Deep Learning – Speech Synthesis
RapFlow-TTS: Rapid and High-Fidelity Text-to-Speech with Improved Consistency Flow Matching
Objective
Text-to-speech (TTS), also known as speech synthesis, aims to synthesize high-fidelity speech, given an input text. While previous Ordinary Differential Equations (ODE)-based TTS models, such as diffusion and flow matching, have demonstrated strong performance, they still suffer from slow inference due to the need for many generation steps. In this work, we propose RapFlow-TTS, which improves both inference efficiency and synthesis quality by leveraging consistency flow matching and enhanced training strategies.
Data
We use the LJSpeech [1] and VCTK [2] dataset which are single- and multi-speaker English corpus dataset.
[1] K. Ito and L. Johnson, “The LJ speech dataset,” https://keithito.com/LJ-Speech-Dataset/, 2017
[2] J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),” 2019
Related Work
Grad-TTS[3] is a diffusion-based approach that requires a large number of inference steps due to its complex ODE trajectories.
Matcha-TTS[4] mitigates this by leveraging flow matching to linearize the ODE paths, enabling high-quality speech synthesis with fewer inference steps. However, it still demands a considerable number of steps for generation.

[4] S. Mehta, R. Tu, J. Beskow, E. Sz ´ ekely, and G. E. Henter, “Matcha-TTS: A fast tts architecture with conditional flow matching,” in Proc. ICASSP, 2024, pp. 11 341–11 345
Proposed Method
RapFlow-TTS leverages both flow matching and the concept of consistency to learn consistency along linearized trajectories. Unlike previous methods, this enables high-quality speech synthesis with significantly fewer inference steps. In addition, RapFlow-TTS incorporates several enhanced strategies—such as time-delta scheduling, Huber loss, and adversarial learning—to further improve synthesis quality.
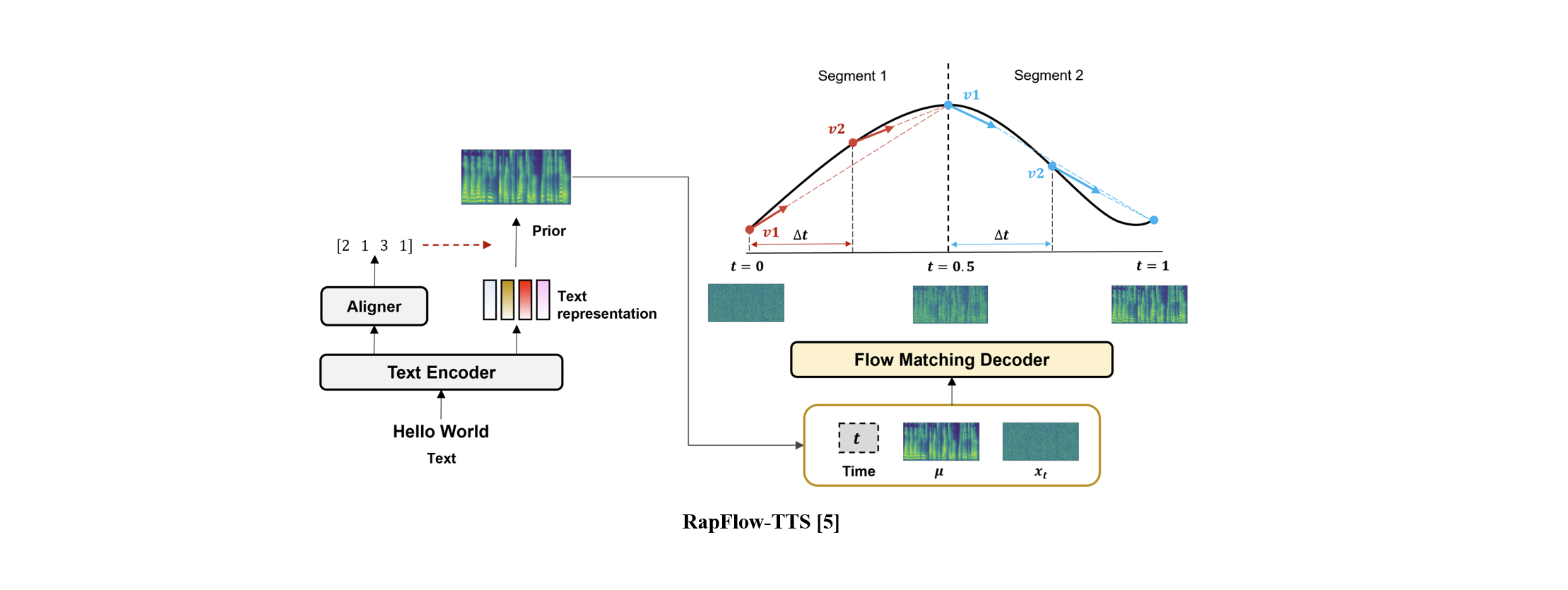
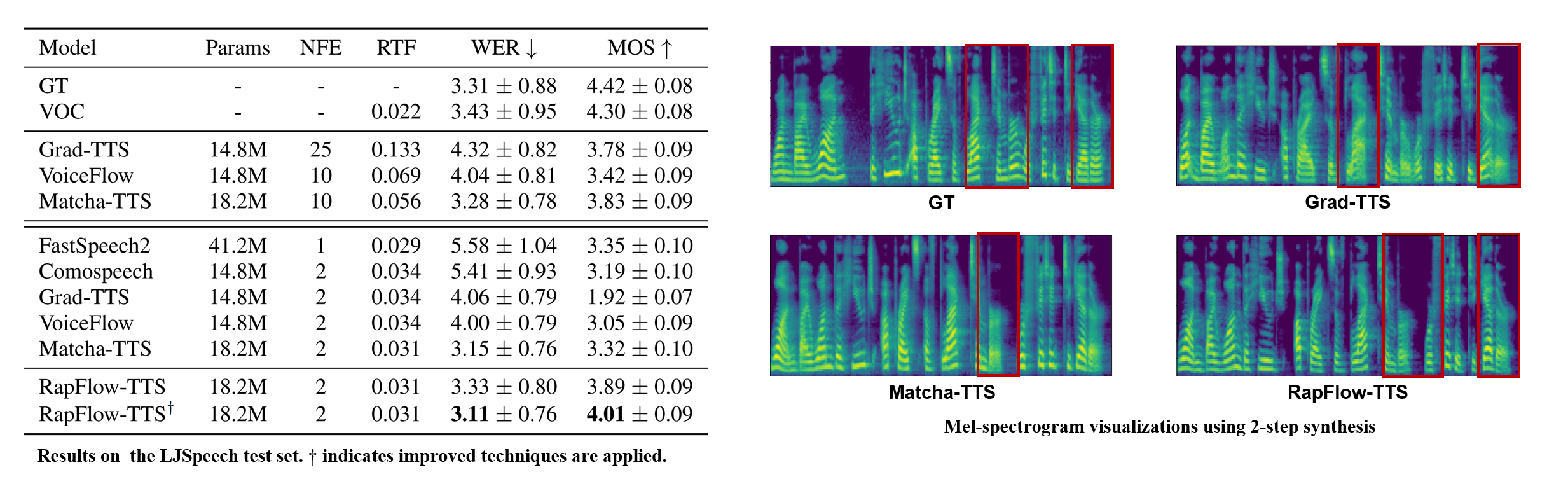
RapFlow-TTS achieves outstanding performance while requiring 5 to 10 times fewer inference steps compared to previous ODE-based models. Remarkably, it offers inference speed comparable to FastSpeech2, one of the fastest models available.
In summary, RapFlow-TTS synthesizes high-quality speech with fewer steps, enabled by consistency-based flow matching and improved training strategies, effectively overcoming the inference speed limitations of prior ODE-based TTS models.
Moreover, visualization of 2-step inference demonstrates that our method can generate detailed frequency representations even with extremely few steps.
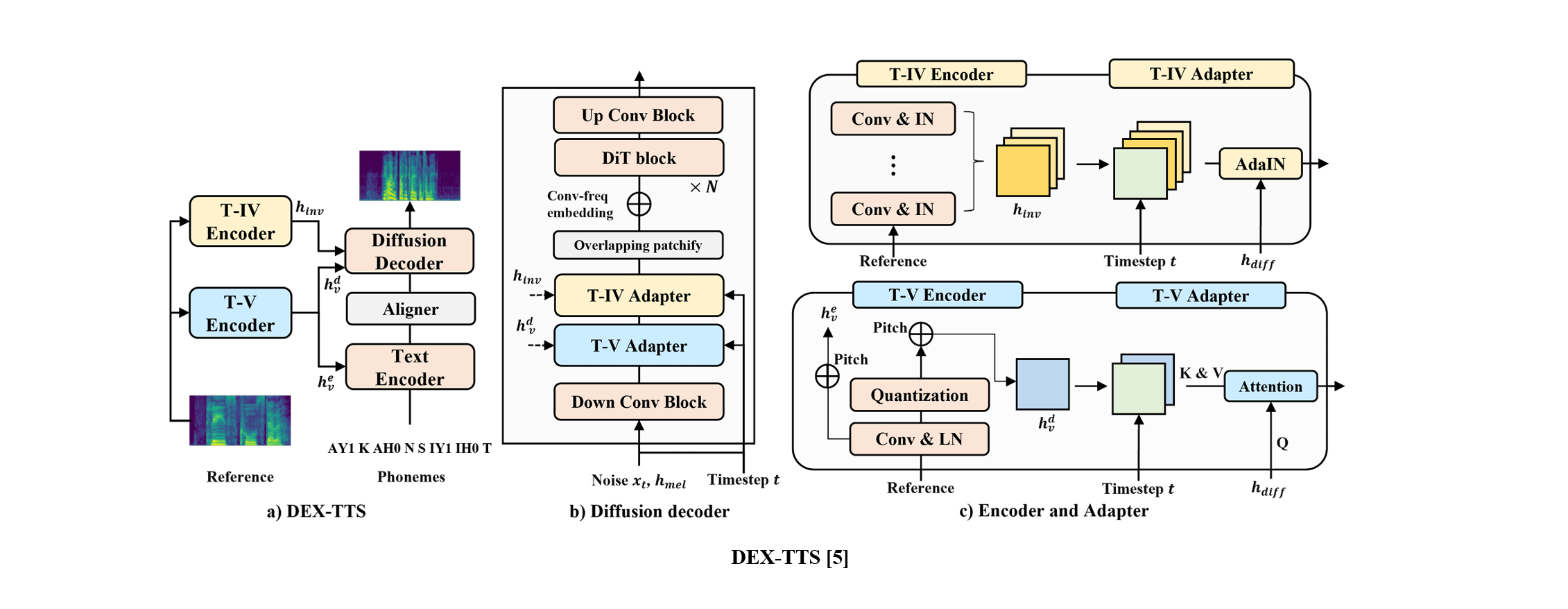
DEX-TTS: Diffusion-based EXpressive Text-to-Speech with Style Modeling on Time Variability
Objective
Reference-based TTS is the task of synthesizing more expressive and natural speech by representing style characteristics from a reference speech sample. To enhance style representation and generalization, we propose DEX-TTS which is a diffusion-based TTS model. DEX-TTS differentiates styles into time-invariant and time-variant categories. By designing encoders and adapters tailored to each style characteristic, rich style representation and high generalization can be achieved.
Data
We use the multi-speaker English dataset, VCTK [1], and emotional dataset, ESD [2].
[1] Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92). In University of Edinburgh. The Centre for Speech Technology Research (CSTR), 2019.
[2] Kun Zhou, Berrak Sisman, Rui Liu, and Haizhou Li. Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 920–924. IEEE, 2021.
Related Work
StyleTTS [3] adopted AdaIN for flexible style adaptation.
GenerSpeech [4] adopted a multi-level adapter for rich style adaptation.
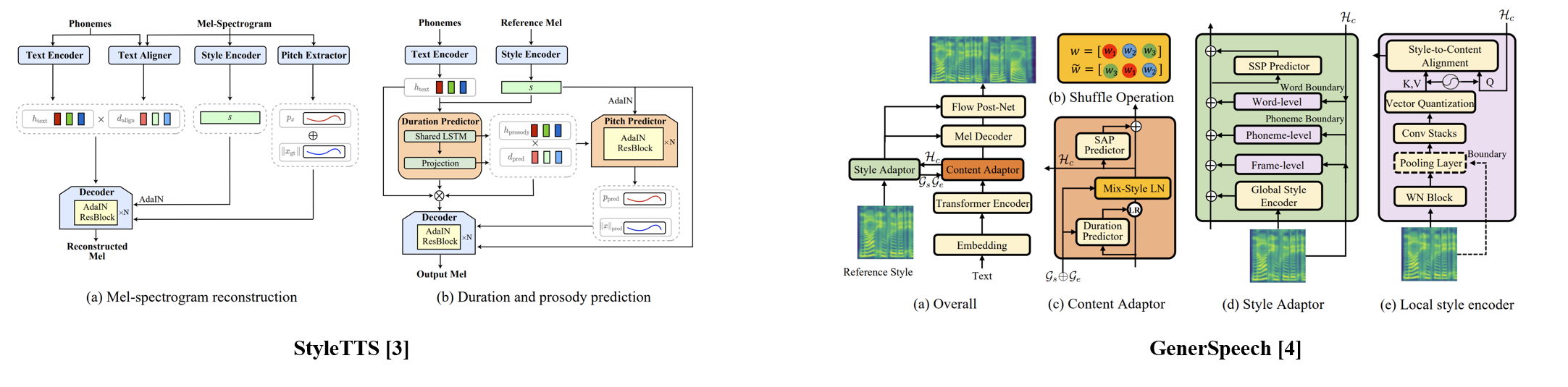
[4] Rongjie Huang, Yi Ren, Jinglin Liu, Chenye Cui, and Zhou Zhao. Generspeech: Towards style transfer for generalizable out-of-domain text-to-speech synthesis. arXiv preprint arXiv:2205.07211, 2022.
Proposed Method
DEX-TTS is a reference-based TTS with enhanced style representations. DEX-TTS consists of encoders and adapters to extract and represent reference styles categorized into time-invariant (T-IV) and time-variant (T-V) styles. By leveraging style modeling on time variability, DEX-TTS can represent enriched styles representations. In addition, DEX-TTS can enhance the performance by building the framework on the diffusion system.
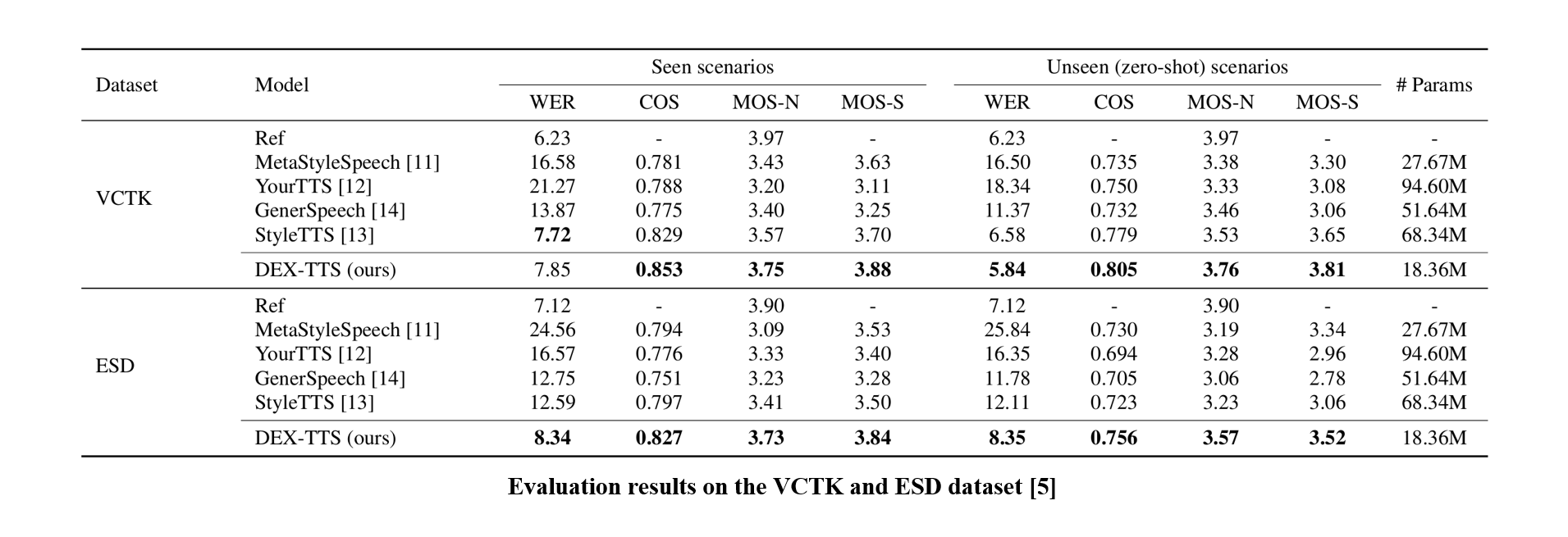
DEX-TTS outperforms previous methods in both objective and subjective evaluations on the VCTK and ESD datasets. It consistently achieves high similarity scores, demonstrating the effectiveness of its style modeling in extracting and reflecting rich styles from reference speech. Additionally, DEX-TTS shows strong generalization in zero-shot scenarios while maintaining high speech quality. Unlike previous approaches, it achieves excellent performance using only mel-spectrograms without relying on pre-trained models.
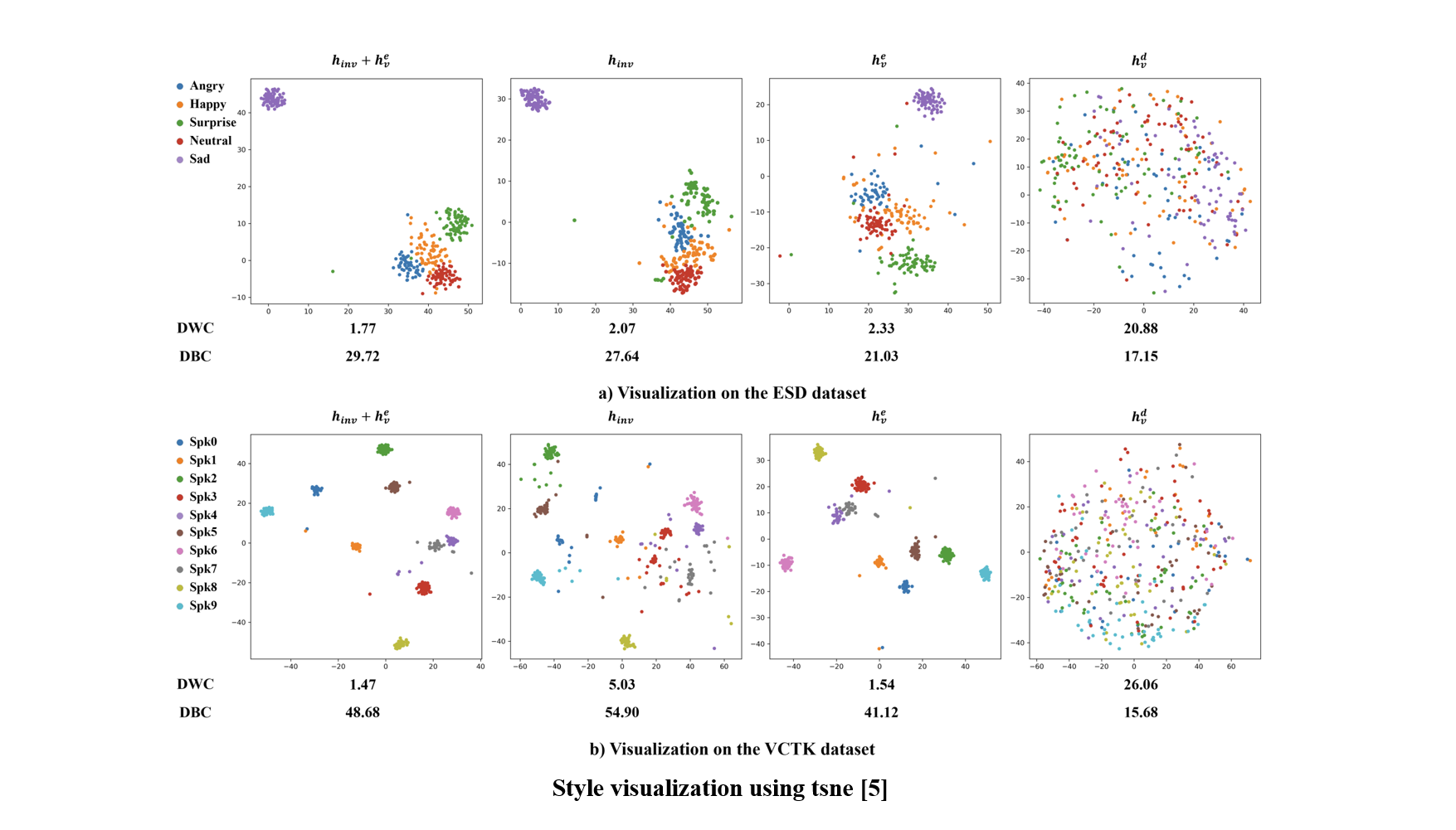
We visualize the extracted T-IV and T-V styles using T-SNE and analyze their clustering behavior. The results show that our style representations effectively capture speaker and emotional information without explicit labels.