Deep Learning – Object Detection
Beyond Virtual Points: Depth-Enhanced LiDAR-only 3D Object Detection with Semi-Supervised Learning
Objective
The task of 3D object detection is crucial for various applications that rely on identifying objects in three-dimensional space using inputs like LiDAR point clouds and images. However, LiDAR-based detection faces challenges due to the sparsity of point clouds, especially at greater distances. To address this, depth completion models have been used to generate virtual points from RGB images, but they struggle with real-time applications due to high computational costs. Our work eliminates the depth completion process, significantly improving processing speed while minimizing performance degradation.
Data
We used the KITTI dataset[1], which is the benchmark dataset for 3D object detection.
[1] https://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
Related Work
VirConv [2] utilized the virtual points for the 3D object detection.
PeP [3] used RGB image and language model encoder for the 3D object detection.
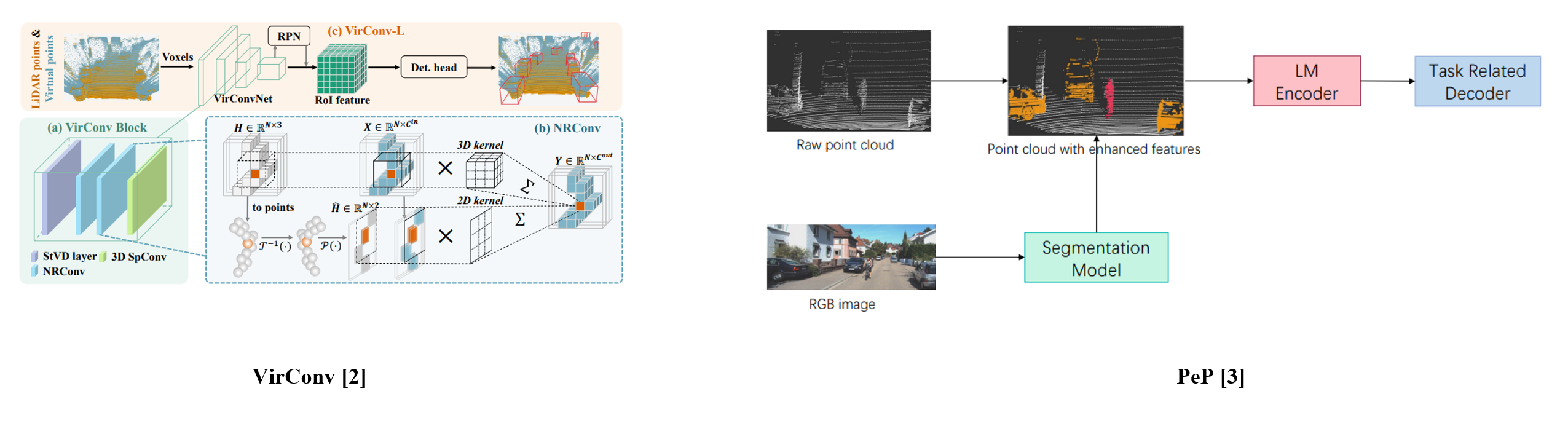
[3] Dong, Zichao, et al. “PeP: a Point enhanced Painting method for unified point cloud tasks.” arXiv preprint arXiv:2310.07591 (2023).
Proposed Method
The conventional approach has two main components: The depth completion process and the object detection process. To achieve high FPS, we removed the depth completion process and adopted a LiDAR only framework. The LiDAR only framework eliminates the need to process RGB images and virtual points. However, removing the depth completion process led to a decline in detection performance. To overcome the decline in detection performance, we utilized semi-supervised learning and proposed a novel noise augmentation technique called Depth Enhancement.
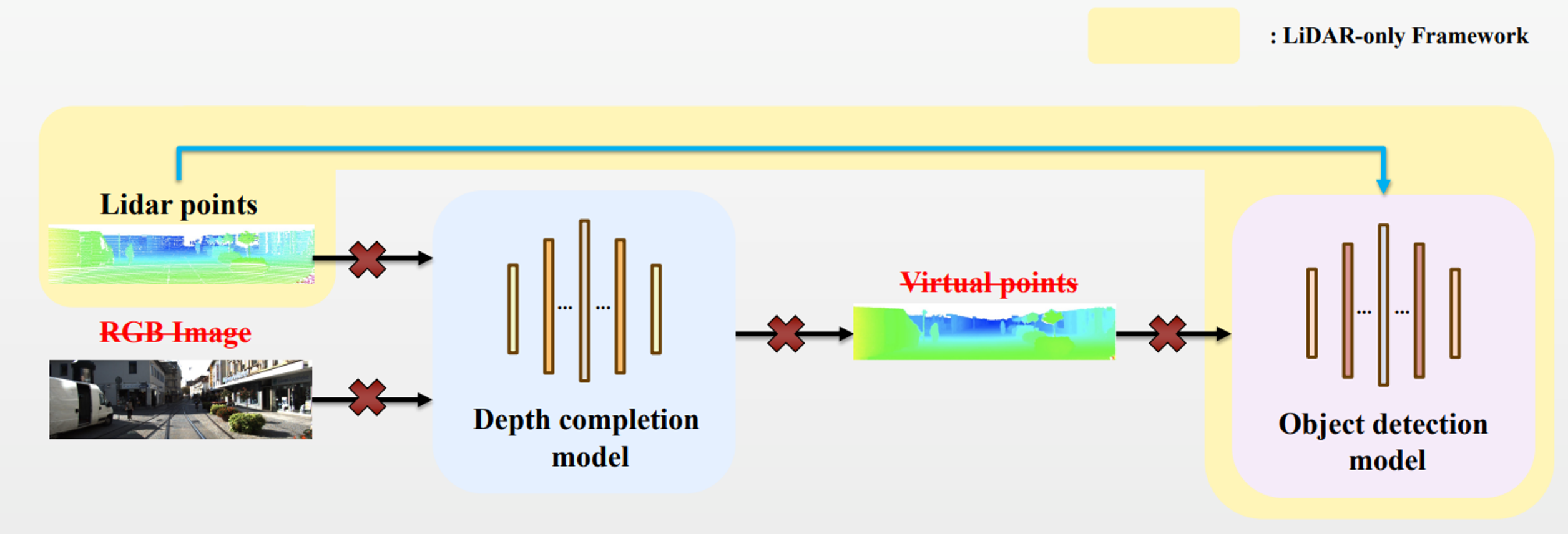
The depth enhancement technique is applied only during the training process, so it does not delay the system.
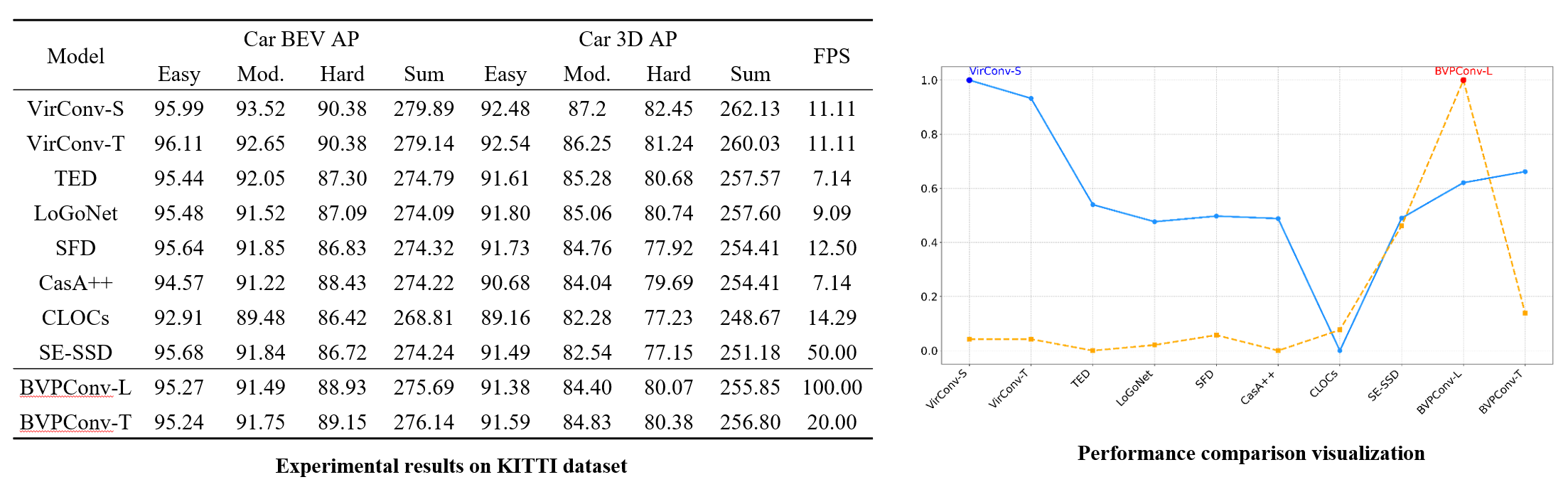
The experimental results indicate that models trained using our proposed methodology, specifically BVPConv-L and BVPConv-T, delivered optimal performance.
In particular, BVPConv-L outperformed most existing models in terms of accuracy while sustaining an impressive FPS of 100, highlighting its remarkable real-time efficiency.
CMLF: Contextual Masked Learning Framework for RGB-D Salient Object Detection
Objective
RGB-D Salient Object Detection (SOD) focuses on identifying important objects within an image by utilizing RGB images and depth maps. Since salient objects hold key information about the image, SOD has the potential for expansion across various computer vision fields.
Although numerous studies have been conducted, they mainly focus on building complex architecture for high performance. Since contextual information within an image is essential for determining the importance of objects, there remains room for further exploration in directly learning such contextual information. In this paper, we propose a masking-based supervised learning framework called the Contextual Masked Learning Framework (CMLF) to address the aforementioned issue.
Data
We use the subset of NLPR [1] and NJU2K [2] datasets, which contains salient objects in various situations, to train the models.
7 types of benchmark datasets, which are NLPR, NJU2K, DES [3], LFSD [4], SIP [5], SSD[6], and STERE [7] are used to test the performance.
[1] H. Peng, B. Li, W. Xiong, W. Hu, and R. Ji, “RGBD salient object de-tection: A benchmark and algorithms,” in Computer Vision–ECCV 2014:13th European Conference, Zurich, Switzerland, September 6-12, 2014,Proceedings, Part III 13, 2014: Springer, pp. 92-109.
[2] R. Ju, L. Ge, W. Geng, T. Ren, and G. Wu, “Depth saliency based onanisotropic center-surround difference,” in 2014 IEEE international con-ference on image processing (ICIP), 2014: IEEE, pp. 1115-1119.
[3] Y. Cheng, H. Fu, X. Wei, J. Xiao, and X. Cao, “Depth enhanced saliencydetection method,” in Proceedings of international conference on internetmultimedia computing and service, 2014, pp. 23-27.
[4] N. Li, J. Ye, Y. Ji, H. Ling, and J. Yu, “Saliency detection on light field,”in Proceedings of the IEEE conference on computer vision and patternrecognition, 2014, pp. 2806-2813.
[5] D.-P. Fan, Z. Lin, Z. Zhang, M. Zhu, and M.-M. Cheng, “Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks,”IEEE Transactions on neural networks and learning systems, vol. 32, no.5, pp. 2075-2089, 2020.
[6] C. Zhu and G. Li, “A three-pathway psychobiological framework of salientobject detection using stereoscopic technology,” in Proceedings of theIEEE international conference on computer vision workshops, 2017, pp.3008-3014.
[7] Y. iu, Y. Geng, X. Li, and F. Liu, “Leveraging stereopsis for saliencyanalysis,” in 2012 IEEE Conference on Computer Vision and PatternRecognition, 2012: IEEE, pp. 454-461.
Related Work
Encoder-Decoder models such as BTS-Net [8] are widely used in RGB-D SOD task.
Masked learning has emerged as a powerful technique in computer vision tasks, enabling models to develop robust and comprehensive representation.
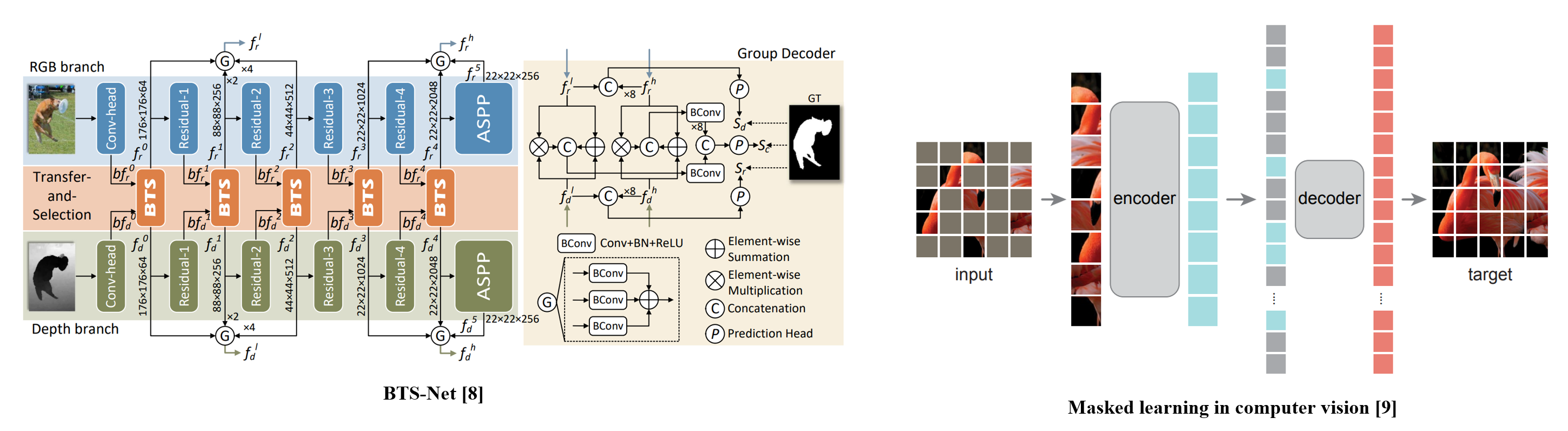
[9] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked au-toencoders are scalable vision learners,” in Proceedings of the IEEE/CVFconference on computer vision and pattern recognition, 2022, pp. 16000-16009.
Proposed Method
CMLF employs dual branches in Siamese Style network, which are Base Branch and Context Branch, to utilize both unmasked inputs and masked inputs. These two branches are identical and share the same weights. The only difference between them is the application of random patch masking to the respective inputs.
Our learning strategy aims to compensate for local and global contextual information by utilizing additional contextual supervision with masked inputs for accurate salient object prediction.
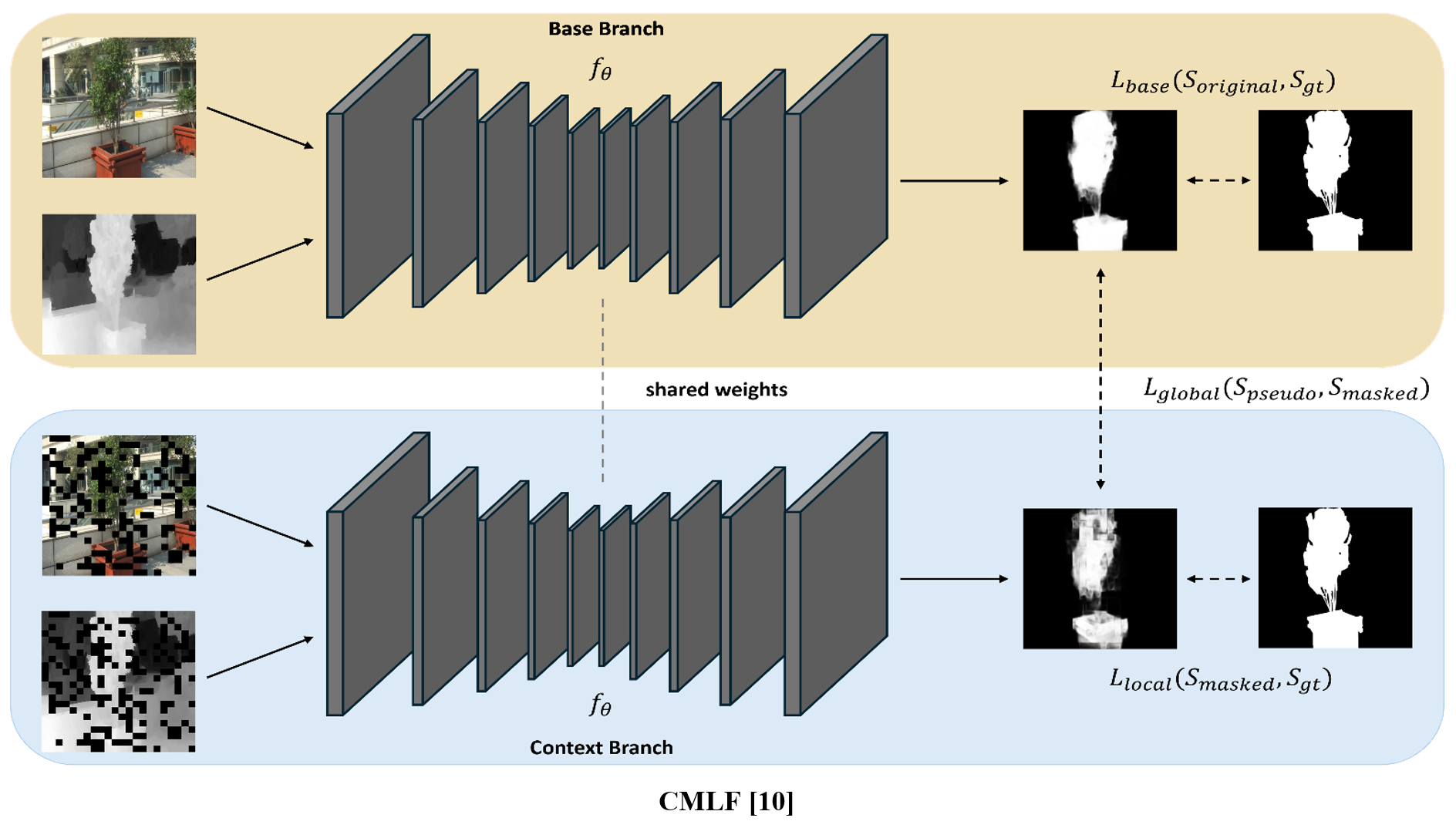
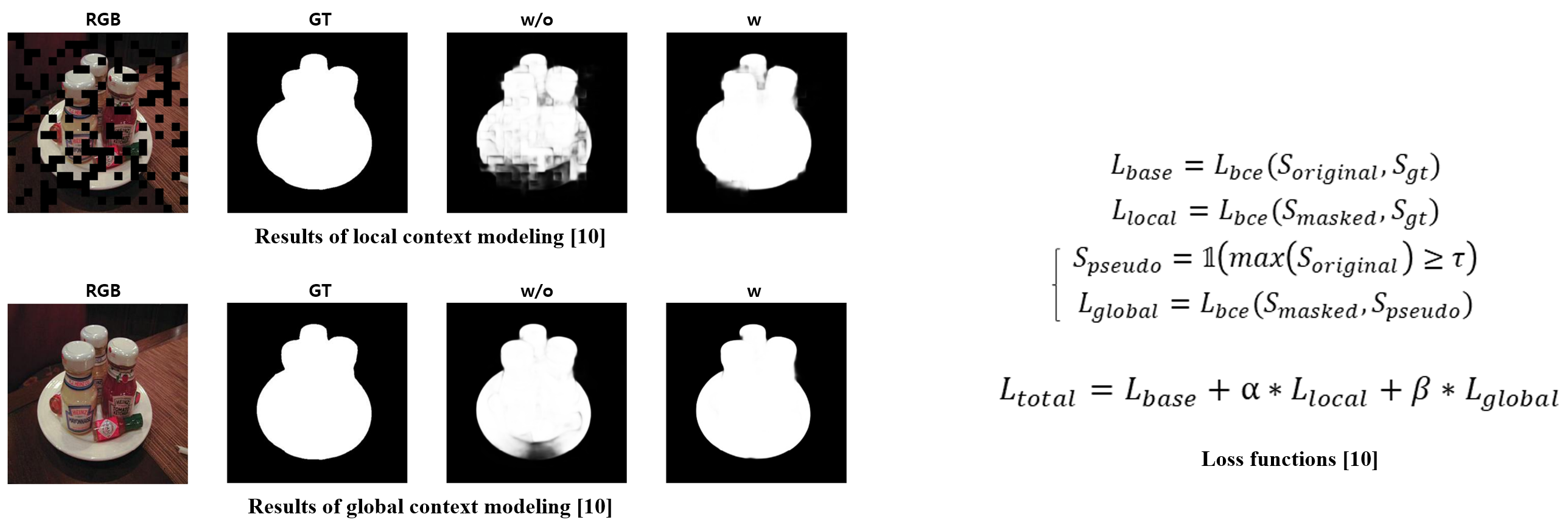
1) Local context loss
To capture the local context for a finer assessment of the significance of objects, we utilize the outputs from the Context Branch and the corresponding ground truth.
2) Global context loss
To enable the comprehension of global contextual information, we leverage global context loss using the outputs obtained from the two aforementioned branches.
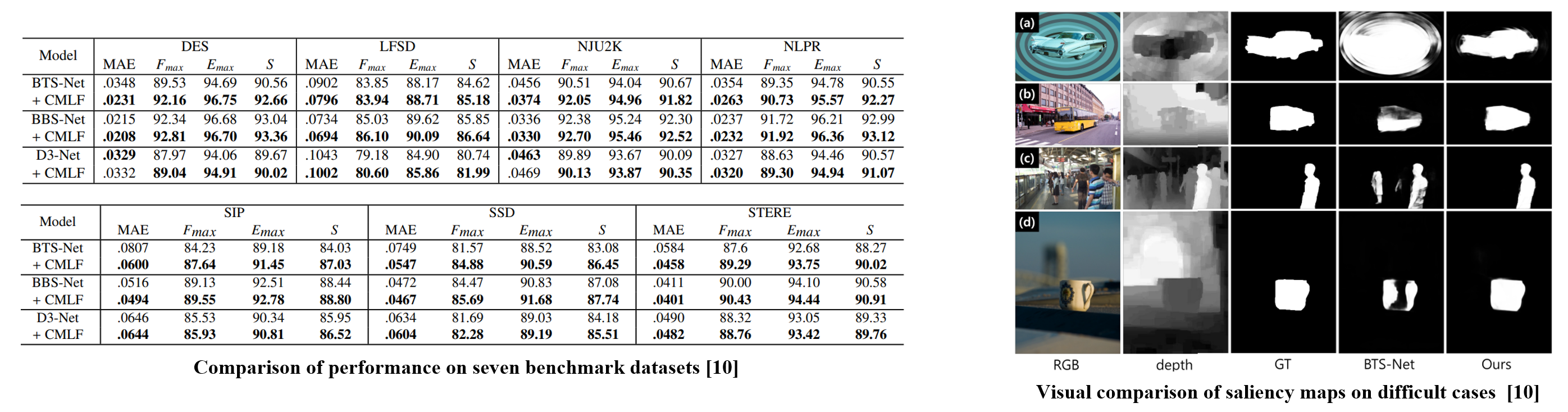
Experiments are conducted using 3 types of RGB-D SOD models, which are BTS-Net, BBS-Net, and D3-Net.
CMLF enables three types of backbone models to outperform their counterparts trained with the original procedure, without any architectural modifications. The overall performance is observed to improve across all four evaluation metrics on all seven benchmark datasets.
Additionally, the use of CMLF qualitatively demonstrates that it enables more accurate detection in representative cases where existing RGB-D SOD models struggle with precise identification.
Study on the real-time object detection approach for end-of-lifebattery-powered electronics in the waste of electrical and electronic equipment recycling process
Objective
With the growing use of electrical and electronic equipment (EEE), managing end-of-life EEE has become critical. Thus, the demand for sorting and detaching batteries from EEE in real time has increased. In this study, we investigated real-time object detection for sorting EEE, which uses batteries, among numerous EEEs.
Data
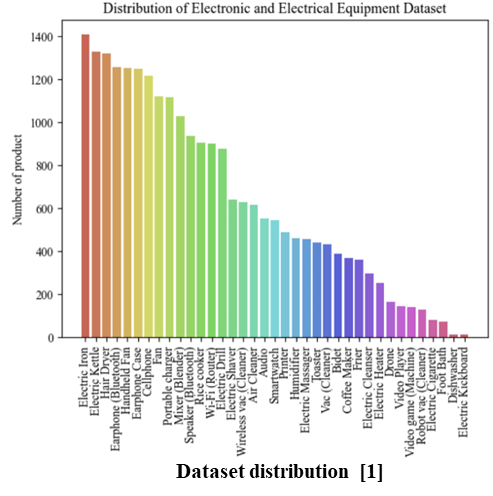
Assuming actual WEEE recycling processes, to design deep learning to detect the battery-powered EEE products among various WEEE products, Images were collected from a total of 37 EEE products; where, a number of 12 EEE products, battery-powered type, and the remaining the number of 25 EEE products were non-battery type.
As a result of image collection for a total of 37 products, 21,218 and 5,184 images were collected through crowd source and open-source methods, respectively; a total 26,402 images were used for deep learning analysis.
Related Work
Fast RCNN [2] is a two-stage object detection method.
YOLO [3] proposed a one-stage object detection model.

[3] Redmon, Joseph, et al. “You only look once: Unified, real-time object detection.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
Proposed Method
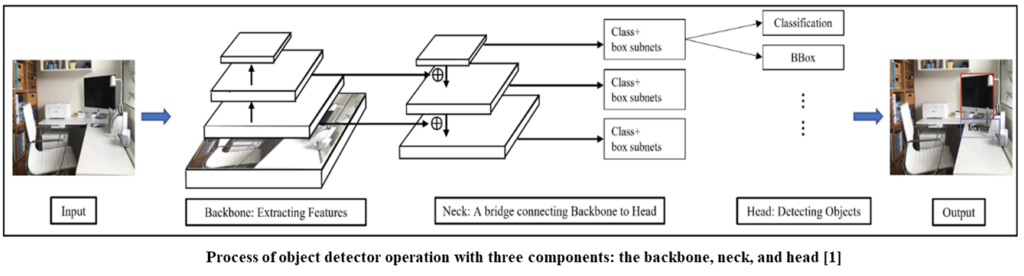
Real-time OD has three components: the backbone, neck, and head. The backbone transforms an input image into a feature map to extract prominent information. The neck refines and reconfigures representation by combining feature maps obtained from different backbone levels. With this information, the head performs predictions, including classification and localization of an object.
Based on the above process, we seek the optimal object detection method for detecting battery-powered EEE products. To achieve it, we investigate the object detection types, backbone types, and learning strategies.
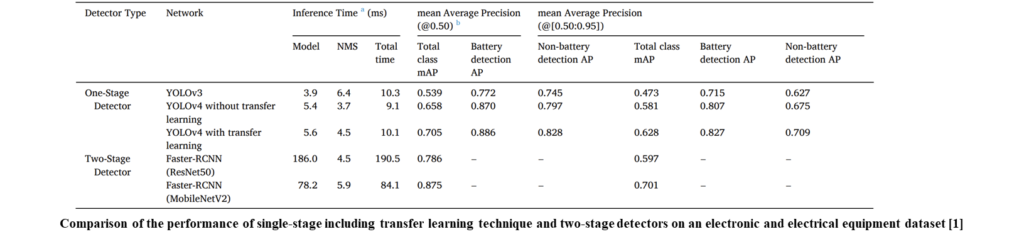
We compared single-stage detectors with two-stage detectors to search for the optimal network for detecting battery-powered EEE products. The Faster-RCNN performed better when the mAP was 0.50–0.95 of the total classes, but YOLO was 20 times faster than the two-stage algorithm in the measurement of the inference time while achieving a mAP score of 0.50–0.95, near that with Faster RCNN. Undoubtedly, this experiment helped in selecting a single-stage model to fit the domain problem of real-time electronic equipment detection. Additionally, transfer learning is effective for performance improvement.
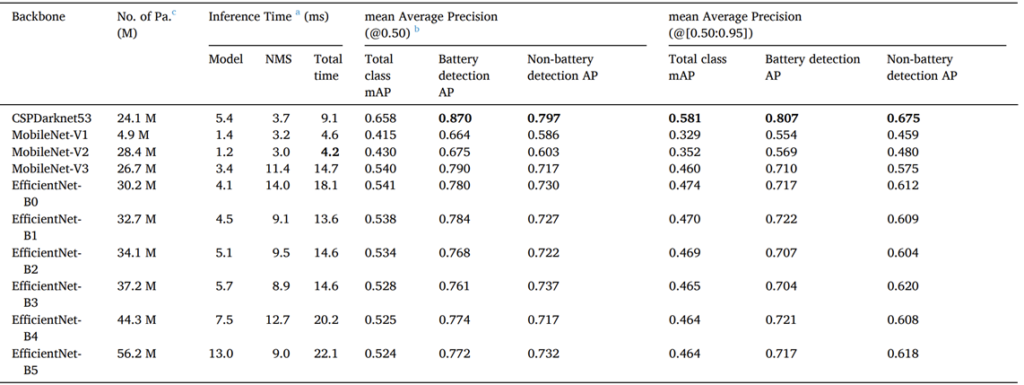
To search for the optimal backbone, we conducted comprehensive experiments with 10 backbones. Among the 10 backbones, CSPDarknet53 performed best. Although EfficientNet and MobileNet focused on the efficiency and lightness of the network, CSPDarknet53 achieved a speed of 9.1 ms and a faster inference time, with a difference of 5.6 ms to 13 ms from the other backbones when it came to containing more or fewer parameters than the other backbones.
TRACER: Extreme Attention guided Salient Object Tracing Network
Objective
Salient object detection (SOD) aims to detect the objects that exhibit the most visual distinctiveness in an image. Existing approaches improved SOD performance; however, they are incapable of simultaneously achieving performance and computational efficiency. This study proposes an extreme attention-guided salient object tracing network called TRACER to address the inefficiencies in existing approaches.
Data
We performed the evaluation on five benchmark datasets: DUTS, DUT-OMRON, ECSSD, HKU-IS, and PASCAL-S.
Related Work
EGNet explicitly models complementary salient object information and salient edge information within the network to preserve the salient object boundaries.
PPA loss proposed in F3Net doesn’t treat pixels equally, which can synthesize the local structure information of a pixel to guide the network to focus more on local details.
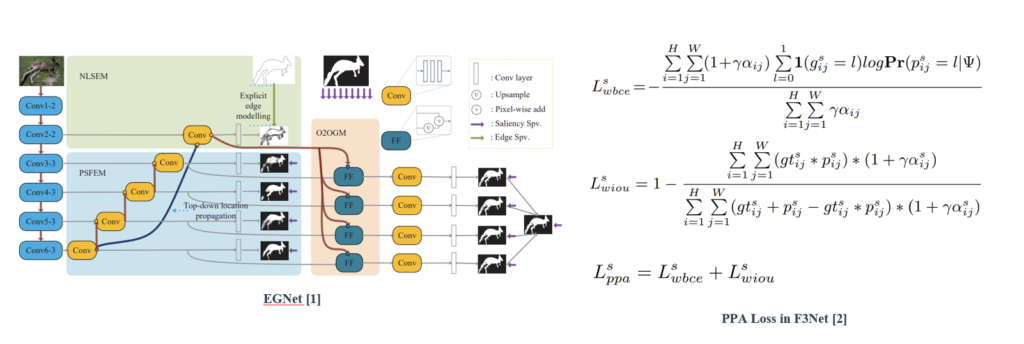
Proposed Method
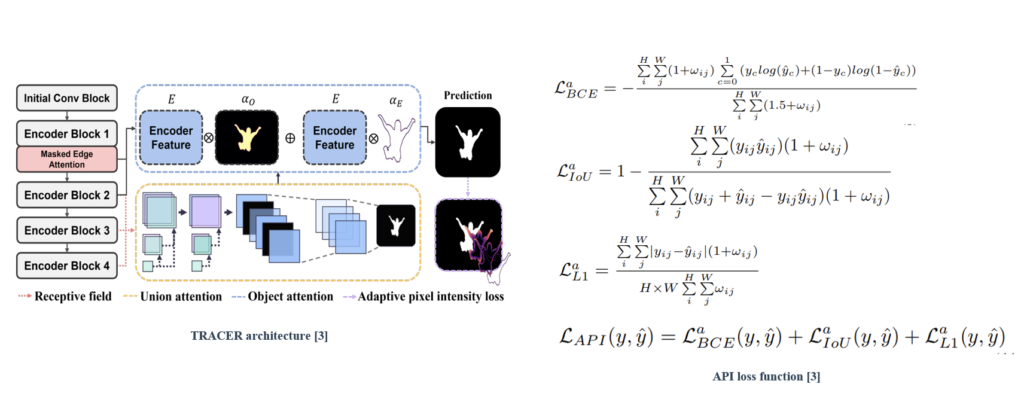
TRACER, which comprises an efficient backbone encoder (EfficientNet) along with attention-guided salient object tracing modules (masked edge, union, and object attention modules). Further, we propose an adaptive pixel intensity (API) loss function to deal with the relatively important pixels unlike conventional loss functions which treat all pixels equally.
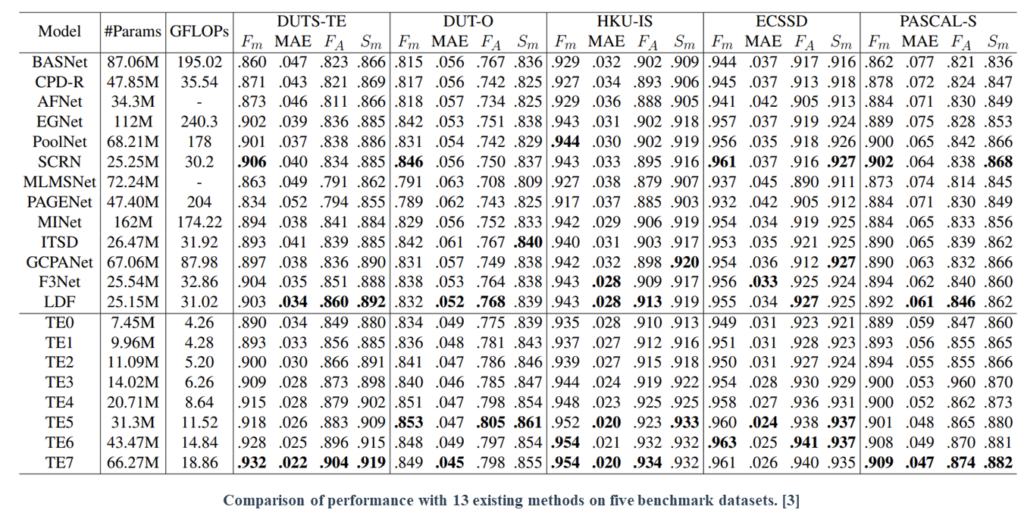
TRACER achieved a state-of-the-art performance and computational efficiency in all the evaluation metrics when compared with the previous 13 methods on the five benchmark datasets. In particular, TE2 showed relatively similar performance compared to LDF, which was the previous outstanding method; however, TE2 required 2.3× fewer learning parameters and was 6× faster than LDF.
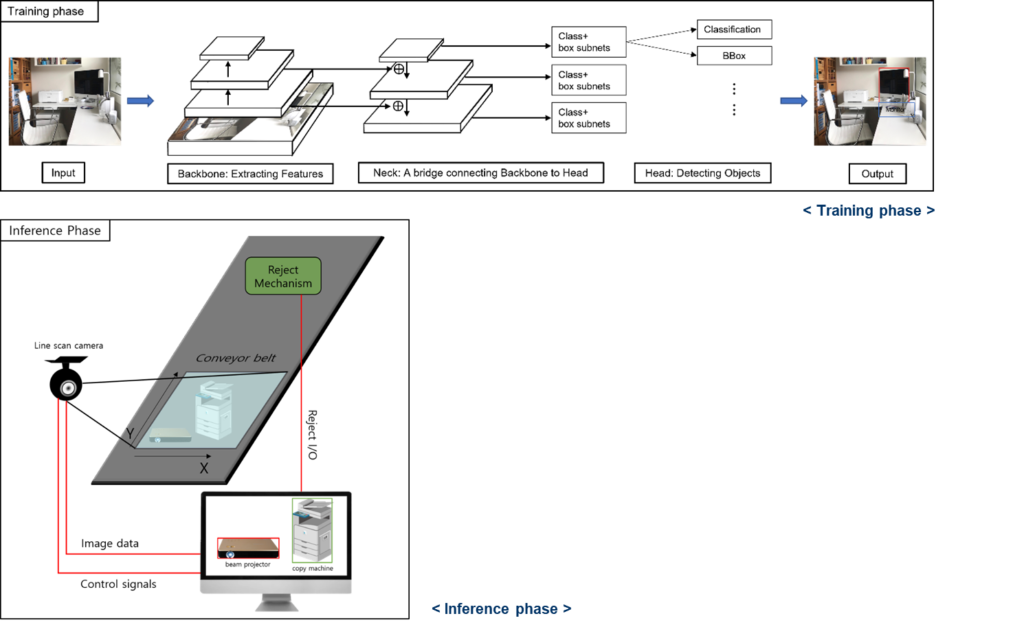
Real-time Object Detection for Lithium Battery
Objective
Lithium battery includes harmful metals (lead, mercury, etc.). Thus, collecting eco-friendly resources and managing hazardous materials are required during the discharge process. We propose a deep learning-based pipeline to select products containing the lithium battery among waste electrical and electronic products on a conveyor belt.
Data

Related Work
Related work: This study aims at the problem that mining conveyor belts are easily damaged under severe working conditions, based on the reclassification and definition of conveyor belt damage types. Conveyor belt damage is detected by the improved Yolov3 algorithm, which considers the impact of model scaling on the detection results [Zhang et al., 2021].

Proposed Method
We trained Electronic and Electronical data based on YOLOv4 with CSPDarknet53 as the backbone and made the pipeline for detecting products containing the lithium battery on a conveyor belt. When waste electrical and electronic products move on a conveyor belt, a line scan camera detects the product, if the product is a lithium battery product. Then, the network signal the reject device to select the product.