Deep Learning – Audio Captioning
Rethinking Transfer and Auxiliary Learning for improving Audio Captioning Transformer
Objective
Automated audio captioning (AAC) is the automatic generation of contextual descriptions of audio clips. An audio captioning transformer (ACT) that achieved state-of-the-art performance on the AudioCaps dataset was proposed. However, the performance gain of ACT is still limited owing to the following two problems: discrepancy in the patch size and lack of relations between inputs and captions. We propose two strategies to improve the performance of transformer-based networks in AAC.
Data
The AudioCaps dataset [1], the largest audio captioning dataset including approximately 50k audio samples obtained from AudioSet and human-annotated descriptions, is used for validation.
[1] Kim C.D., et al., “Audiocaps: Generating captions for audios in the wild”, 2019
Related Work
Mei et al. [2] proposed a full transformer structure called an audio captioning transformer (ACT) that achieved state-of-the-art performance on the AudioCaps dataset.
One method for strengthening the relationship with local-level labels is to add a keyword estimation branch to the AAC framework [3].
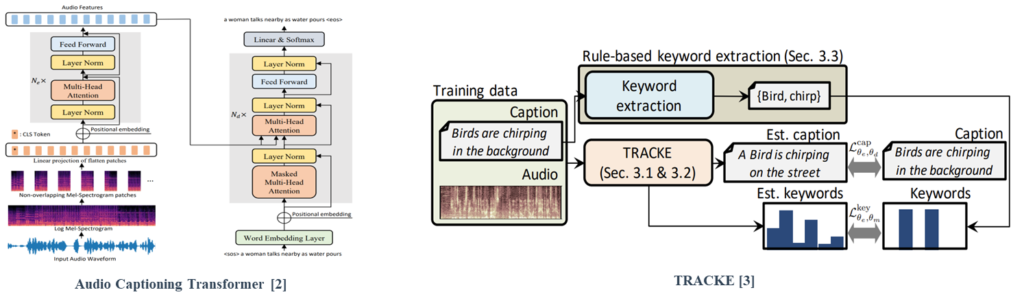
[3] Koizumi, Yuma, et al., “A Transformer-based Audio Captioning Model with Keyword Estimation”, 2020
Proposed Method
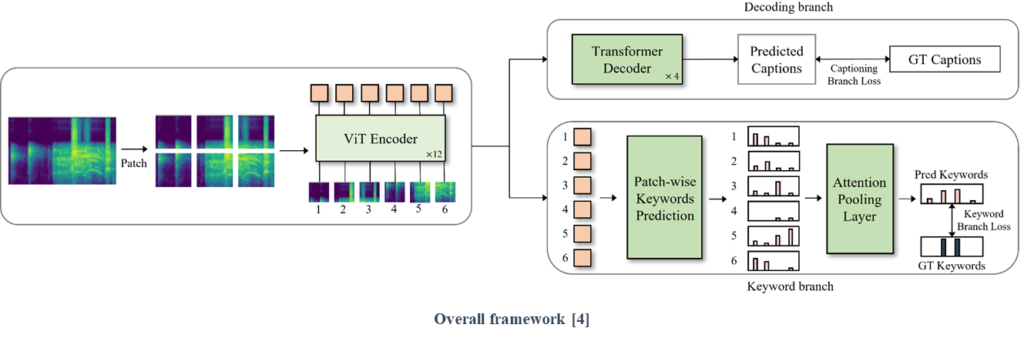
(1) We propose a training strategy that prevents discrepancies resulting from the difference in input patch size between the pretraining and fine-tuning steps.
(2) We suggest a patch-wise keyword estimation branch that utilizes attention-based pooling to adequately detect local-level information.
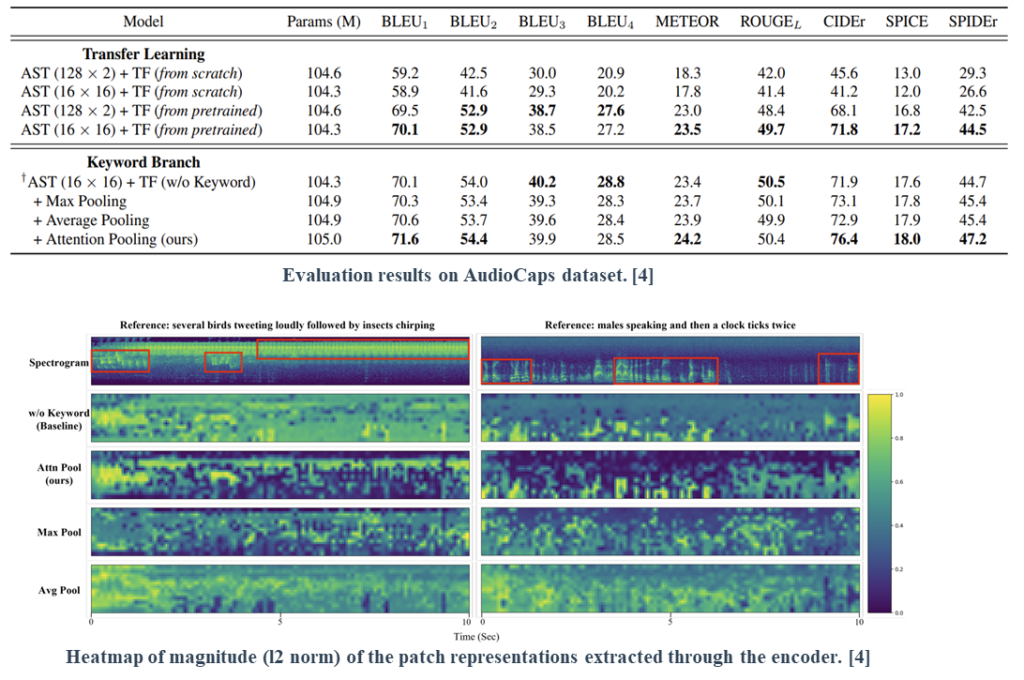
The results on transfer learning suggest that although preserving the frequency-axis information can be crucial, it does not fully leverage the benefits offered by pretrained knowledge.
The results on the keyword branch suggest that the proposed attention-based pooling provides proper information that benefits AAC systems by adequately detecting local-level events.
Finally, we visually verified the effectiveness of the proposed keyword estimation pooling method. The results reveal that the proposed method effectively detects local-level information with minimal false positives compared to other methods.