Deep Learning – Speaker Verification
Universal Pooling Method of Multi-layer Features from Pretrained Models for Speaker Verification
Objective
Recent advancements in automatic speaker verification (ASV) studies have been achieved by leveraging large-scale pre-trained networks. In this study, we analyze the approaches toward such a paradigm and underline the significance of interlayer information processing as a result. Accordingly, we present a novel backend model that comprises a layer/frame-level network and two steps of pooling architectures for each layer and frame axis.
Data
We use the CSTR VCTK corpus [1], LibriSpeech [2], and VoxCelebs [3, 4] datasets, diversifying the experimental setups of high-low resource and auditorial recording environments.
[1] J. Yamagishi et al., “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)”, 2019.
[2] V. Panayotov et al., “LibriSpeech: an ASR corpus based on public domain audio books”, 2015.
[3] A. Nagrani et al., “VoxCeleb: A large-scale speaker identification dataset,” 2017.
[4] J. S. Chung et al., “VoxCeleb2: Deep speaker recognition,”, 2018
Related Work
ECAPA-TDNN [5] has been developed based on SE-Res2Net [6] topology for acoustic feature processing. WavLM [7] incorporates ECAPA-TDNN to process the pre-trained model output, which led to achieving state-of-the-art verification performance in the VoxCeleb benchmark. Meanwhile, D3Net [8] proposes an architecture that can avoid the creation of blind spots in dilated-convolutional dense connections.
ChemBERTa [2] predicts masked tokens to acquire SMILES representations, GROVER [3] focuses on predicting masked atom or bond attributes to learn molecular graphs.
MolCLR [4] introduced contrastive learning with graph-based augmentations, enhancing molecular graphs by randomly masking atoms or deleting bonds before computing contrastive loss.
[6] S. Gao et al., “Res2Net: A new multi-scale backbone architecture”, 2019.
[7] S. Chen et al., “WavLM: Large-scale self-supervised pre-training for full stack speech processing” , 2022.
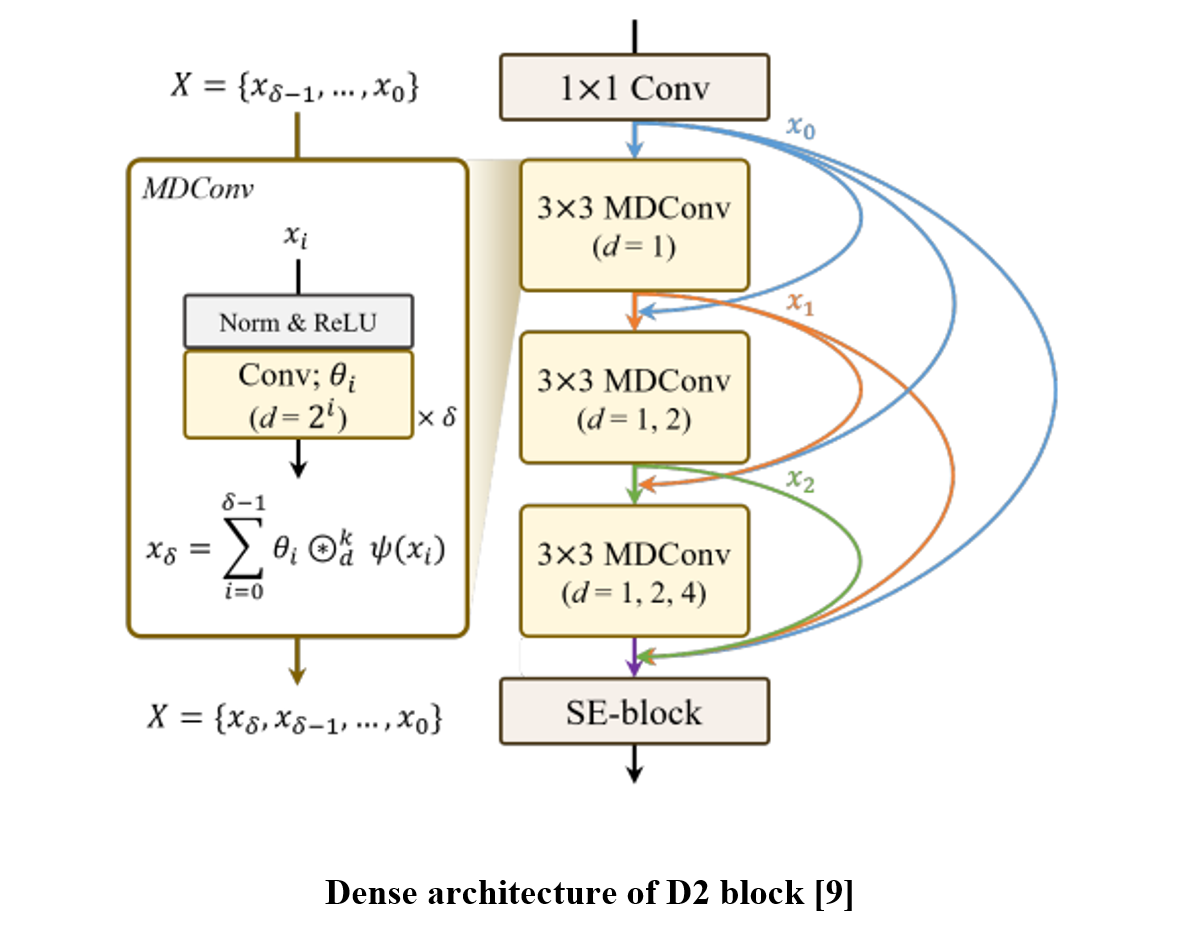
[8] N. Takahashi et al., “Densely connected multi-dilated convolutional networks for dense prediction tasks”, 2021.
[9] J. S. Kim et al., “Universal pooling method of multi-layer features from pretrained models for speaker verification”, 2024.
Proposed Method
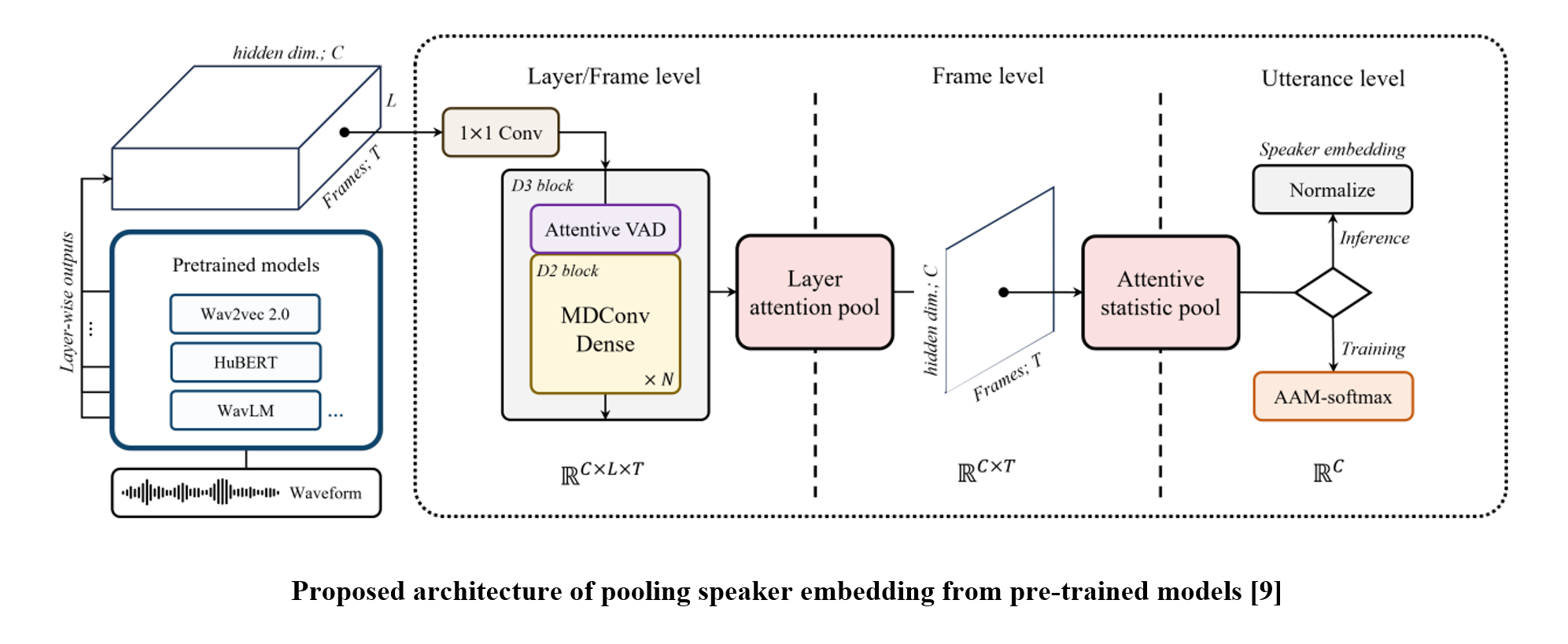
In this paper, we propose a backend module that extracts speaker embeddings from pre-trained model output in three steps: layer/frame-level processing network, layer attentive pooling, and attentive statistic pooling. We adopt D3Net to process multiple hidden states of the pre-trained model, hence creating more speaker-representative features from adjacent relationships between layer- and frame-wise information. Then, two attentive poolings follow which are applied for layer and frame-wise aggregation, respectively. The layer-pooling comprises Squeeze-Excitation [10]-based significance scoring and max-pooling, and we follow the temporal aggregation strategy introduced in ECAPA-TDNN.
[10] J. Hu et al., “Squeeze-and-Excitation networks”, 2018.
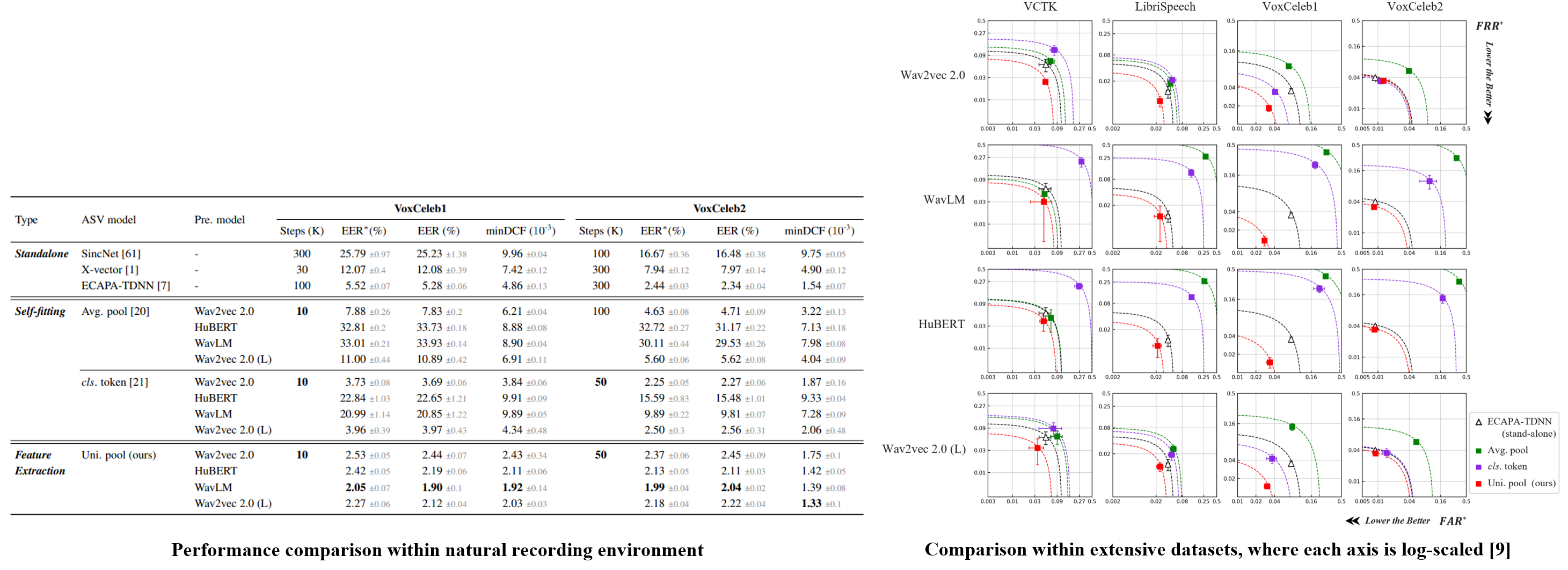
We conducted experiments on various data environments, leveraging popular pre-trained Transformer networks. We compare the proposed method with two approaches of fine-tuning pre-trained models to perform speaker verification, yet our methodology involves freezing the pre-trained weights since employing the pre-trained model as a feature extractor.
The results show that the proposed backend outperforms the others despite training fewer parameters, demonstrating that the benefits of pretraining can be further maximized given the context of fewer data resources and a natural speech environment such as VoxCeleb 1.
However, the fine-tuning methods showed high sensitivities and were difficult to apply to pre-trained models other than the wav2vec 2.0.