Deep Learning – Speech
MANNER: Multi-view Attention Network for Noise ERasure
Objective
Speech enhancement (SE) is the task of removing background noises to obtain a high quality of clean speech. Previous studies on speech enhancement tasks have difficulties in achieving both high performance and efficiency, which is caused by the lack of efficiency in extracting the speech’s long sequential features. We propose a U-net-based MANNER composed of a multi-view attention (MA) block which efficiently extracts speech’s channel and long sequential features from each view.
Data
We use the VoiceBank-DEMAND dataset [1] which is made by mixing the VoiceBank Corpus and DEMAND noise dataset.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
Related Work
Denoiser adopted the U-net architecture and exploited LSTM layers in the bottleneck.
TSTNN suggested a dual-path method to extract long signal information.
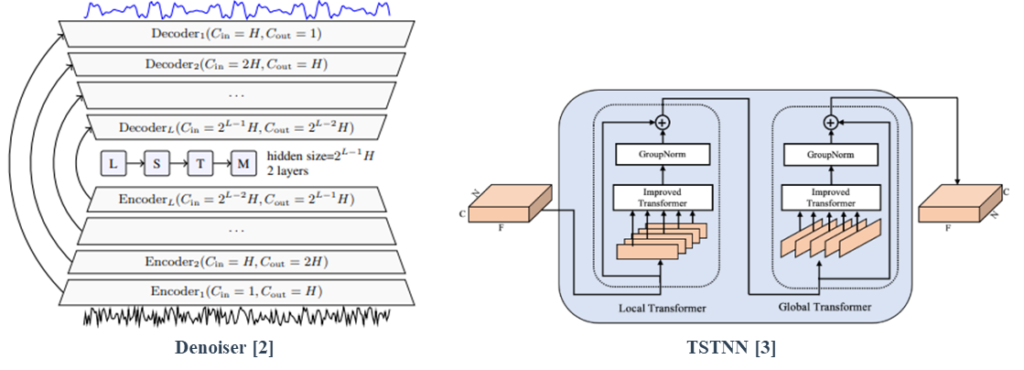
[3] K.Wang, B.He, and W.-P.Zhu, “Tstnn: Two-stage transformer based neural network for speech enhancement in the time domain,” in ICASSP. IEEE, 2021, pp. 7098– 7102
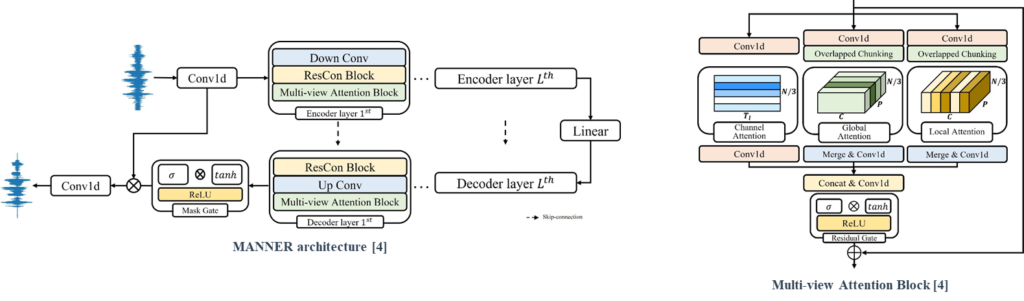
Proposed Method
MANNER is based on U-net and each encoder and decoder consists of Lth encoder and decoder layers, respectively. Each layer is composed Down or Up convolution layer, a Residual Conformer block, and a Multi-view Attention block. Furthermore, we adopt a residual connection between encoder and decoder layers.
To represent all the speech information, the Multi-view Attention block processes the data into three attention paths, channel, global, and local attention. Channel attention emphasizes channel representations and Global and Local attention based on dual-path processing efficiently extracts long sequential features.
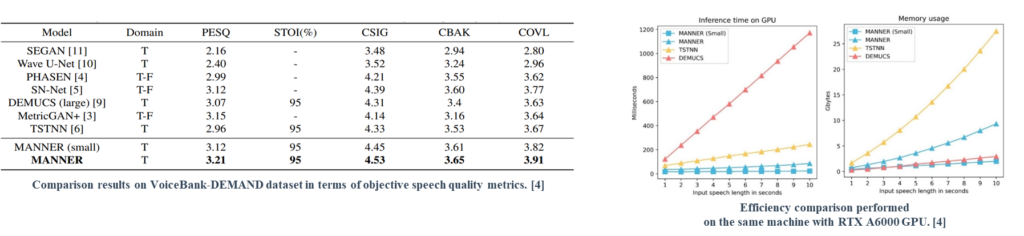
MANNER achieved state-of-the-art performance with a significant improvement compared to the previous methods in terms of five objective speech quality metrics. Although MANNER (small)’s performance decreases, it outperformed the previous methods in terms of performance and efficiency.
Unlike many existing models, which tend to suffer from some combination of poor performance, slow speed, or high memory usage, MANNER provides competitive results in all of these regards, allowing for more efficient speech enhancement without compromising quality.
A Robust Framework for Sound Event Localization and Detection on Real Recordings
Objective
We address the sound event localization and detection (SELD) problem, of one held at the IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) in 2022. The task aims identification of both the sound-event occurrence (SED) and the direction of arrival from the sound source (DOA). However, by allowing large external datasets and giving small real recordings, the challenge also encompasses a key issue of exploiting synthetic acoustic scenes to perform SELD well in the real world.
Data
STARSS22 [1] is in public for the 2022 challenge, comprising real-world recording and label pairs that were man-annotated. To synthesize emulated sound scenarios from the external data, we use class-wise audio samples extracted from seven external datasets, which are AudioSet [2], FSD50K [3], DCASE2020 and 2021 SELD datasets [4, 5], ESC-50 [6], IRMAS [7], and Wearable SELD [8]. As the same way in former SELD task challenges, extracted audio samples are synthesized through SRIR and SNoise from TAU-SRIR DB [9] emulating the spatial sound environment.
[1] A. Politis, K. Shimada, P. Sudarsanam, S. Adavanne, D. Krause, Y. Koyama, N. Takahashi, S. Takahashi, Y. Mitsufuji, and T. Virtanen, “Starss22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events,” 2022. [Online]. Available: https://arxiv.org/abs/2206.01948
[2] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in Proc. IEEE ICASSP 2017, New Orleans, LA, 2017.
[3] E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra, “FSD50K: an open dataset of human-labeled sound events,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 829–852, 2022.
[4] A. Politis, S. Adavanne, and T. Virtanen, “A dataset of reverberant spatial sound scenes with moving sources for sound event localization and detection,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), Tokyo, Japan, November 2020, pp. 165–169. [Online]. Available: https: //dcase.community/workshop2020/proceedings
[5] A. Politis, S. Adavanne, D. Krause, A. Deleforge, P. Srivastava, and T. Virtanen, “A dataset of dynamic reverberant sound scenes with directional interferers for sound event localization and detection,” in Proceedings of the 6th Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), Barcelona, Spain, November 2021, pp. 125–129. [Online]. Available: https://dcase.community/workshop2021/proceedings
[6] K. J. Piczak, “ESC: Dataset for Environmental Sound Classification,” in Proceedings of the 23rd Annual ACM Conference on Multimedia. ACM Press, pp. 1015– 1018. [Online]. Available: http://dl.acm.org/citation.cfm? doid=2733373.2806390
[7] J. J. Bosch, F. Fuhrmann, and P. Herrera, “IRMAS: a dataset for instrument recognition in musical audio signals,” Sept. 2014. [Online]. Available: https://doi.org/10.5281/zenodo. 1290750
[8] K. Nagatomo, M. Yasuda, K. Yatabe, S. Saito, and Y. Oikawa, “Wearable seld dataset: Dataset for sound event localization and detection using wearable devices around head,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 156–160.
[9] A. Politis, S. Adavanne, and T. Virtanen, “TAU Spatial Room Impulse Response Database (TAU- SRIR DB),” Apr. 2022. [Online]. Available: https://doi.org/10.5281/zenodo.6408611
Related Work
SELDnet [10] established the basic neural network structure to perform SELD, which comprises the layers processing multichannel spectrogram input (2D CNN) followed by sequential processing layers (Bi-GRU) and lastly, fully-connected linear layers.
The squeeze-and-excitation residual networks [11] (SE-ResNet) have recently been applied to audio classification [12, 13], as the SELD encoder.
[14] proposed the method of rotating the sound direction of arrival as the data-augmentation for SELD.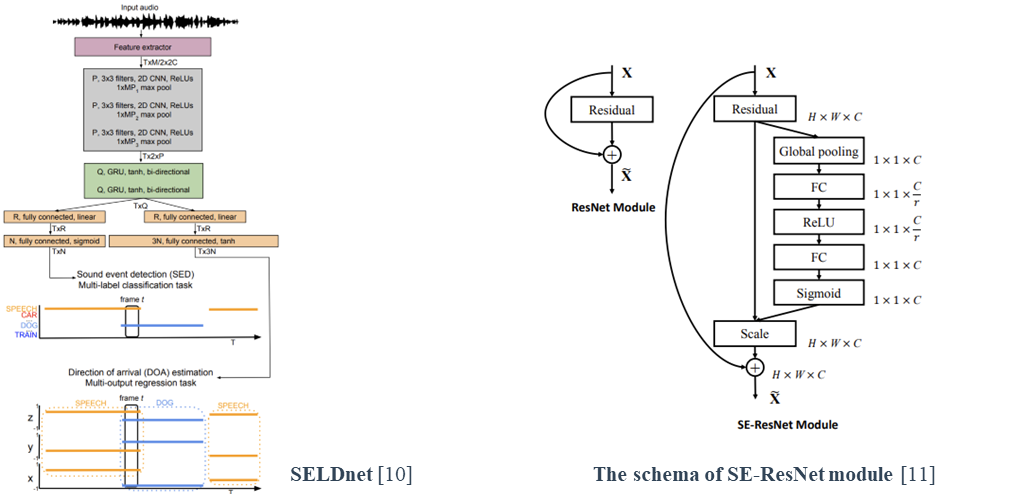
[10] S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,” IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 1, pp. 34–48, 2018.
[11] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141.
[12] J. H. Yang, N. K. Kim, and H. K. Kim, “Se-resnet with ganbased data augmentation applied to acoustic scene classification,” in DCASE 2018 workshop, 2018.
[13] H. Shim, J. Kim, J. Jung, and H.-j. Yu, “Audio tagging and deep architectures for acoustic scene classification: Uos submission for the dcase 2020 challenge,” Proceedings of the DCASE2020 Challenge, Virtually, pp. 2–4, 2020.
[14] L. Mazzon, Y. Koizumi, M. Yasuda, and N. Harada, “First order ambisonics domain spatial augmentation for dnn-based direction of arrival estimation,” arXiv preprint arXiv:1910.04388, 2019.
Proposed Method
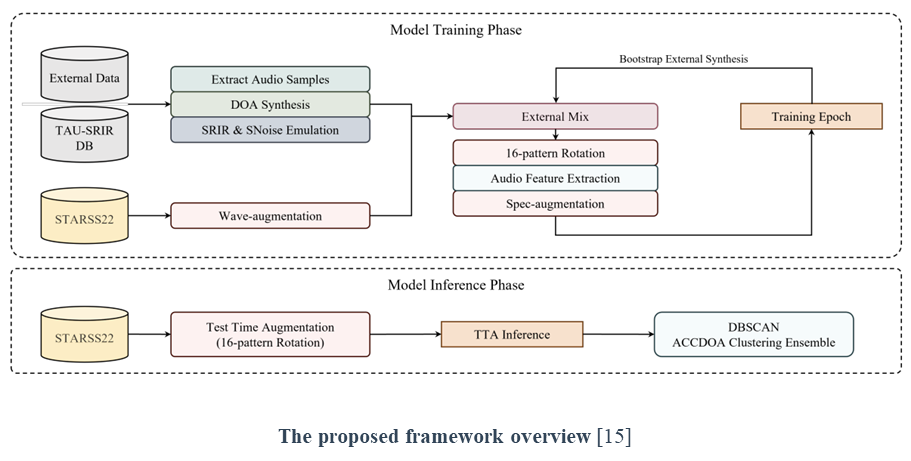
To keep the model fit in real-world scenario contexts while taking advantage of various audio samples from external datasets, a dataset mixing technique (External Mix) is adopted to consist model training dataset. The technique balances the size of each dataset on the model training phase, between the small real recording set and the large emulated scenarios.
A test time augmentation (TTA) is widely used in computer vision to increase the robustness and performance of models. On the other hand, the unknown number of events and the presence of coordinates information make it challenging to apply TTA on SELD. To utilize TTA on SELD, we propose a clustering-based aggregation method to obtain confident-predicted outputs and aggregate them. We take 16 pattern rotation augmentation for test time augmentation, making 16 predicted outputs, that is candidates. To obtain confident aggregated outputs, we use DBSCAN [16] for clustering candidates.
[15] J. S. Kim*, H. J. Park*, W. Shin*, and S. W. Han**, “A robust framework for sound event localization and detection on real recordings,” Tech. Rep., 3rd prize for Sound Event Localization and Detection, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE), 2022.
[16] M. Ester, H.-P. Kriegel, J. Sander, X. Xu, et al., “A densitybased algorithm for discovering clusters in large spatial databases with noise.” in kdd, vol. 96, no. 34, 1996, pp. 226– 231.
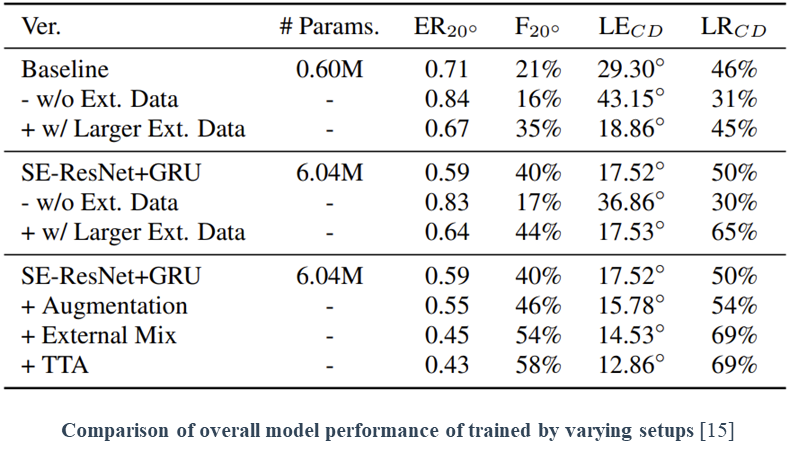
We validate the influence of the proposed framework in experiments. The second row (w/o Ext. Data) of both the first and second blocks is the result of only using small real-world recording data as the training set. As reported in the first rows at the first and second blocks, We observed that using emulated data (Baseline synthesized data [17]), simulated from FSD50K audio samples, enhances the performance of the same models. Concurrently, however, the third row (w/ Larger Ext. Data) of each shows that the addition of larger emulated soundscapes does not guarantee performance improvement.
In the last block, we found that significant improvements were obtained from three components (Augmentation, External Mix, and TTA). Among them, the external mix method contributed more to the performance improvement than the other methods.
[15] J. S. Kim*, H. J. Park*, W. Shin*, and S. W. Han**, “A robust framework for sound event localization and detection on real recordings,” Tech. Rep., 3rd prize for Sound Event Localization and Detection, IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events (DCASE), 2022.
[17] [DCASE2022 Task 3] Synthetic SELD mixtures for baseline training, [Online]. Available: 10.5281/zenodo.6406873
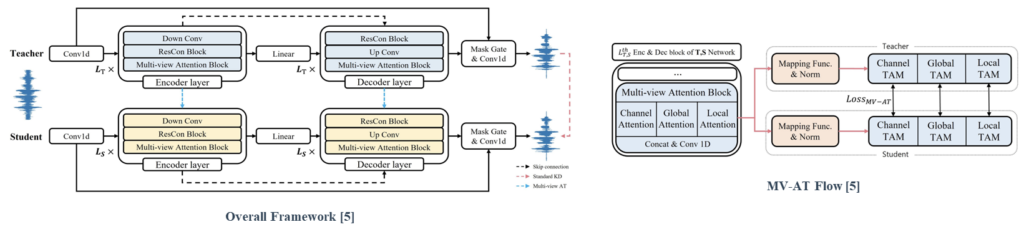
Multi-View Attention Transfer for Efficient Speech Enhancement
Objective
Speech enhancement (SE) involves the removal of background noise to improve the perceptual quality of noisy speech. Although deel learning-based methods have achieved significant improvements in SE, the problem remains that they do not simultaneously satisfy the low computational complexity and model complexity required in various deployment environments while minimizing performance degradation. We propose multi-view attention transfer (MV-AT) to obtain efficient speech enhancement models.
Data
We use the VoiceBank-DEMAND [1] and Deep Noise Suppression (DNS) [2] datasets.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
[2] C. K. Reddy et al., “The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results”, 2020.
Related Work
MANNER is composed of a multi-view attention (MA) block which efficiently extracts speech’s channel and long sequential features from each view.
Attention transfer (AT), a feature-based distillation, transfers knowledge using attention maps of features.
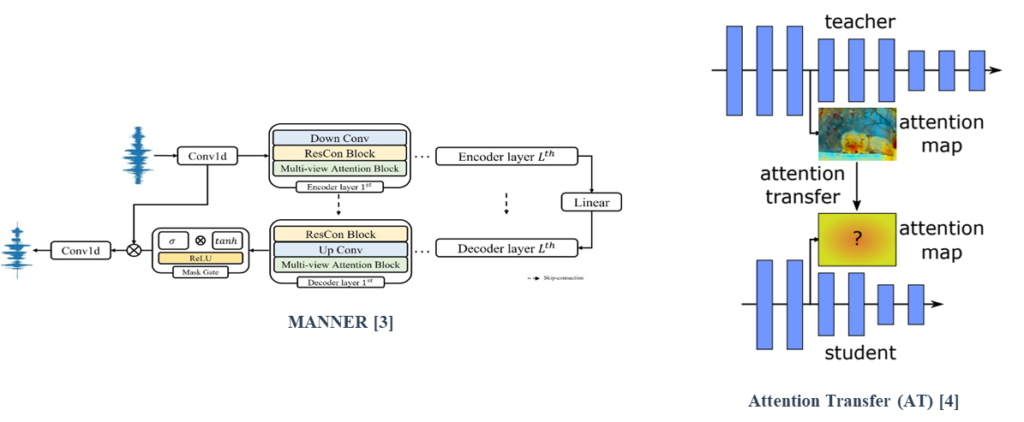
[4] Zagoruyko, S. and Komodakis, N. “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer”, 2016.
Proposed Method
MV-AT based on the MANNER backbone transfers the feature-wise knowledge of the teacher by utilizing each feature highlighted in the multiview.
By applying MV-AT, the student network can easily learn the teacher’s signal representation and mimic the matched representation from each perspective. MV-AT can not only compensate for the limitation of standard KD in SE as feature-based distillation but also make an efficient SE model without additional parameters.
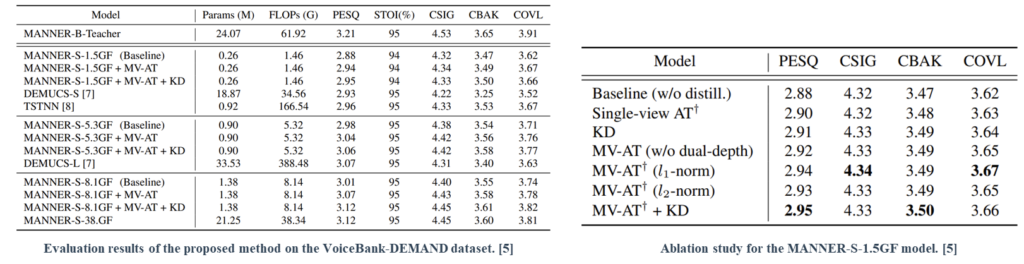
The results of experiments conducted on the Valentini and DNS datasets indicate that the proposed method achieves significant efficiency. While exhibiting comparable performance to the baseline model, the model generated by the proposed method required 15.4× and 4.71× fewer parameters and flops, respectively.
To investigate the effects of different components on the performance of the proposed method, we performed an ablation study over MV-AT and standard KD.
TriAAN-VC: Triple Adaptive Attention Normalization for Any-to-Any Voice Conversion
Objective
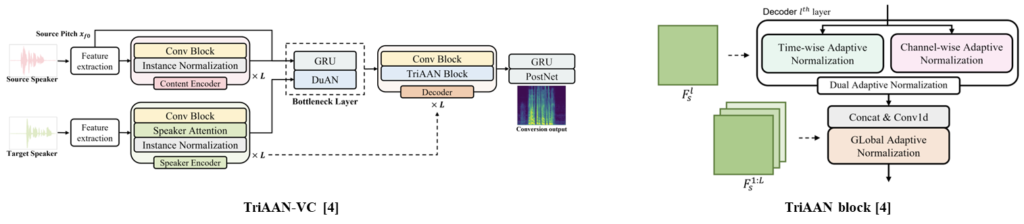
VC is the task of transforming the voice of the source speaker into that of the target speaker while maintaining the linguistic content of the source speech. The existing methods do not simultaneously satisfy the above two aspects of VC, and their conversion outputs suffer from a trade-off problem between maintaining source contents and target characteristics. In this study, we propose Triple Adaptive Attention Normalization VC (TriAAN-VC), comprising an encoder-decoder and an attention-based adaptive normalization block, that can resolve the trade-off problem of VC.
Data
We use the VCTK dataset [1] which is an English multi-speaker corpus
[1] C.Veaux, J.Yamagishi, K.MacDonald, et al., “Superseded-cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit,” 2016.
Related Work
AdaIN-VC [2] adopted adaptive instance normalization for the conversion process.
S2VC [3] used cross-attention for the conversion process.
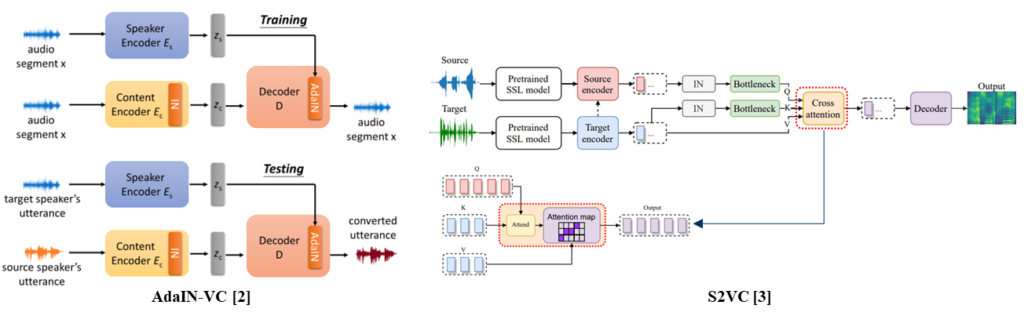
[3] Lin, Jheng-hao, et al. “S2vc: A framework for any-to-any voice conversion with self-supervised pretrained representations.” arXiv preprint arXiv:2104.02901 (2021).
Proposed Method
Triple Adaptive Attention Normalization VC (TriAAN-VC) is for non-parallel A2A VC. TriAAN-VC, which is based on an encoder-decoder structure, disentangles content and speaker features. TriAAN block extracts each detailed and global speaker representation from disentangled features and uses adaptive normalization for conversion. As a training approach, siamese loss with time masking is applied to maximize the maintenance of the source content.
TriAAN-VC achieved better performance on WER, CER, and SV scores, regardless of conversion scenarios compared to the existing methods which suffered from a trade-off problem of VC. It suggests that the conversion methods using compact speaker features can simultaneously retain both source content and target speaker characteristics.
For MOS results, it is similar to the results of objective evaluation. TriAAN-VC demonstrated a slight improvement over S2VC in terms of similarity, which is close to the performance of the oracle. Furthermore, TriAAN-VC outperformed the previous methods in terms of naturalness evaluation, suggesting the proposed model can make relatively unbiased results.

AD-YOLO: You Look Only Once in Training Multiple Sound Event Localization and Detection
Objective
Given a multi-channel audio input, sound event localization and detection (SELD) combines sound event detection (SED) along the temporal progression and the identification of the direction-of-arrival (DOA) of the corresponding sounds. Several prior works proposed methods to train deep neural networks by representing targets in event/track-oriented approaches. However, the event-oriented track output formats intrinsically contain the limitation of presetting the number of tracks, constraining the generality and expandability of the method itself.
Data
A series of development sets of DCASE Task 3 from 2020 to 2022 [1, 2, 3] are used. In addition, the simulated acoustic scenes to train 2022 baseline [4] is also exploited.
[1] A. Politis, S. Adavanne, and T. Virtanen, “A dataset of reverberant spatial sound scenes with moving sources for sound event localization and detection,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), Tokyo, Japan, November 2020, pp. 165–169. [Online]. Available: https: //dcase.community/workshop2020/proceedings
[2] A. Politis, S. Adavanne, D. Krause, A. Deleforge, P. Srivastava, and T. Virtanen, “A dataset of dynamic reverberant sound scenes with directional interferers for sound event localization and detection,” in Proceedings of the 6th Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), Barcelona, Spain, November 2021, pp. 125–129. [Online]. Available: https://dcase.community/workshop2021/proceedings
[3] A. Politis, K. Shimada, P. Sudarsanam, S. Adavanne, D. Krause, Y. Koyama, N. Takahashi, S. Takahashi, Y. Mitsufuji, and T. Virtanen, “Starss22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events,” 2022. [Online]. Available: https://arxiv.org/abs/2206.01948
[4] [DCASE2022 Task 3] Synthetic SELD mixtures for baseline training, [Online]. Available: 10.5281/zenodo.6406873
Related Work
[5] SELDnet have adopted a two-branch output format, considering SELD as the performing of two separate sub-tasks from each branch, SED and DOA (SED-DOA) [6, 7] solve the task in a single-branch output through a Cartesian unit vector (proposed as ACCDOA [11]), combining SED and DOA representations, where the zero-vector represents none.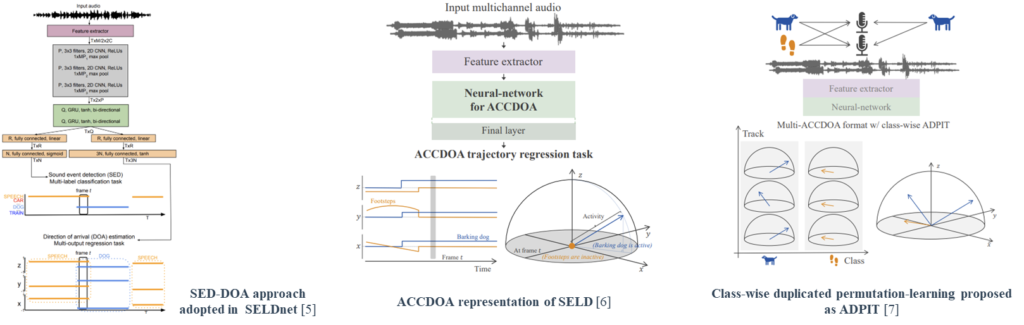
[5] S. Adavanne, A. Politis, J. Nikunen, and T. Virtanen, “Sound event localization and detection of overlapping sources using convolutional recurrent neural networks,” IEEE JSTSP, vol. 13, no. 1, pp. 34–48, 2018.
[6] K. Shimada, Y. Koyama, N. Takahashi, S. Takahashi, and Y. Mitsufuji, “Accdoa: Activity-coupled cartesian direction of arrival representation for sound event localization and detection,” in Proc. of IEEE ICASSP, 2021, pp. 915–919.
[7] K. Shimada, Y. Koyama, S. Takahashi, N. Takahashi, E. Tsunoo, and Y. Mitsufuji, “Multi-accdoa: Localizing and detecting overlapping sounds from the same class with auxiliary duplicating permutation invariant training,” in Proc. of IEEE ICASSP, 2022, pp. 316–320.
Proposed Method
We proposed an angular-distance-based YOLO (AD-YOLO) approach to perform sound event localization and detection (SELD) on a spherical surface. AD-YOLO assigns multilayered responsibilities, which are based on the angular distance from the target events, to predictions according to each estimated direction of arrival. Avoiding the primal format of the event-oriented track output, AD-YOLO addresses the SELD problem in an unknown polyphony environment.
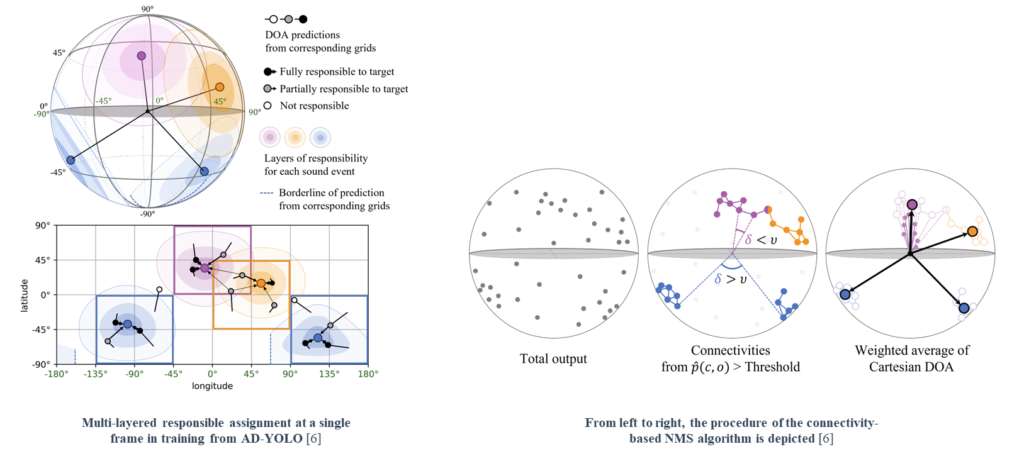
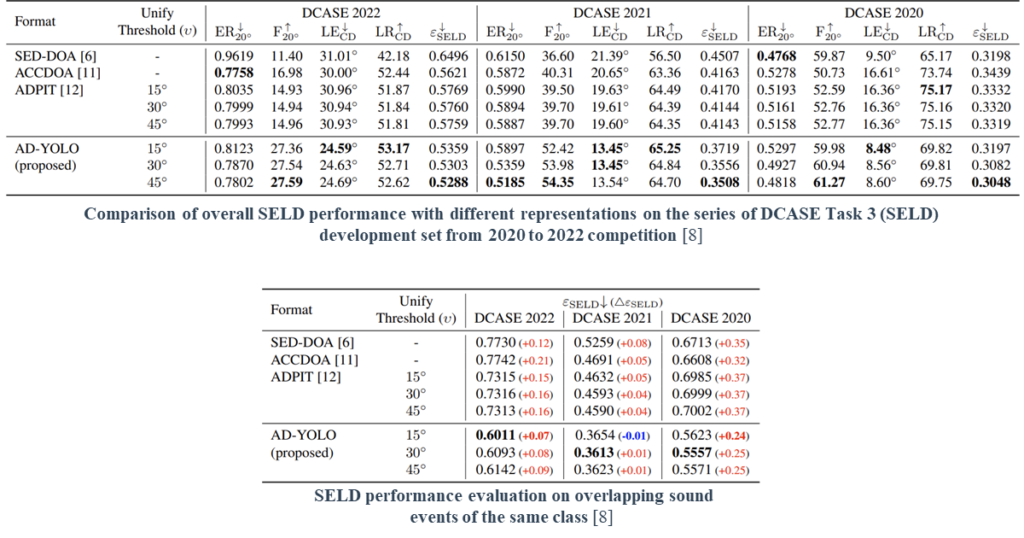
We evaluate several existing formats handling the SELD problem using the same backbone network. The model trained in AD-YOLO format achieves the lowest SELD-error (ε_SELD) from all setups. In particular, AD-YOLO outperformed the other approaches in terms of F_(20°) and LE_CD evaluation metrics.
AD-YOLO proves robustness in class-homogeneous polyphony by the minimum performance degradation (Δε_SELD) compared to the overall evaluation.
MetricGAN-OKD: Multi-Metric Optimization of MetricGAN via Online Knowledge Distillation for Speech Enhancement
Objective
Speech enhancement (SE) involves the improvement of the intelligibility and perceptual quality of human speech in noisy environments. Although recent deep learning-based models have significantly improved SE performance, dissonance continues to exist between the evaluation metrics and the L1 or L2 losses, typically used as the objective function.
To overcome the problems, MetricGAN, which is a GAN-based architecture that utilizes non-differentiable evaluation metrics as objective functions with efficient cost, was proposed. Subsequently, optimization of multiple metrics to improve different metrics representing various aspects of human auditory perception has been attempted.
Although these studies have demonstrated the potential of multi-metric optimization, simultaneous performance improvements are still limited. Therefore, we propose an effective multi-metric optimization method for MetricGAN via online knowledge distillation (MetricGAN-OKD) to improve the performance in terms of all target metrics.
Data
We use the VoiceBank-DEMAND [1] and Harvard Sentences [2] datasets.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
[2] Rothauser, E., “Ieee recommended practice for speech quality measurements”. 1969.
Related Work
MetricGAN is a GAN-based architecture that utilizes non-differentiable evaluation metrics as objective functions with efficient cost.
MetricGAN consists of a surrogate function (discriminator) that learns the behavior of the metric function and a generator that generates enhanced speech based on the guidance of the discriminator.
Online knowledge distillation (OKD), a practical variant of KD, performs mutual learning among student models during the training phase, instead of a one-sided knowledge transfer from a pre-trained teacher network to a student network.
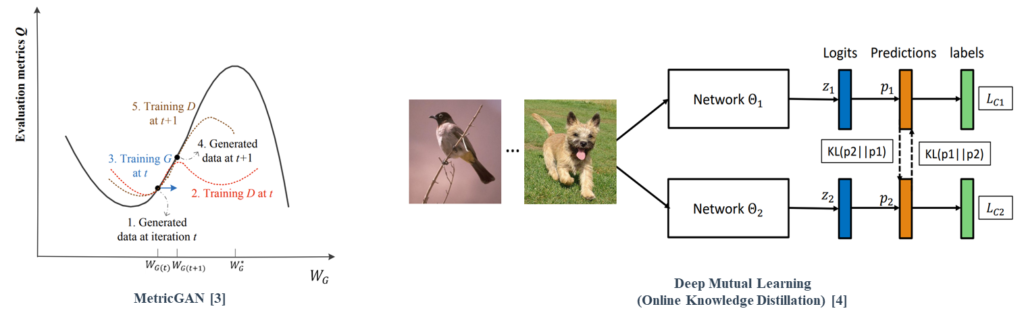
[4] Zhang, Y., et al., “Deep mutual learning”, 2018.
Proposed Method
We propose an effective multi-metric optimization method for MetricGAN via online knowledge distillation (MetricGAN-OKD). To mitigate confusing gradient directions, we design a special OKD learning scheme, which consists of a one-to-one correspondence between generators and target metrics. In particular, each generator learns from the gradient of each discriminator trained using a single target metric for stability. Subsequently, other metrics are improved by transferring knowledge of other generators trained on different metrics to the target generator.
This strategy enables stable multi-metric optimization, where the generator learns the target metric from a single discriminator easily and improves multiple metrics by mimicking other generators.
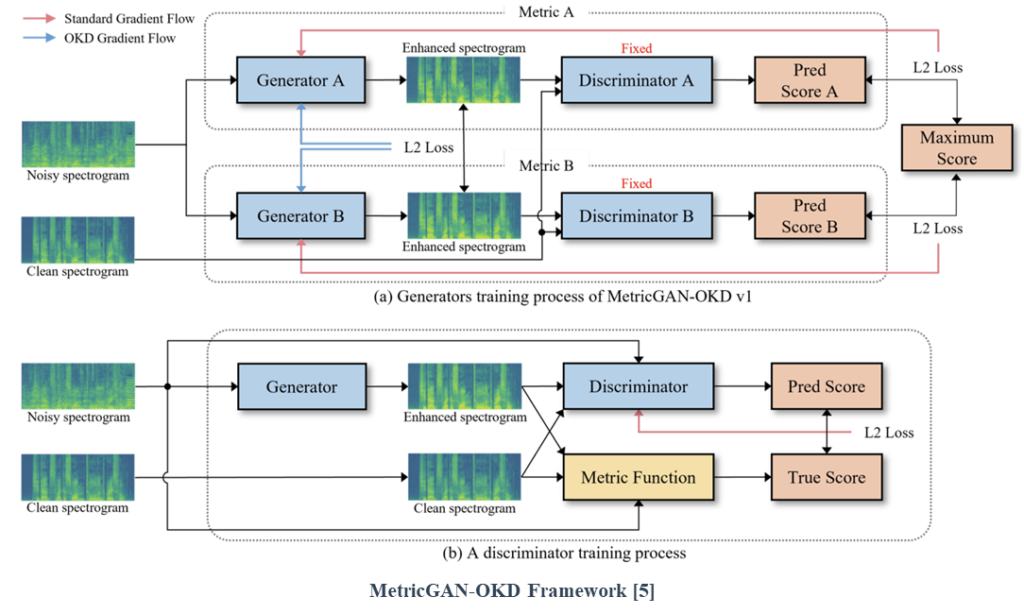
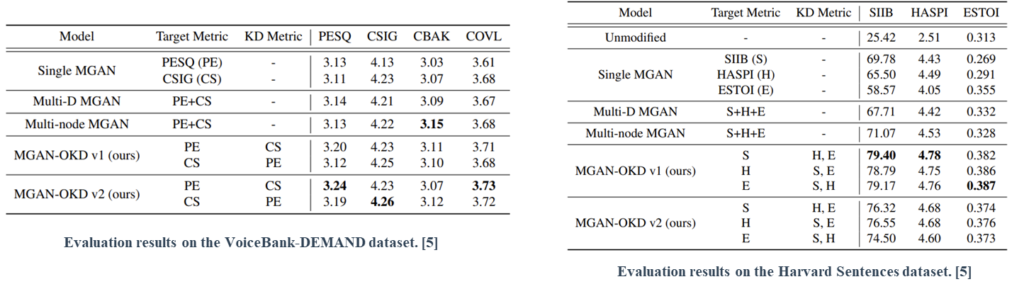
Extensive experiments on SE and LE tasks reveal that the proposed MetricGAN-OKD outperforms existing single- and multi-metric optimization methods significantly.
Besides quantitative evaluation, we explain the success of MetricGAN-OKD in terms of high network generalizability and the correlation between different metrics.
Rethinking Transfer and Auxiliary Learning for improving Audio Captioning Transformer
Objective
Automated audio captioning (AAC) is the automatic generation of contextual descriptions of audio clips. An audio captioning transformer (ACT) that achieved state-of-the-art performance on the AudioCaps dataset was proposed. However, the performance gain of ACT is still limited owing to the following two problems: discrepancy in the patch size and lack of relations between inputs and captions. We propose two strategies to improve the performance of transformer-based networks in AAC.
Data
The AudioCaps dataset [1], the largest audio captioning dataset including approximately 50k audio samples obtained from AudioSet and human-annotated descriptions, is used for validation.
[1] Kim C.D., et al., “Audiocaps: Generating captions for audios in the wild”, 2019
Related Work
Mei et al. [2] proposed a full transformer structure called an audio captioning transformer (ACT) that achieved state-of-the-art performance on the AudioCaps dataset.
One method for strengthening the relationship with local-level labels is to add a keyword estimation branch to the AAC framework [3].
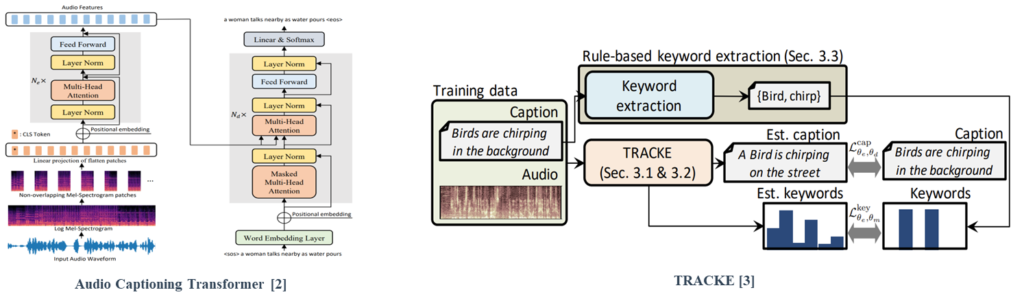
[3] Koizumi, Yuma, et al., “A Transformer-based Audio Captioning Model with Keyword Estimation”, 2020
Proposed Method
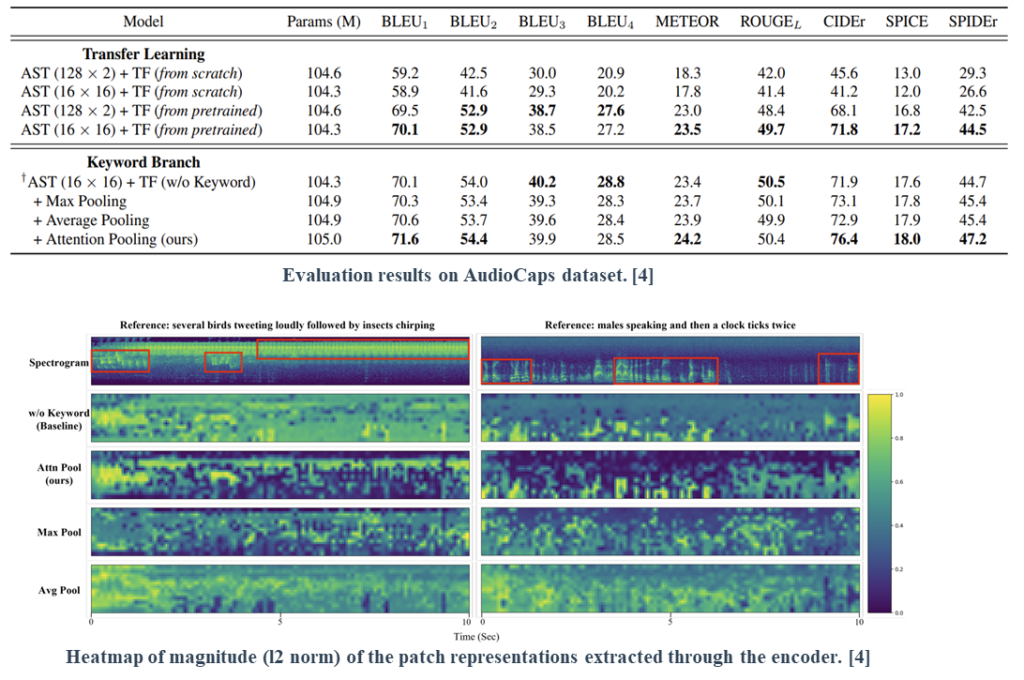
(1) We propose a training strategy that prevents discrepancies resulting from the difference in input patch size between the pretraining and fine-tuning steps.
(2) We suggest a patch-wise keyword estimation branch that utilizes attention-based pooling to adequately detect local-level information.
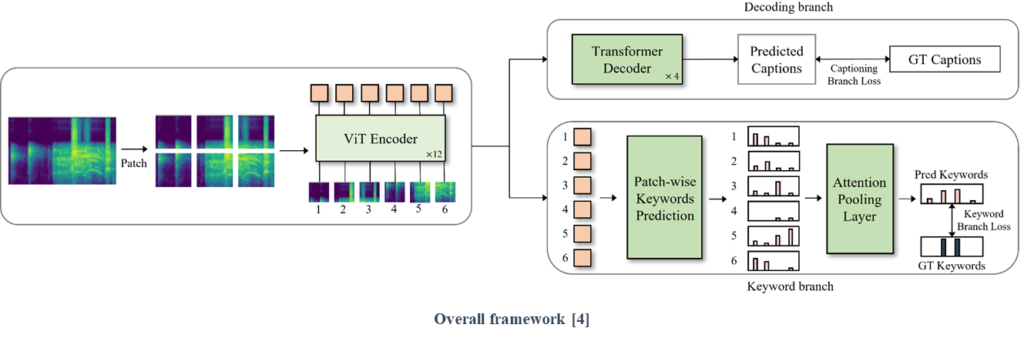
The results on transfer learning suggest that although preserving the frequency-axis information can be crucial, it does not fully leverage the benefits offered by pretrained knowledge.
The results on the keyword branch suggest that the proposed attention-based pooling provides proper information that benefits AAC systems by adequately detecting local-level events.
Finally, we visually verified the effectiveness of the proposed keyword estimation pooling method. The results reveal that the proposed method effectively detects local-level information with minimal false positives compared to other methods.
In‑Vehicle Environment Noise Speech Enhancement Using Lightweight Wave‑U‑Net
Objective
Speech enhancement (SE) is the task of removing background noises to obtain a high quality of clean speech. A potential domain for SE applications is noise removal in in-vehicle environments. To develop the SE model suitable for such environments, we constructed a vehicle noise dataset and trained a lightweight SE network.
Data
We use the custom in-vehicle noise dataset gathered by Hyundai NVH and the custom speech dataset gathered by BRFrame with crowdsourcing.
Related Work
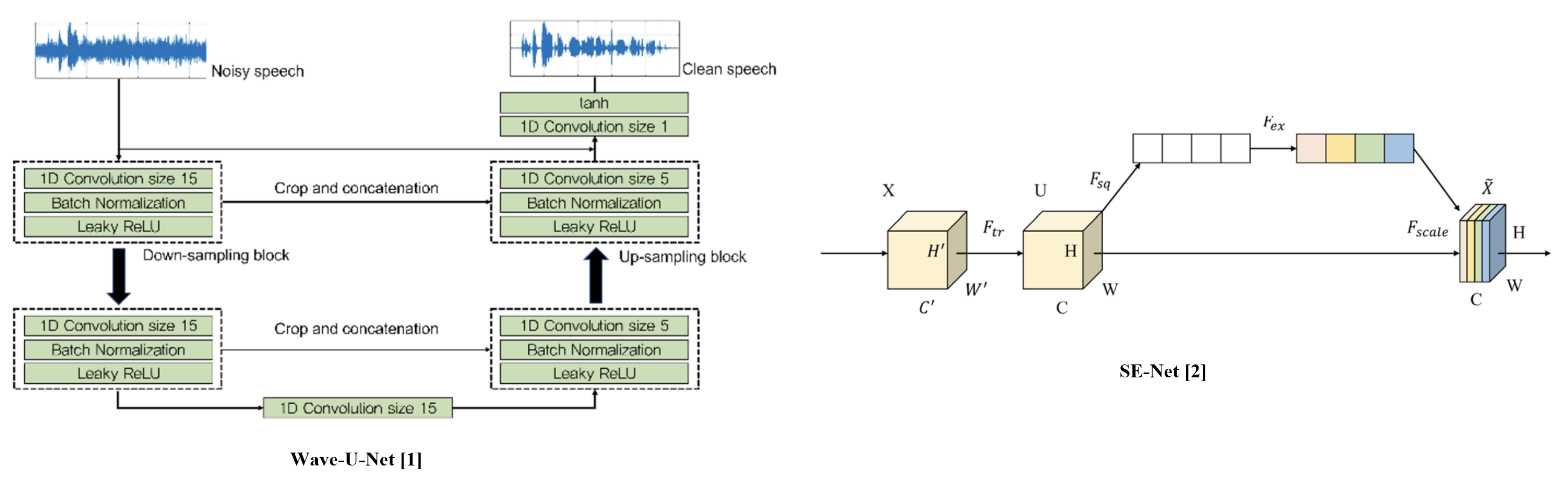
Wave-U-Net [1] is a U-Net based speech enhancement method.
SE-Net [2] is a module that efficiently enhances feature representations.
[2] Hu, Jie, Li Shen, and Gang Sun. “Squeeze-and-excitation networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Proposed Method
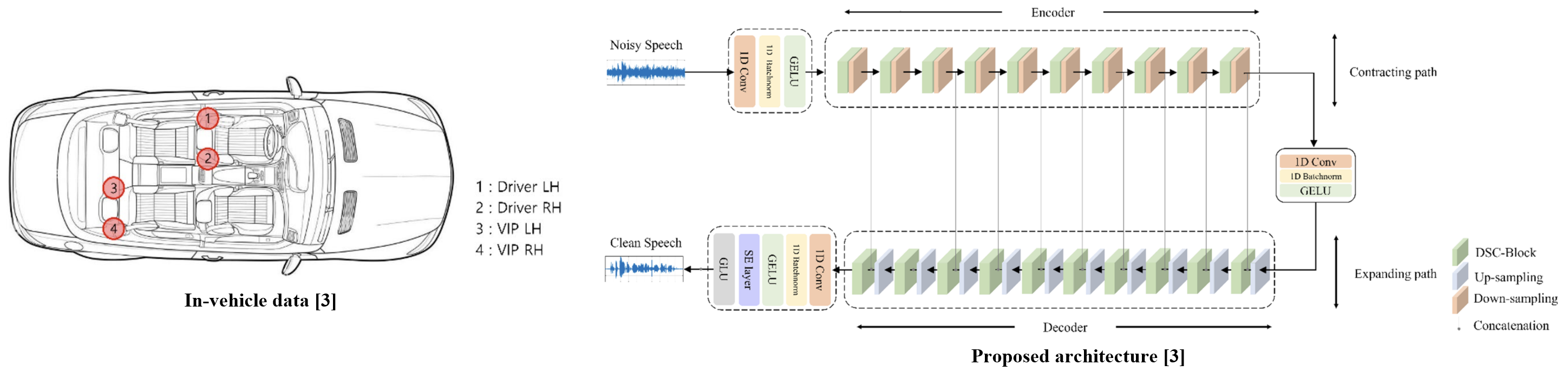
To construct a dataset for in-vehicle noise removal tasks, we collected in-vehicle noise data under various driving conditions. This noise data was then synthesized with speech data for SE model training.
The proposed method is designed as a lightweight model for in-vehicle usage. We introduce a depth-wise separable convolution-based block within a U-Net-based architecture to process information more efficiently.
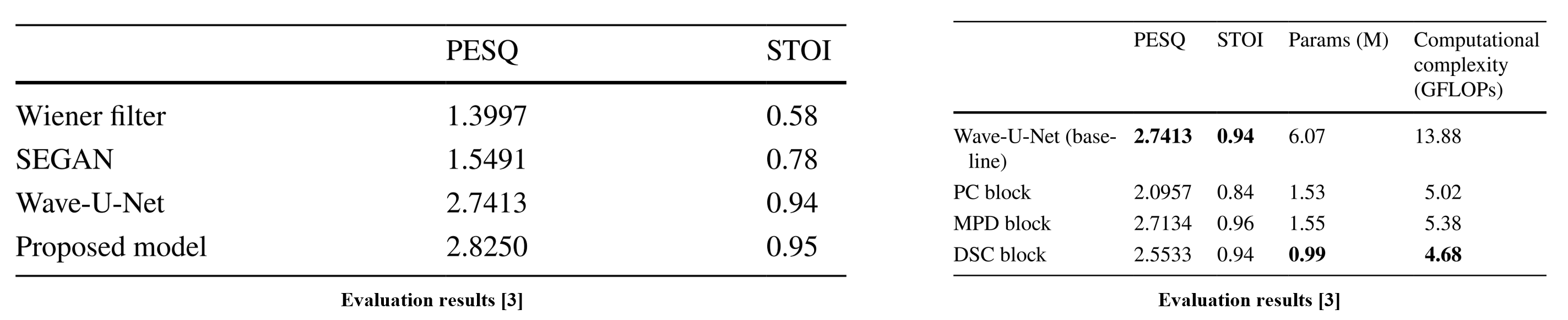
The proposed method achieves higher SE performance than existing approaches. Considering real-time in-vehicle usage, the proposed depth-wise separable convolution-based block demonstrated the most efficient performance in terms of computational efficiency.
Leveraging Non-Causal Knowledge via Cross-Network Knowledge Distillation for Real-Time Speech Enhancement
Objective
Speech enhancement (SE) is the task of removing background noises to obtain a high quality of clean speech. To enhance real-time speech enhancement (SE) while maintaining efficiency, we propose cross-network non-causal knowledge distillation (CNNC-Distill). CNNC-Distill enables knowledge transfer from a non-causal teacher model to a real-time SE student model using feature and output distillation.
Data
We use the VoiceBank-DEMAND dataset [1] which is made by mixing the VoiceBank Corpus and DEMAND noise dataset.
[1] C.Valentini-Botinhao et al., “Noisy speech database for training speech enhancement algorithms and tts models,” 2017.
Related Work
MANNER [2] is a strong SE model can be used for teacher network.
MV-AT [3] proved the importance of feature distillation in SE.

[3] Shin, Wooseok, et al. “Multi-view attention transfer for efficient speech enhancement.” arXiv preprint arXiv:2208.10367 (2022).
Proposed Method
RT-SENet is a lightweight SE network designed for real-time speech enhancement, modified from the MANNER network with causal multi-view attention. CNNC-Distill is a knowledge distillation method that transfers knowledge from a high-performing teacher network to a real-time SE student network. By leveraging feature similarity, it enables effective knowledge transfer under cross-network conditions.
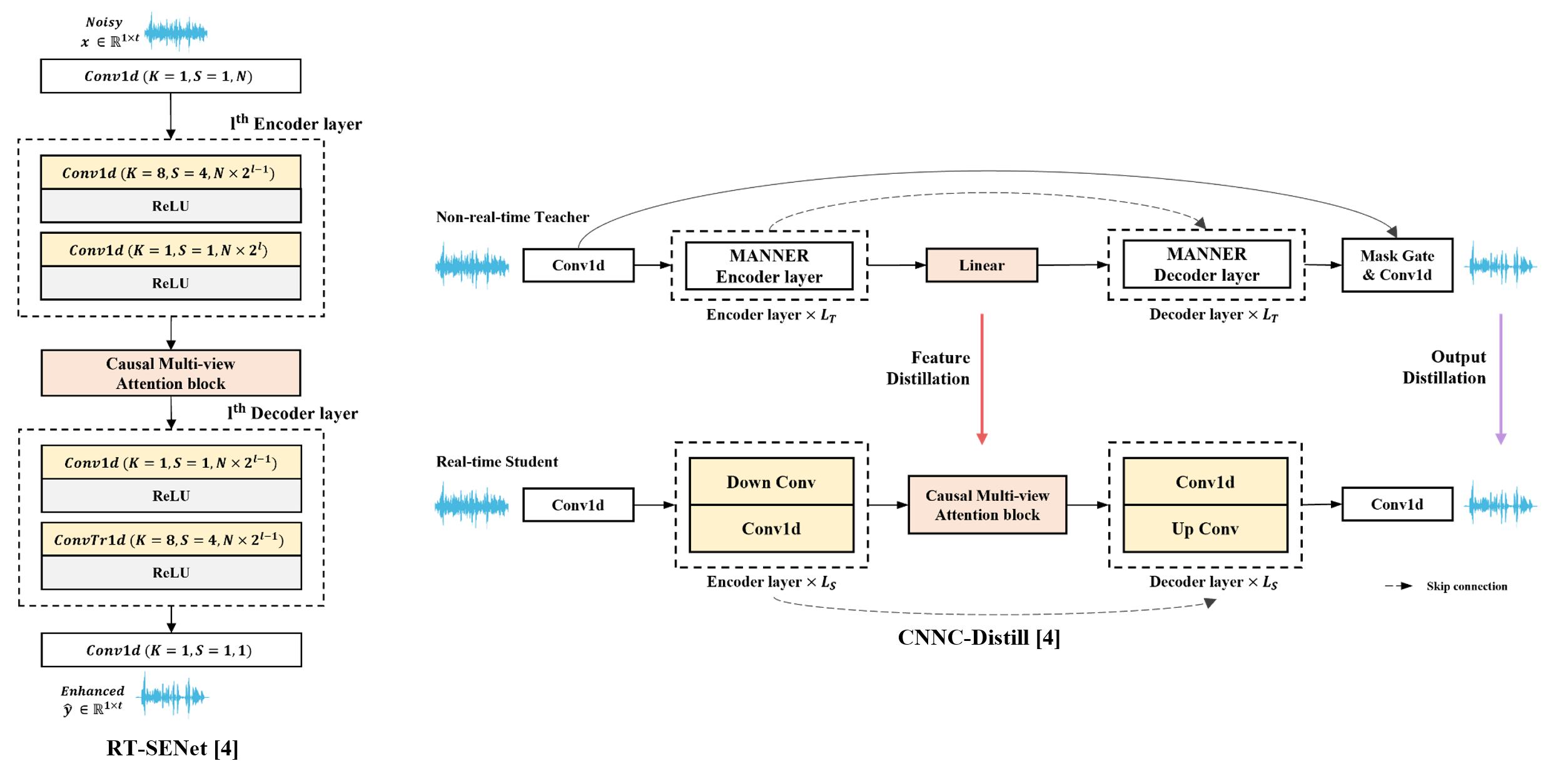
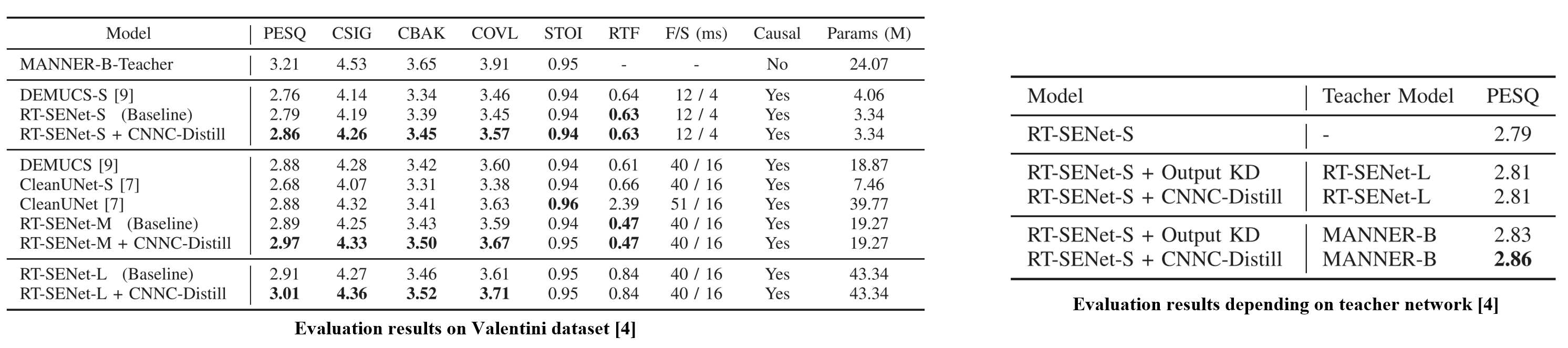
The results (left) show that RT-SENet-(S and M) outperform existing methods in both SE and real-time performance. CNNC-Distill improves SE performance in RT-SENets without affecting real-time operation, with larger models benefiting more from KD. Notably, RT-SENet-S with CNNC-Distill achieves comparable performance to DEMUCS while using significantly fewer inputs and parameters, demonstrating its efficiency.
Real-time SE models are typically simpler, limiting knowledge transfer when using the same network type for KD. Table (right) shows that using a strong non-causal teacher (MANNER-B) outperforms a real-time teacher (RT-SENet-L), maximizing the KD effect. Additionally, CNNC-Distill proves more effective than output KD in cross-network settings, demonstrating its ability to transfer knowledge efficiently.
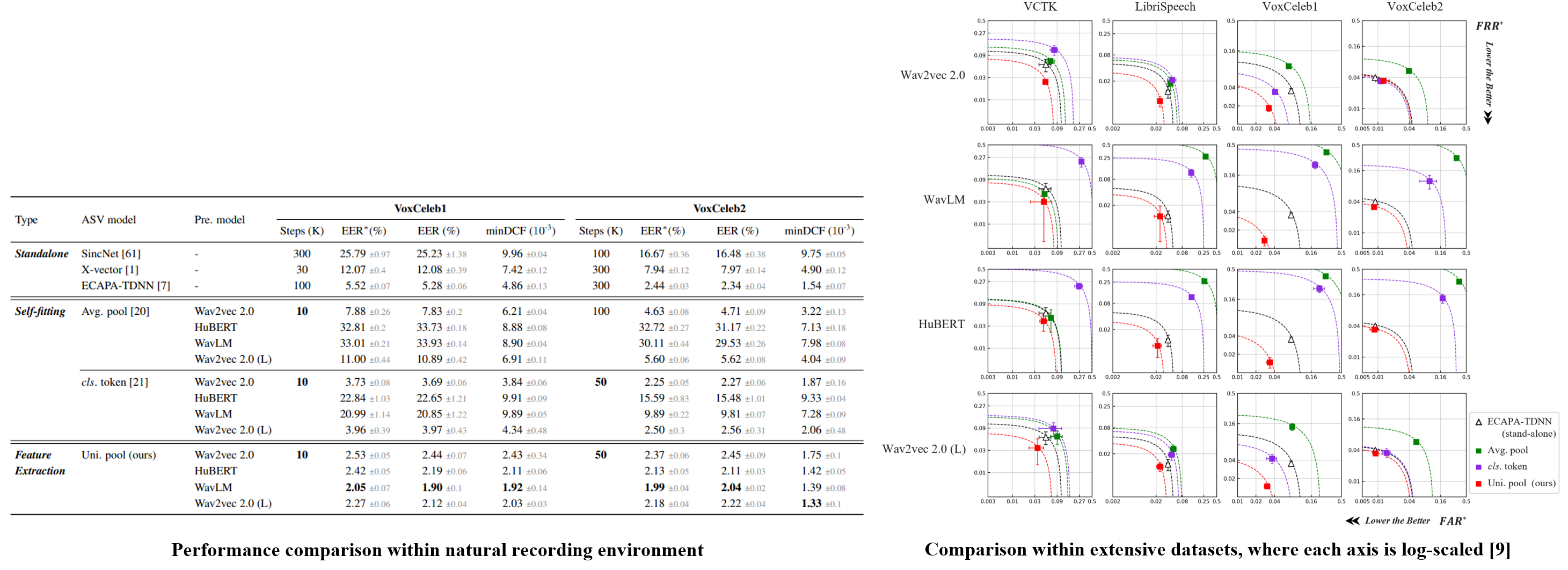
Universal Pooling Method of Multi-layer Features from Pretrained Models for Speaker Verification
Objective
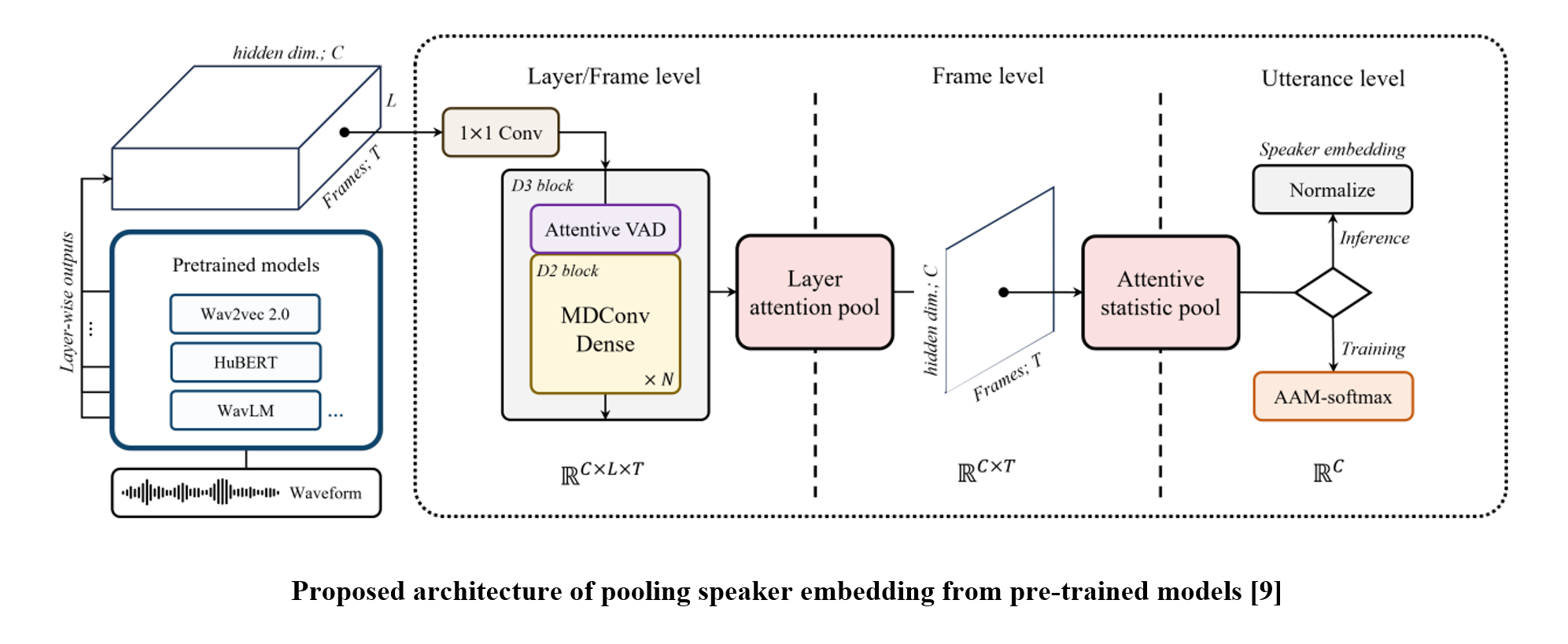
Recent advancements in automatic speaker verification (ASV) studies have been achieved by leveraging large-scale pre-trained networks. In this study, we analyze the approaches toward such a paradigm and underline the significance of interlayer information processing as a result. Accordingly, we present a novel backend model that comprises a layer/frame-level network and two steps of pooling architectures for each layer and frame axis.
Data
We use the CSTR VCTK corpus [1], LibriSpeech [2], and VoxCelebs [3, 4] datasets, diversifying the experimental setups of high-low resource and auditorial recording environments.
[1] J. Yamagishi et al., “CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)”, 2019.
[2] V. Panayotov et al., “LibriSpeech: an ASR corpus based on public domain audio books”, 2015.
[3] A. Nagrani et al., “VoxCeleb: A large-scale speaker identification dataset,” 2017.
[4] J. S. Chung et al., “VoxCeleb2: Deep speaker recognition,”, 2018
Related Work
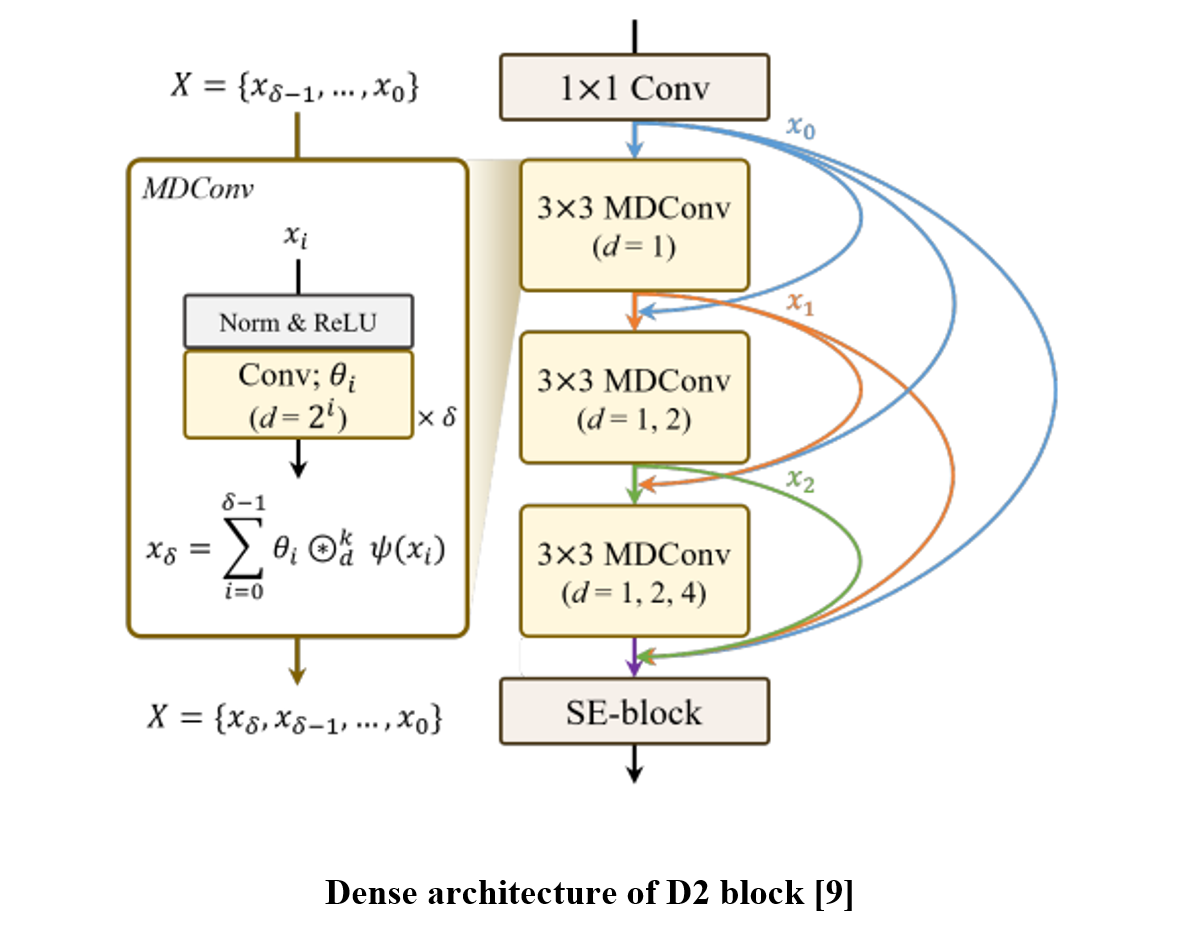
ECAPA-TDNN [5] has been developed based on SE-Res2Net [6] topology for acoustic feature processing. WavLM [7] incorporates ECAPA-TDNN to process the pre-trained model output, which led to achieving state-of-the-art verification performance in the VoxCeleb benchmark. Meanwhile, D3Net [8] proposes an architecture that can avoid the creation of blind spots in dilated-convolutional dense connections.
ChemBERTa [2] predicts masked tokens to acquire SMILES representations, GROVER [3] focuses on predicting masked atom or bond attributes to learn molecular graphs.
MolCLR [4] introduced contrastive learning with graph-based augmentations, enhancing molecular graphs by randomly masking atoms or deleting bonds before computing contrastive loss.
[6] S. Gao et al., “Res2Net: A new multi-scale backbone architecture”, 2019.
[7] S. Chen et al., “WavLM: Large-scale self-supervised pre-training for full stack speech processing” , 2022.
[8] N. Takahashi et al., “Densely connected multi-dilated convolutional networks for dense prediction tasks”, 2021.
[9] J. S. Kim et al., “Universal pooling method of multi-layer features from pretrained models for speaker verification”, 2024.
Proposed Method
In this paper, we propose a backend module that extracts speaker embeddings from pre-trained model output in three steps: layer/frame-level processing network, layer attentive pooling, and attentive statistic pooling. We adopt D3Net to process multiple hidden states of the pre-trained model, hence creating more speaker-representative features from adjacent relationships between layer- and frame-wise information. Then, two attentive poolings follow which are applied for layer and frame-wise aggregation, respectively. The layer-pooling comprises Squeeze-Excitation [10]-based significance scoring and max-pooling, and we follow the temporal aggregation strategy introduced in ECAPA-TDNN.
[10] J. Hu et al., “Squeeze-and-Excitation networks”, 2018.
We conducted experiments on various data environments, leveraging popular pre-trained Transformer networks. We compare the proposed method with two approaches of fine-tuning pre-trained models to perform speaker verification, yet our methodology involves freezing the pre-trained weights since employing the pre-trained model as a feature extractor.
The results show that the proposed backend outperforms the others despite training fewer parameters, demonstrating that the benefits of pretraining can be further maximized given the context of fewer data resources and a natural speech environment such as VoxCeleb 1.
However, the fine-tuning methods showed high sensitivities and were difficult to apply to pre-trained models other than the wav2vec 2.0.