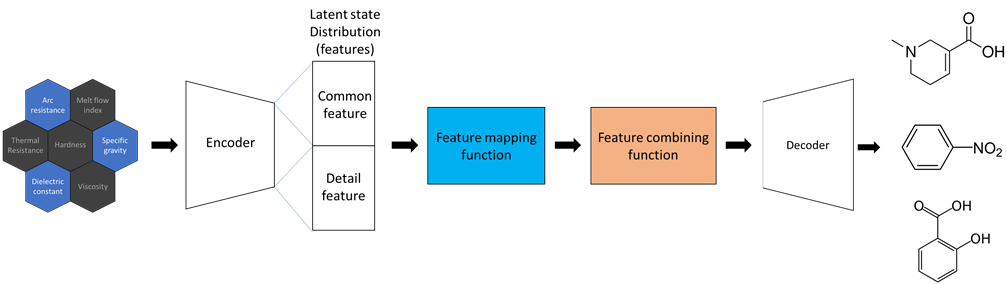
Artificial Intelligence Research for Monomer Design
[2021-08-01 ~ 2023-07-31, Samyang]Research Goal: to develop an artificial intelligence technology to design polymer with desired properties and create a structure-property database.
(1) Created a property database by collecting polymer data from public databases and literature.
- Analyzed properties of each database and developed an auto-collecting tool for easy and fast collection. The auto-collecting tool can collect data that is updated later.
(2) Developed an artificial intelligence technology to analyze the relationship between molecule structures and properties.
- Developed a new line notation for organic compounds and created a dataset that is required to train the artificial intelligence model.

(3) Explored the latent space to find a relationship between molecule structures and properties.
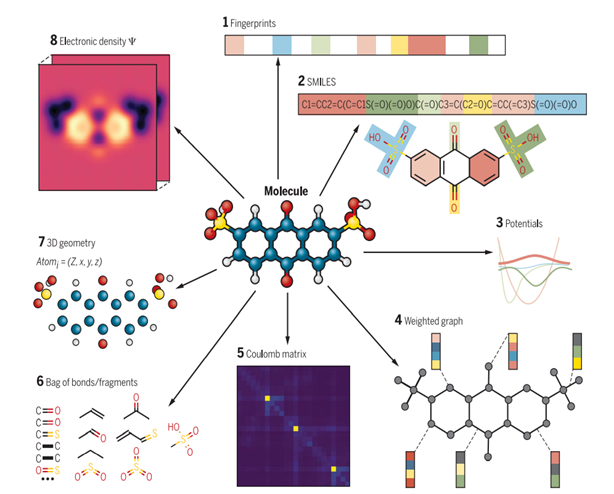
- Exploring latent space that represents correlations within properties allows property analysis with low computational costs.
- Attempted to apply VAE (Variational Auto Encoder)
(4) Generative Model-based Structure Prediction
- Developed an artificial intelligence technology that predicts molecule structures with desired properties.
Development of AI-based Project Delay Risk Preview System
[2021-05-20 ~ 2021-10-31, Hyundai NGV, Hyundai Motor Company]Objective
In the construction industry, the construction process is managed based on the completed construction in comparison to the planned construction. With the current construction management system, it is difficult to respond to construction delays in advance, because the construction process rate cannot be estimated quantitatively.
Data
Time Series Construction Data, Weather Forecast Data, Construction Budget Data, Extra-Budgetary Report Data, Subcontractor Data
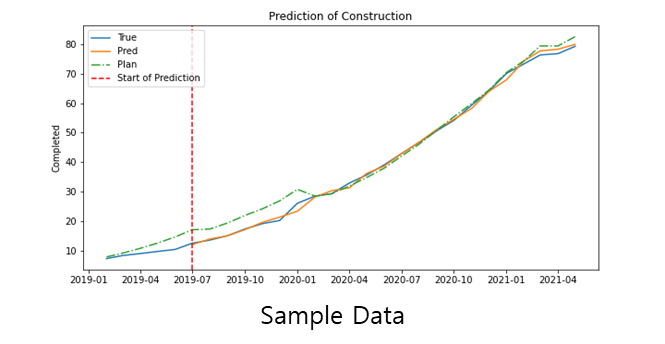
Related Work
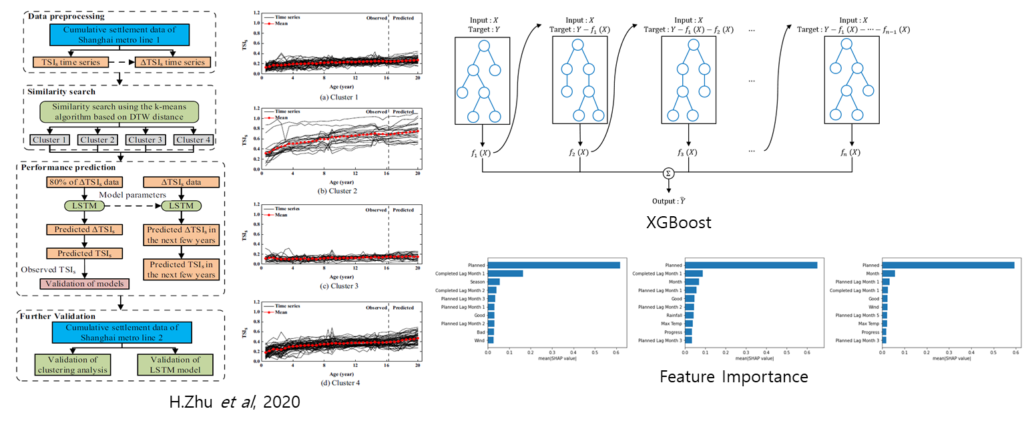
Similarity search and performance prediction of shield tunnels in operation through time series data mining (H.Zhu et al, Automation in Construction, 2020)
Proposed Method
In this paper, we developed an AI-based warning system that proactively predicts the delay in construction based on the completed construction of the past and additional data such as budget, subcontractor, and weather data.
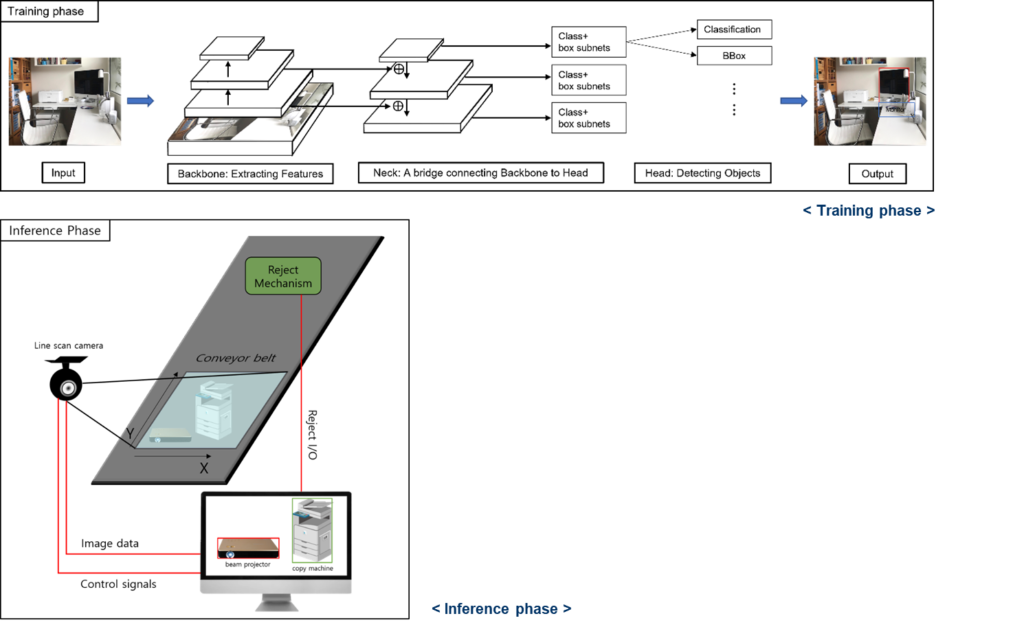
Real-time Object Detection for Lithium Battery
[2021-06-28 ~ 2021-12-09, Korea Electronics Recycling Cooperative]Objective
Lithium battery includes harmful metals (lead, mercury, etc.). Thus, collecting eco-friendly resources and managing hazardous materials are required during the discharge process. We propose a deep learning-based pipeline to select products containing the lithium battery among waste electrical and electronic products on a conveyor belt.
Data

Related Work
Related work: This study aims at the problem that mining conveyor belts are easily damaged under severe working conditions, based on the reclassification and definition of conveyor belt damage types. Conveyor belt damage is detected by the improved Yolov3 algorithm, which considers the impact of model scaling on the detection results [Zhang et al., 2021].

Proposed Method
We trained Electronic and Electronical data based on YOLOv4 with CSPDarknet53 as the backbone and made the pipeline for detecting products containing the lithium battery on a conveyor belt. When waste electrical and electronic products move on a conveyor belt, a line scan camera detects the product, if the product is a lithium battery product. Then, the network signal the reject device to select the product.
Research on Artificial Intelligence Writing Technology Using Natural Language Processing
[2021-07-01 ~ 2021-12-31, Mania Mind (Research collaboration project) ]Objective
Development of Novel Writing Platform based on “user input” through learning of various novel genres.
Data
KoGPT2 fine tuning is performed using novel text data. In the case of Semantic Role Labeling, we use ETRI Semantic Role Labeling Corpus for training SRL model.

Related Work
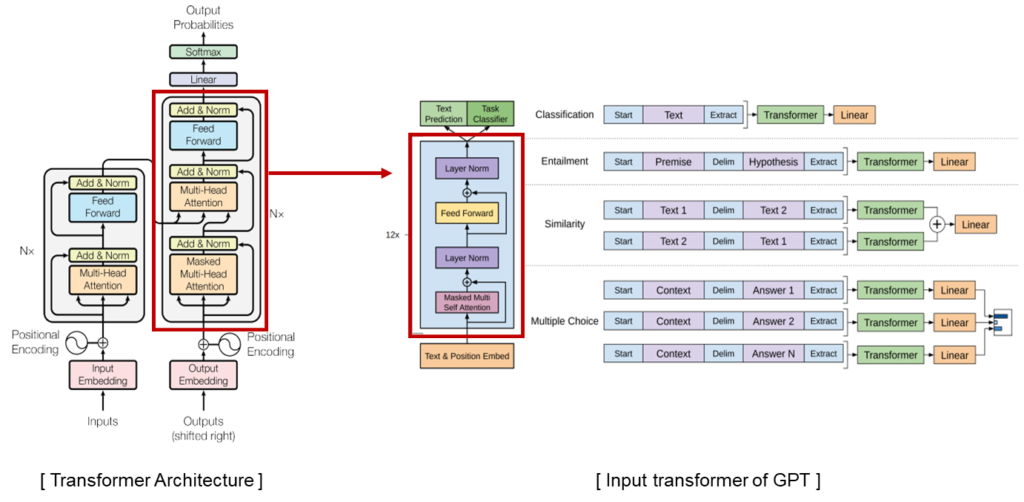
KoGPT2 is a pretrained language model and optimized for sentence generation so that the next word in a given text can be well predicted. KoGPT2 is a transformer decoder language model that has been learned with more than 40GB of text to overcome insufficient Korean performance.
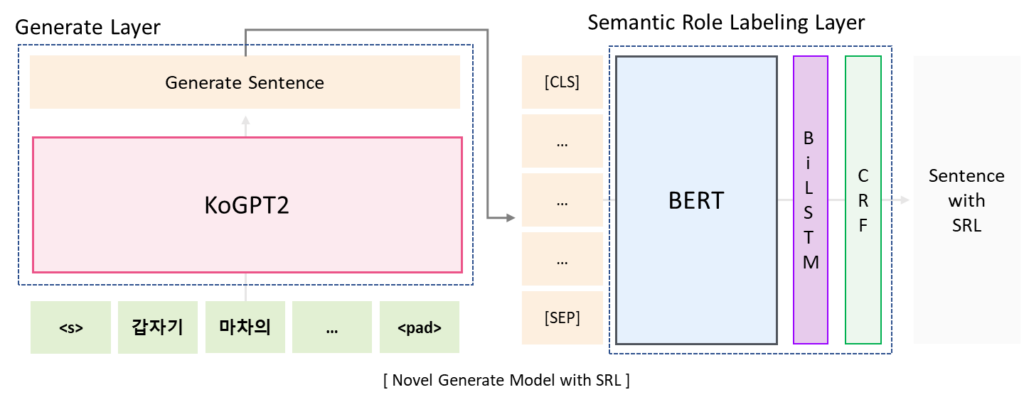
Proposed Method
It is a structure that combines Generate Layer for novel generation and SRL Layer for reflecting user input. When a sentence is entered, the following sentence is generated through KoGPT2 and the generated sentence is corrected through SRL layer.
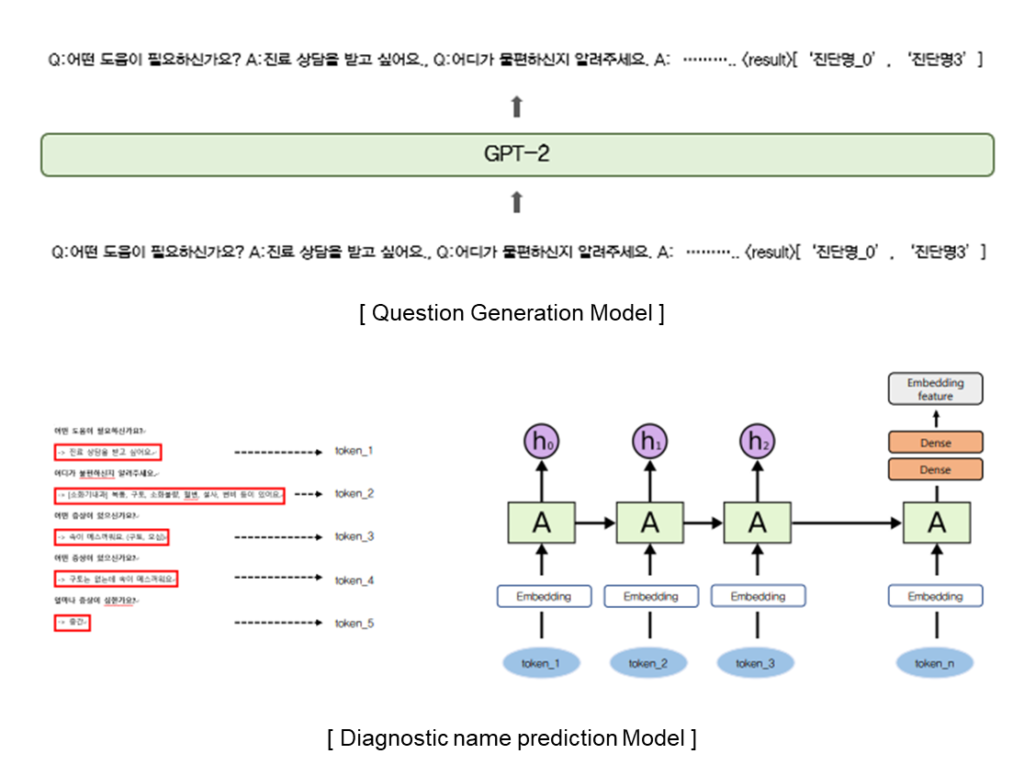
AI consultation chatbot
[2021-07-01 ~ 2021-12-31, Korea University Anam Hospital (Research collaboration project)]Objective
Development of a consultation AI chatbot for providing telemedicine counseling solutions
Data
EMR dataset was used for training the chatbot model.
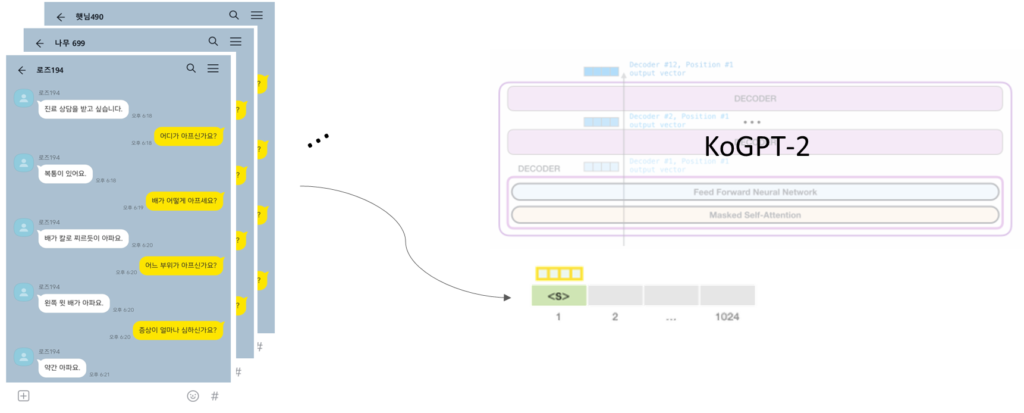
Related Work
GPT-2 is a pretrained language model and optimized for sentence generation so that the next word in a given text can be well predicted. GPT-2 is a transformer decoder language model that has been learned with more than 40GB of text to overcome insufficient Korean performance.
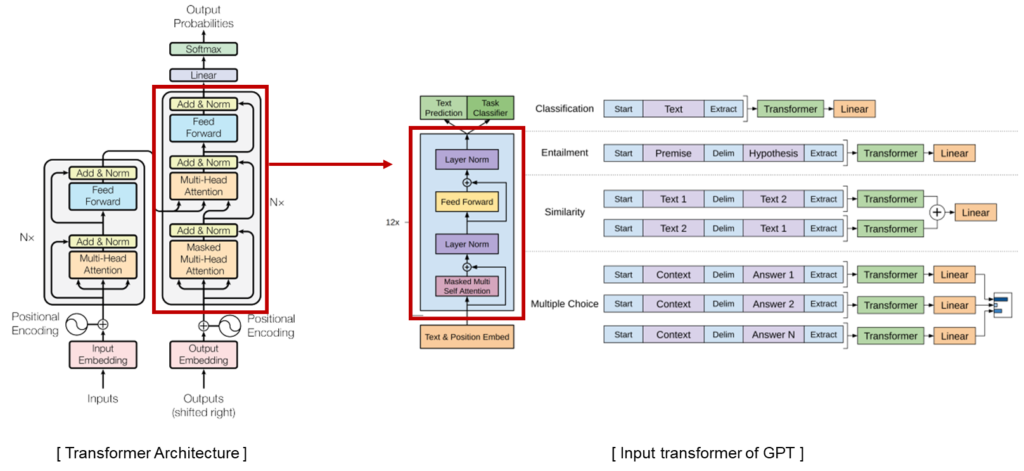
Proposed Method
A Sequence consists of a list of questions and answers and a diagnostic name. It was used for fine-tuning GPT and predicting a diagnostic name. Therefore, it is possible to generate appropriate questions about the patient’s answers and finally predict the diagnostic name.