Deep Learning – Sound Event Localization and Detection
AD-YOLO: You Look Only Once in Training Multiple Sound Event Localization and Detection
Objective
Given a multi-channel audio input, sound event localization and detection (SELD) combines sound event detection (SED) along the temporal progression and the identification of the direction-of-arrival (DOA) of the corresponding sounds. Several prior works proposed methods to train deep neural networks by representing targets in event/track-oriented approaches. However, the event-oriented track output formats intrinsically contain the limitation of presetting the number of tracks, constraining the generality and expandability of the method itself.
Data
A series of development sets of DCASE Task 3 from 2020 to 2022 [1, 2, 3] are used. In addition, the simulated acoustic scenes to train 2022 baseline [4] is also exploited.
[1] A. Politis, S. Adavanne, and T. Virtanen, “A dataset of reverberant spatial sound scenes with moving sources for sound event localization and detection,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), Tokyo, Japan, November 2020, pp. 165–169. [Online]. Available: https: //dcase.community/workshop2020/proceedings
[2] A. Politis, S. Adavanne, D. Krause, A. Deleforge, P. Srivastava, and T. Virtanen, “A dataset of dynamic reverberant sound scenes with directional interferers for sound event localization and detection,” in Proceedings of the 6th Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), Barcelona, Spain, November 2021, pp. 125–129. [Online]. Available: https://dcase.community/workshop2021/proceedings
[3] A. Politis, K. Shimada, P. Sudarsanam, S. Adavanne, D. Krause, Y. Koyama, N. Takahashi, S. Takahashi, Y. Mitsufuji, and T. Virtanen, “Starss22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events,” 2022. [Online]. Available: https://arxiv.org/abs/2206.01948
[4] [DCASE2022 Task 3] Synthetic SELD mixtures for baseline training, [Online]. Available: 10.5281/zenodo.6406873
Related Work
[5] SELDnet have adopted a two-branch output format, considering SELD as the performing of two separate sub-tasks from each branch, SED and DOA (SED-DOA) [6, 7] solve the task in a single-branch output through a Cartesian unit vector (proposed as ACCDOA [11]), combining SED and DOA representations, where the zero-vector represents none.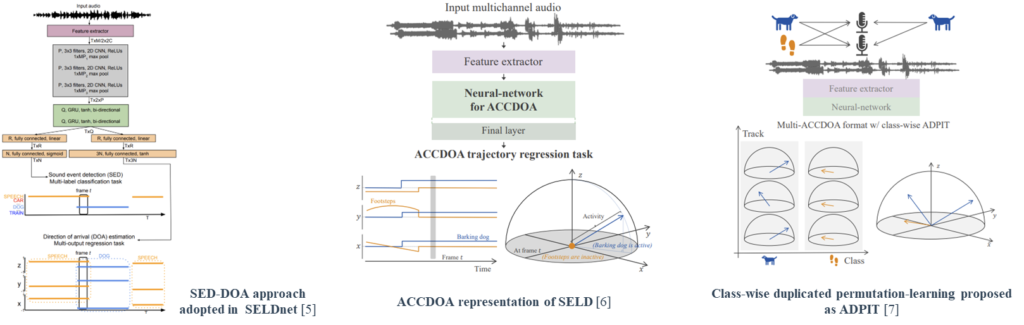
[5] S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,” IEEE JSTSP, vol. 13, no. 1, pp. 34–48, 2018.
[6] K. Shimada, Y. Koyama, N. Takahashi, S. Takahashi, and Y. Mitsufuji, “Accdoa: Activity-coupled cartesian direction of arrival representation for sound event localization and detection,” in Proc. of IEEE ICASSP, 2021, pp. 915–919.
[7] K. Shimada, Y. Koyama, S. Takahashi, N. Takahashi, E. Tsunoo, and Y. Mitsufuji, “Multi-accdoa: Localizing and detecting overlapping sounds from the same class with auxiliary duplicating permutation invariant training,” in Proc. of IEEE ICASSP, 2022, pp. 316–320.
Proposed Method
We proposed an angular-distance-based YOLO (AD-YOLO) approach to perform sound event localization and detection (SELD) on a spherical surface. AD-YOLO assigns multilayered responsibilities, which are based on the angular distance from the target events, to predictions according to each estimated direction of arrival. Avoiding the primal format of the event-oriented track output, AD-YOLO addresses the SELD problem in an unknown polyphony environment.
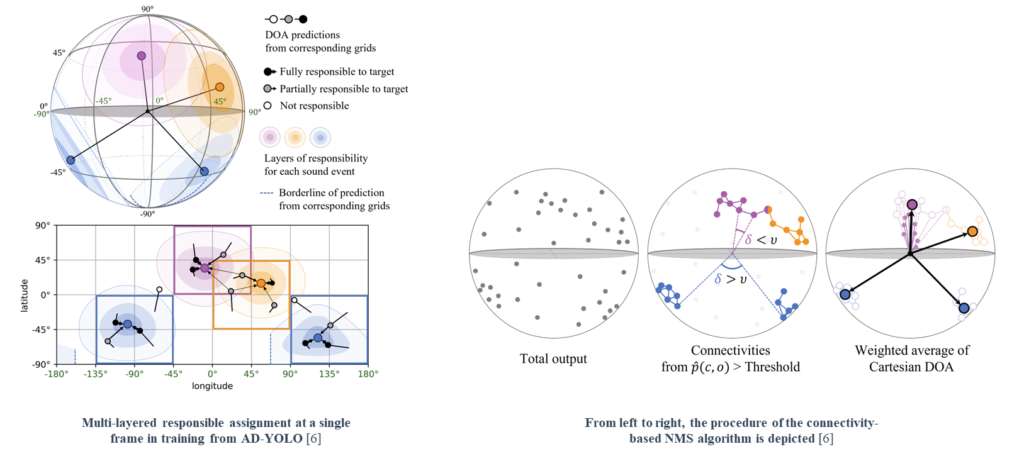
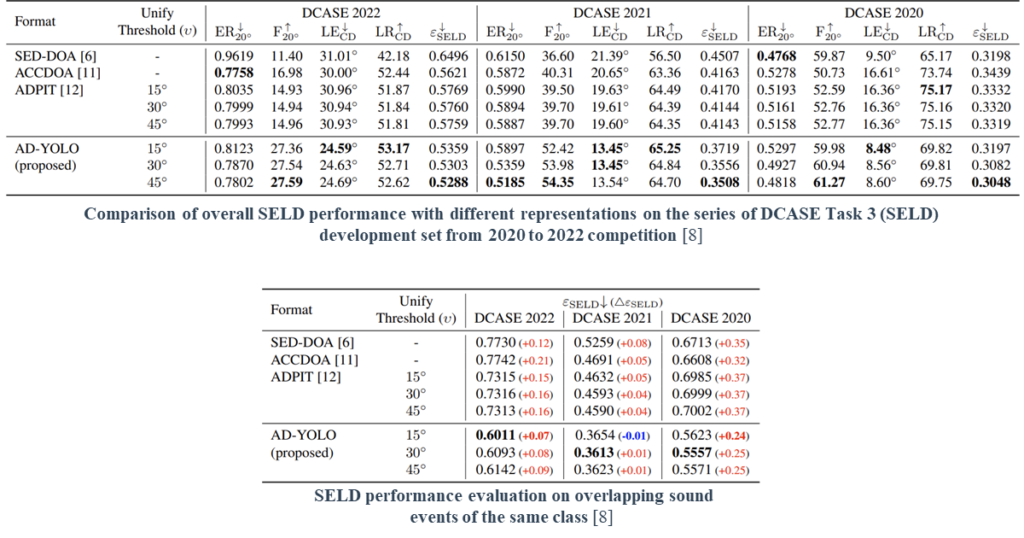
We evaluate several existing formats handling the SELD problem using the same backbone network. The model trained in AD-YOLO format achieves the lowest SELD-error (ε_SELD) from all setups. In particular, AD-YOLO outperformed the other approaches in terms of F_(20°) and LE_CD evaluation metrics.
AD-YOLO proves robustness in class-homogeneous polyphony by the minimum performance degradation (Δε_SELD) compared to the overall evaluation.
A Robust Framework for Sound Event Localization and Detection on Real Recordings
Objective
We address the sound event localization and detection (SELD) problem, of one held at the IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) in 2022. The task aims identification of both the sound-event occurrence (SED) and the direction of arrival from the sound source (DOA). However, by allowing large external datasets and giving small real recordings, the challenge also encompasses a key issue of exploiting synthetic acoustic scenes to perform SELD well in the real world.
Data
STARSS22 [1] is in public for the 2022 challenge, comprising real-world recording and label pairs that were man-annotated. To synthesize emulated sound scenarios from the external data, we use class-wise audio samples extracted from seven external datasets, which are AudioSet [2], FSD50K [3], DCASE2020 and 2021 SELD datasets [4, 5], ESC-50 [6], IRMAS [7], and Wearable SELD [8]. As the same way in former SELD task challenges, extracted audio samples are synthesized through SRIR and SNoise from TAU-SRIR DB [9] emulating the spatial sound environment.
[1] A. Politis, K. Shimada, P. Sudarsanam, S. Adavanne, D. Krause, Y. Koyama, N. Takahashi, S. Takahashi, Y. Mitsufuji, and T. Virtanen, “Starss22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events,” 2022. [Online]. Available: https://arxiv.org/abs/2206.01948
[2] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in Proc. IEEE ICASSP 2017, New Orleans, LA, 2017.
[3] E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “FSD50K: an open dataset of human-labeled sound events,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 829–852, 2022.
[4] A. Politis, S. Adavanne, and T. Virtanen, “A dataset of reverberant spatial sound scenes with moving sources for sound event localization and detection,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), Tokyo, Japan, November 2020, pp. 165–169. [Online]. Available: https: //dcase.community/workshop2020/proceedings
[5] A. Politis, S. Adavanne, D. Krause, A. Deleforge, P. Srivastava, and T. Virtanen, “A dataset of dynamic reverberant sound scenes with directional interferers for sound event localization and detection,” in Proceedings of the 6th Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), Barcelona, Spain, November 2021, pp. 125–129. [Online]. Available: https://dcase.community/workshop2021/proceedings
[6] K. J. Piczak, “ESC: Dataset for Environmental Sound Classification,” in Proceedings of the 23rd Annual ACM Conference on Multimedia. ACM Press, pp. 1015– 1018. [Online]. Available: http://dl.acm.org/citation.cfm? doid=2733373.2806390
[7] J. J. Bosch, F. Fuhrmann, and P. Herrera, “IRMAS: a dataset for instrument recognition in musical audio signals,” Sept. 2014. [Online]. Available: https://doi.org/10.5281/zenodo. 1290750
[8] K. Nagatomo, M. Yasuda, K. Yatabe, S. Saito, and Y. Oikawa, “Wearable seld dataset: Dataset for sound event localization and detection using wearable devices around head,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 156–160.
[9] A. Politis, S. Adavanne, and T. Virtanen, “TAU Spatial Room Impulse Response Database (TAU- SRIR DB),” Apr. 2022. [Online]. Available: https://doi.org/10.5281/zenodo.6408611
Related Work
SELDnet [10] established the basic neural network structure to perform SELD, which comprises the layers processing multichannel spectrogram input (2D CNN) followed by sequential processing layers (Bi-GRU) and lastly, fully-connected linear layers.
The squeeze-and-excitation residual networks [11] (SE-ResNet) have recently been applied to audio classification [12, 13], as the SELD encoder.
[14] proposed the method of rotating the sound direction of arrival as the data-augmentation for SELD.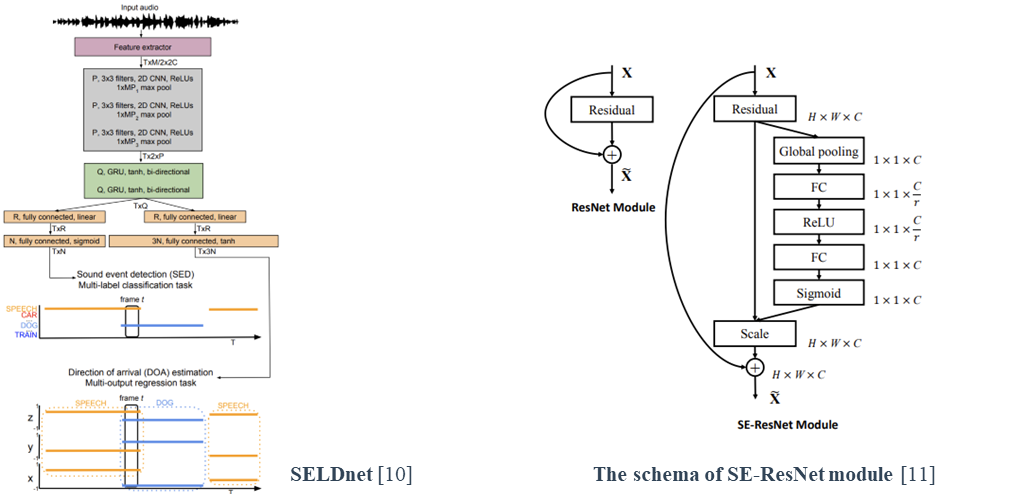
[10] S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,” IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 1, pp. 34–48, 2018.
[11] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141.
[12] J. H. Yang, N. K. Kim, and H. K. Kim, “Se-resnet with ganbased data augmentation applied to acoustic scene classification,” in DCASE 2018 workshop, 2018.
[13] H. Shim, J. Kim, J. Jung, and H.-j. Yu, “Audio tagging and deep architectures for acoustic scene classification: Uos submission for the dcase 2020 challenge,” Proceedings of the DCASE2020 Challenge, Virtually, pp. 2–4, 2020.
[14] L. Mazzon, Y. Koizumi, M. Yasuda, and N. Harada, “First order ambisonics domain spatial augmentation for dnn-based direction of arrival estimation,” arXiv preprint arXiv:1910.04388, 2019.
Proposed Method
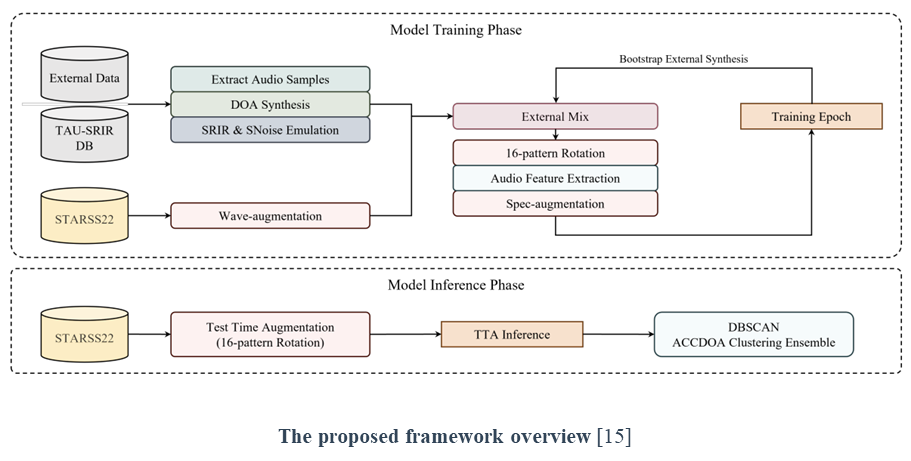
To keep the model fit in real-world scenario contexts while taking advantage of various audio samples from external datasets, a dataset mixing technique (External Mix) is adopted to consist model training dataset. The technique balances the size of each dataset on the model training phase, between the small real recording set and the large emulated scenarios.
A test time augmentation (TTA) is widely used in computer vision to increase the robustness and performance of models. On the other hand, the unknown number of events and the presence of coordinates information make it challenging to apply TTA on SELD. To utilize TTA on SELD, we propose a clustering-based aggregation method to obtain confident-predicted outputs and aggregate them. We take 16 pattern rotation augmentation for test time augmentation, making 16 predicted outputs, that is candidates. To obtain confident aggregated outputs, we use DBSCAN [16] for clustering candidates.
[15] J. S. Kim*, H. J. Park*, W. Shin*, and S. W. Han**, “A robust framework for sound event localization and detection on real recordings,” Tech. Rep., 3rd prize for Sound Event Localization and Detection, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE), 2022.
[16] M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al., “A densitybased algorithm for discovering clusters in large spatial databases with noise.” in kdd, vol. 96, no. 34, 1996, pp. 226– 231.
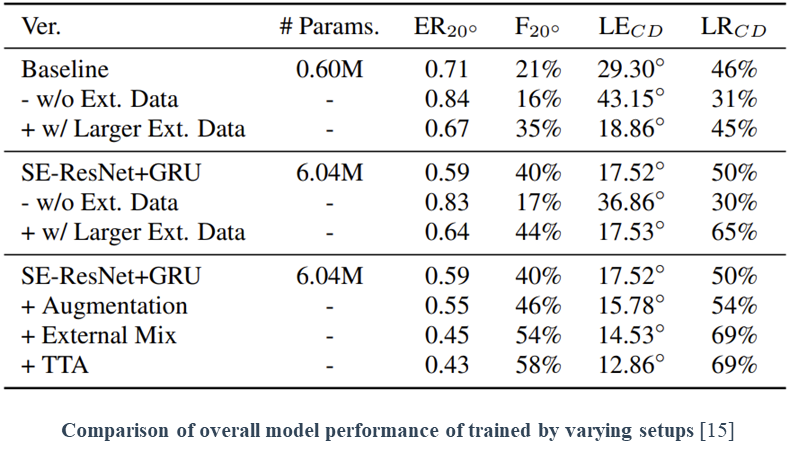
We validate the influence of the proposed framework in experiments. The second row (w/o Ext. Data) of both the first and second blocks is the result of only using small real-world recording data as the training set. As reported in the first rows at the first and second blocks, We observed that using emulated data (Baseline synthesized data [17]), simulated from FSD50K audio samples, enhances the performance of the same models. Concurrently, however, the third row (w/ Larger Ext. Data) of each shows that the addition of larger emulated soundscapes does not guarantee performance improvement.
In the last block, we found that significant improvements were obtained from three components (Augmentation, External Mix, and TTA). Among them, the external mix method contributed more to the performance improvement than the other methods.
[15] J. S. Kim*, H. J. Park*, W. Shin*, and S. W. Han**, “A robust framework for sound event localization and detection on real recordings,” Tech. Rep., 3rd prize for Sound Event Localization and Detection, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE), 2022.
[17] [DCASE2022 Task 3] Synthetic SELD mixtures for baseline training, [Online]. Available: 10.5281/zenodo.6406873